我想在以下標簽中找到內容:
<h4 id="rfq-info-header-id" class="pr-3 mb-3">
RFQ1526090
</h4>
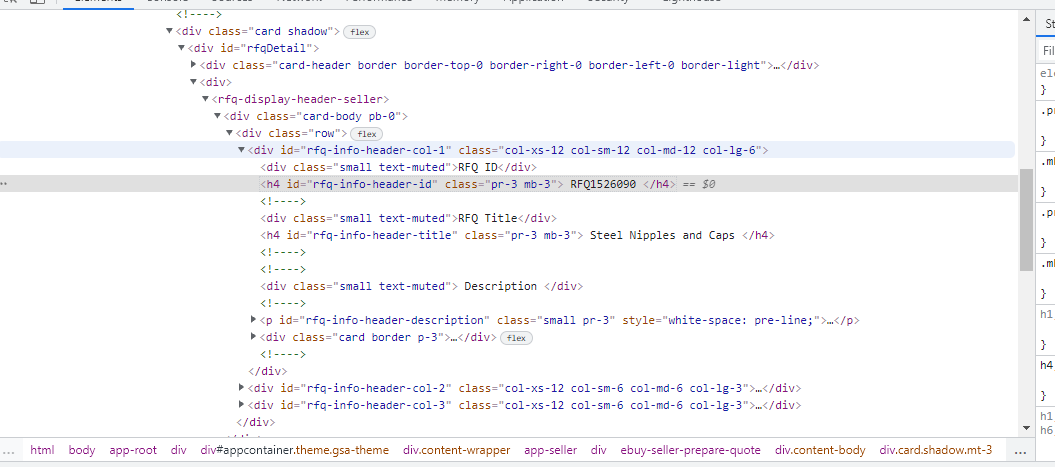
完整代碼:
<rfq-display-header-seller>
<div class="card-body pb-0">
<div class="row">
<div id="rfq-info-header-col-1" class="col-xs-12 col-sm-12 col-md-12 col-lg-6">
<div class="small text-muted">RFQ ID</div>
<h4 id="rfq-info-header-id" class="pr-3 mb-3">
RFQ1526090
</h4>
我試過:
rfq_id = [tag.text.strip() for tag in soup.find_all(name='h4', attrs={'id': 'rfq-info-header-id','class': 'pr-3 mb-3'})]
print(rfq_id)
但這導致空串列[]。這是因為 h4 標簽在許多標簽內嗎?上面代碼中如何簡化提取tag內資料的代碼
uj5u.com熱心網友回復:
我得到的輸出如下:
from bs4 import BeautifulSoup
html_doc="""
<rfq-display-header-seller>
<div >
<div >
<div id="rfq-info-header-col-1" >
<div >RFQ ID</div>
<h4 id="rfq-info-header-id" >
RFQ1526090
</h4>
"""
soup = BeautifulSoup(html_doc, 'html.parser')
# rfq_id = soup.find('h4').text
# print(rfq_id)
rfq_id = [t.get_text(strip=True) for t in soup.find_all('h4')]
print(rfq_id)
輸出:
['RFQ1526090']
僅使用 find 方法輸出:
RFQ1526090
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/329214.html