我有一個資料集,基本上可以簡化為
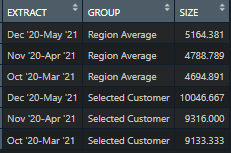
我試圖用ggplot將其繪制成兩條線,Y軸為SIZE,X軸為EXTRACT,代碼如下
。ggplot(data=df, aes(x = EXTRACT, y = SIZE。 group = GROUP))
geom_line(aes(color =GROUP)/span>。 尺寸= 2)
expand_limits(x = 0。 y = 0)
xlab(expression(""))
ylab(expression("Average monthly size"))
scale_y_continuous(expand = c(0。 0)。 標簽=逗號)
主題(axis.text. y = element_text(size = 15),/span>
axis.text. x = element_text(size = 15), axis.title.
axis.title. y = element_text(size = 15), axis.title.
axis.title. x = element_text(size = 15), axis.title。
legend.position = "top",
legend.direction = "horizontal",
legend.title = element_blank(),
legend.spacing.x = 單位(1. 0, 'cm'),
圖例。 text = element_text(size = 15)/span>,
plot.background = element_blank(),
panel.background = element_blank(),
panel.border = element_blank(), panel.grid.major。 y = element_line(colour = "#E6E6E6")。
axis.line.y = element_blank(),
axis.ticks.y = element_blank()
coord_cartesian(clip = "off")
然而,當我這樣做時,X軸并不是按時間順序排序的
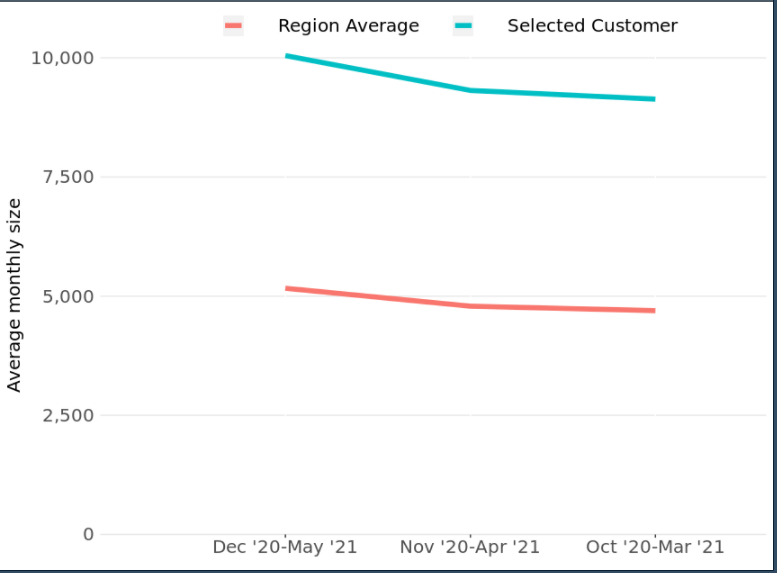
我應該怎么做?
我需要對df做什么,才能使EXTRACT變數正確排序?我希望 "20年10月 "排在 "20年12月 "之前。
創建df的dput在這里
。structure(list(GROUP = c("Dec '20-May '21"/span>, "Nov '20-Apr '21",
"Oct '20-Mar '21", "Dec '20-May '21"。 "Nov '20-Apr '21", "Oct '20-Mar '21"
)。 EXTRACT = c(" Region Average"。 "Region Average", "Region Average","選定的客戶", "選定的客戶", "選定的客戶" "選定的客戶
),SIZE = c(5164。 38064597527, 4788. 78932626798, 4694.89149634116,
10046.66666667, 9316, 9133. 333333333)),行。 names = c(NA,)
-6L)。 組=結構(串列(GROUP =) operator">= c("Dec '20-May '21"/span>, "Nov '20-Apr '21",
"Oct '20-Mar '21"), . rows =結構(list(c(1L。 4L)。 c(2L,/span> 5L
), c(3L。 6L))。 ptype = integer(0)。 class = c("vctrs_list_of"/span>。
"vctrs_vctr"。 "list")),行。 names = c(NA。 -3L)。 class = c("tbl_df"。
"tbl", "data.frame"), . drop = TRUE)。 class = c("grouped_df"。
"tbl_df", "tbl", " data. frame"))
uj5u.com熱心網友回復:
最簡單的方法是通過將EXTRACT變數轉換為一個因子并設定級別來指定順序,例如:
df %>%
mutate(EXTRACT = factor(EXTRACT,)
水平= c("Oct '20-Mar '21",)
"Nov '20-Apr '21",
"Dec '20-May '21")) %>%
ggplot(aes(x =EXTRACT, y = SIZE。 group = GROUP))
geom_line(aes(color =GROUP)/span>。 尺寸= 2)
expand_limits(x = 0。 y = 0)
xlab(expression(""))
ylab(expression("Average monthly size"))
scale_y_continuous(expand = c(0。 0)。 標簽=逗號)
主題(axis.text. y = element_text(size = 15),/span>
axis.text. x = element_text(size = 15), axis.title.
axis.title. y = element_text(size = 15), axis.title.
axis.title. x = element_text(size = 15), axis.title。
legend.position = "top",
legend.direction = "horizontal",
legend.title = element_blank(),
legend.spacing.x = 單位(1. 0, 'cm'),
圖例。 text = element_text(size = 15)/span>,
plot.background = element_blank(),
panel.background = element_blank(),
panel.border = element_blank(), panel.grid.major。 y = element_line(colour = "#E6E6E6")。
axis.line.y = element_blank(),
axis.ticks.y = element_blank()
coord_cartesian(clip = "off")
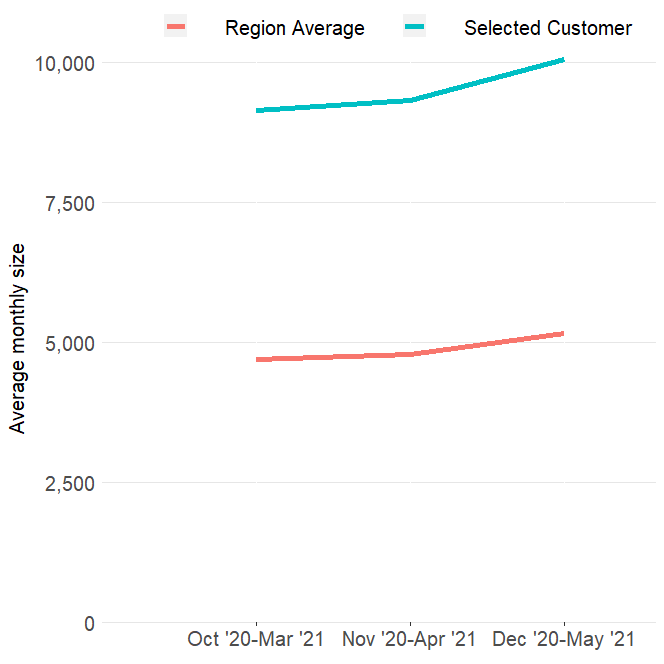
ggplot2通過呼叫factor()自動將字串變數轉換為因子,但當這種情況發生時,它并不總是以最直觀的方式設定水平。
uj5u.com熱心網友回復:
泛化到任意數量的區間就有點復雜了,涉及到stringr和lubridate包的一些函式。至少,我讓它作業的方法是:
用stringr::str_sub()提取區間的開始和結束的年/月部分,用lubridate::dmy()將其轉換為日期,然后首先添加一個任意的日期部分 "01-"(只是為了讓lubridate能夠將字串段決議為日期)
使用lubridate::interval()從現在獨立的開始和結束日期組件列中定義一個時間間隔
使用 dplyr::arrange()根據新的間隔列對資料進行排序
將原來的EXTRACT列轉換為因子,并使用EXTRACT列的unique()值定義新的因子版本的列的級別,現在這些列以升序日期間隔的順序出現(由于步驟3)。
構建圖表。
代碼:
library(tidyverse)
library(lubridate)
df <- df %>%
mutate(EXTRACT_d1 = dmy(str_c("01-"。 str_sub(EXTRACT, 結束= 7)))。 #start date
EXTRACT_d2 = dmy(str_c("01-", str_sub(EXTRACT, 開始= 9)))。 #end date[/span]。
EXTRACT_int = interval(EXTRACT_d1。 EXTRACT_d2)) %> % #define interval
arrange(EXTRACT_int) #sort the data by the interval
df %>%
#now we convert the extract to a factor using the unique values after sorting.
#基于區間列的。
mutate(EXTRACT = factor(EXTRACT, 水平=獨特(so_df$EXTRACT))) %> %
ggplot(aes(x = EXTRACT, y = SIZE。 group = GROUP))
geom_line(aes(color =GROUP)/span>。 大小= 2)
expand_limits(x = 0。 y = 0)
xlab(expression(""))
ylab(expression("Average monthly size"))
scale_y_continuous(expand = c(0。 0)。 標簽=逗號)
主題(axis.text. y = element_text(size = 15),/span>
axis.text. x = element_text(size = 15), axis.title.
axis.title. y = element_text(size = 15), axis.title.
axis.title. x = element_text(size = 15), axis.title。
legend.position = "top",
legend.direction = "horizontal",
legend.title = element_blank(),
legend.spacing.x = 單位(1. 0, 'cm'),
圖例。 text = element_text(size = 15)/span>,
plot.background = element_blank(),
panel.background = element_blank(),
panel.border = element_blank(), panel.grid.major。 y = element_line(colour = "#E6E6E6")。
axis.line.y = element_blank(),
axis.ticks.y = element_blank()
coord_cartesian(clip = "off")
uj5u.com熱心網友回復:
如果你想動態地分配因子的級別,你可以這樣做-
df$GROUP < -因素(df$GROUP。 unique(df$GROUP[order(as. Date()
sub('-. *', '-01'。 df$GROUP)。 "%b '%y-%d"))]))
levels(df$GROUP)
#[1] "Oct '20-Mar '21" "Nov '20-Apr '21" "Dec '20-May '21"/span>
這里的邏輯是,我們洗掉-之后的所有內容,并添加01作為一個任意的日期,使用as.Date和order轉換為日期物件,以獲得根據日期的正確順序。
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/330202.html
標籤: