我確實有以下別名,以向我顯示任何給定檔案的提交歷史:
file-history = log --follow --date-order --date=short -C
它運行良好,但從不顯示“合并提交”,例如,檔案可能已在我們合并到 main 的分支中被修改。
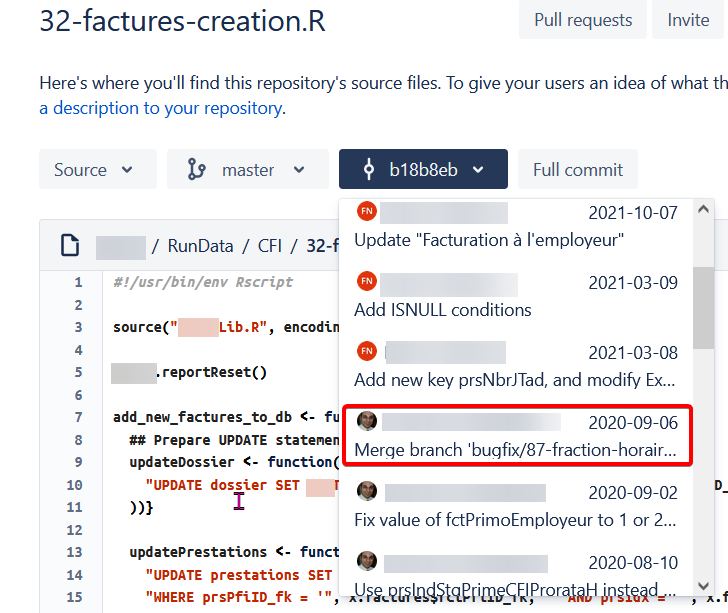
解決方案是添加選項-m,但隨后它會顯示許多、許多、許多合并提交,其中大多數似乎與檔案的提交歷史無關。
撰寫這樣的別名以使其行為正確的正確方法是什么(例如在 BitBucket 中,就此而言):顯示確實更改檔案的所有提交,并且僅顯示那些提交?
額外的資訊 -
使用-m顯示太多提交;具體來說:
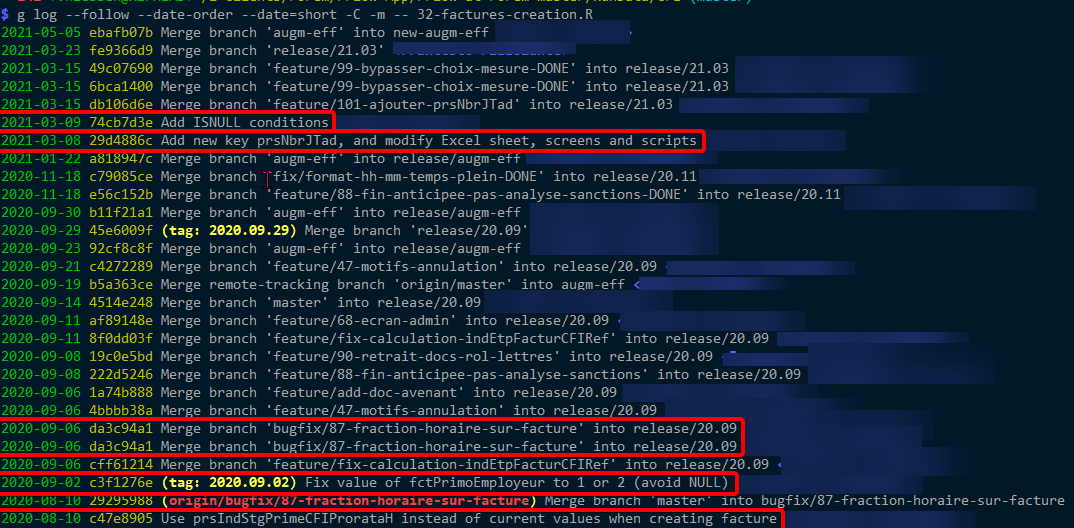
(在紅色矩形中,我應該看到什么......這就是 BitBucket 顯示的......)
(順便說一句,我不明白為什么提交 da3c94a1 是重復的。)
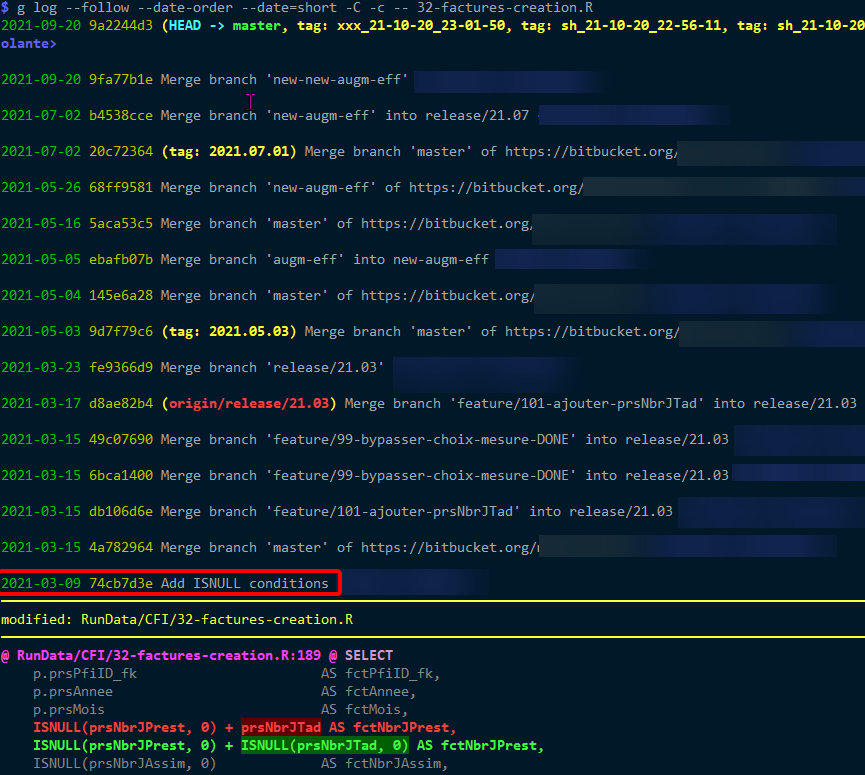
Using -c shows even much more commits (the first commit that should be reported being in the bottom of the page) and displays the diffs (what I don't want to see here):
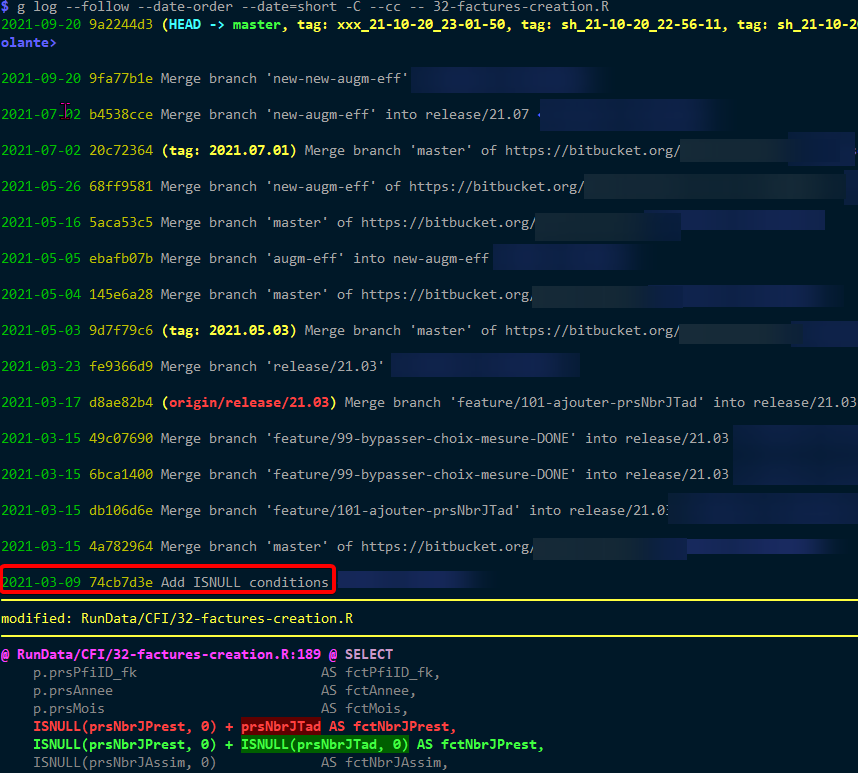
Same results for --cc:
And --first-parent shows weird results (as I don't see at all the commits I'm interested in):
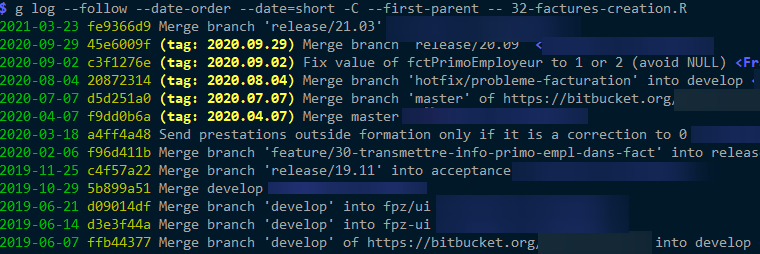
NEW EXTRA INFORMATION --
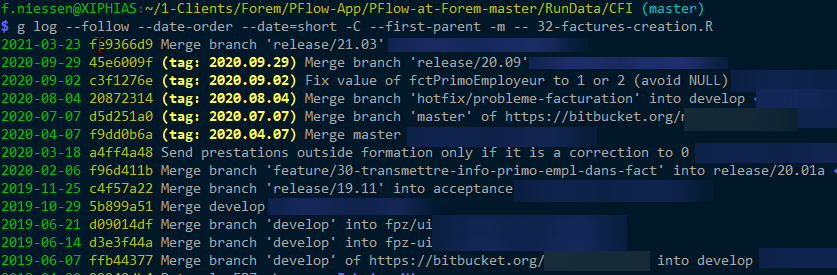
And, with --first-parent -m, no change:
uj5u.com熱心網友回復:
但從不顯示“合并提交”,而檔案可能已在我們合并到主的分支中被修改,例如
如果您打算這樣做,請添加--first-parent -m(正如我在評論中看到的@torek 所建議的那樣)。不僅僅是-m,它本身更像是一種僅適用于絕望案件的取證工具。
這里發生的事情是,沒有--first-parentGit 已經將在做出這些更改的提交中向您展示這些更改。合并不會引入任何新的變化。如果 Git 向您展示了合并差異,它最終會至少向您展示所有內容兩次。
這就是為什么避免在合并提交中引入新作業或更正是一個好主意的原因。該行為使得無法推斷合并的作用。合并沖突檢測和解決已經是無限的。Git 和任何 vcs 一樣好,而且比我認為的地球上所有其他 vcs 都要好,但它永遠不可能是完美的。假設串列中的一個值必須與剩余值的總和有某種數學關系,兩個分支上的變化都保留了這種關系,但是當組合起來時,這種關系就被破壞了。或任何其他此類條件:將代碼添加到依賴于現有編譯值的一個分支中,但另一個分支使其可由用戶配置。想一想那個。
因此--first-parent -m -p,即使是合并,也會向您顯示差異,但只有合并分支和沖突解決方案引入的更改,在主線中較早完成的作業將顯示在引入它的提交中。
uj5u.com熱心網友回復:
*您專門詢問了在輸出中查找合并提交的問題。我覺得現在的基礎上,根據問題的所有評論,這是一個錯誤:你不希望合并提交所有,即使他們這樣做改變有問題的檔案。您想要的是停止git log執行 History Simplification。
為此,只需將--full-history標志提供給git log. 但了解這個標志的含義也很重要:特別是,我認為你不明白 Git 在這里試圖向你展示什么(這并不奇怪,因為 Git 檔案在解釋 Git 試圖做什么方面做得很糟糕首先)。
去啊哈!片刻,我們必須從簡單回顧一下可能已經知道但可能已經塞進你的腦海并忘記的東西開始:
- Git 是關于commits 的,每個 commit 都是一個編號的物體,通過它丑陋的隨機哈希 ID 找到;
- 每個提交存盤一個快照和一些元資料,元資料包括一些早期提交的原始哈希 ID;和
- 大多數提交只存盤一個以前的提交哈希 ID。
這使得提交形成簡單的向后看的鏈。讓我們使用簡單的大寫字母作為假裝的哈希 ID,并按順序分配它們以使我們微不足道的人腦更容易,并假設我們有一個以哈希 ID 提交結束的存盤庫H,如下所示:
A <-B <-C ... <-F <-G <-H
也就是說,此存盤庫中的最后一次(因此也是最新的)提交是 commit H。CommitH存盤每個檔案的完整快照和一個向后指向的箭頭(實際上是早期 commit 的真實提交哈希 ID)G。
使用存盤在 中的快照G 和存盤在 中的快照H,Git 可以比較這兩個快照。不管這里有什么不同,那些是我們改變的檔案;通過比較這些檔案,Git 可以生成一個差異,顯示我們更改的特定行,或者 Git 可以列出我們更改的檔案。這很簡單,但它確實意味著要知道 中發生了什么變化H,Git 必須提取兩個快照:一個來自H,還有一個來自其父G。
該git log命令將對 執行此操作H,然后后退一步到G。現在,要查看 中的更改G,Git 必須將其父項F的快照與 中的快照進行比較G。這足以知道G.
現在又git log可以退步了。這會根據需要重復,直到我們一直運行到第一次提交,根據定義,它只是將它擁有的所有檔案添加到其快照中。在 root commit 之前沒有任何東西A,所以一切都是新的,現在git log可以停止了。
合并混亂
這對于這些簡單的線性鏈很有效,但是 Git 的提交并不總是簡單的線性鏈。假設我們有我們的 simple-so-far 存盤庫,其中只有一個分支命名main并以 結束H,但現在我們創建一些新分支名稱,在這些新分支上進行一些提交,并準備合并它們:
I--J <-- br1
/
...--G--H
\
K--L <-- br2
提交通過H在所有分支上進行,而提交I-J僅在br1并且提交K-L僅在 上br2。git log在這一點上使用向我們展示了J、 then I、 then H、 thenG等,從br1的最新提交向后箭頭;或者,它向我們顯示L、 then K、 then H、 thenG等,從br2的最新提交向后顯示。
Git 當然會以通常的方式找到檔案“更改”:比較 in Lvs 中的快照K,或者KvsH等。由于每個提交都只有一個父提交,所以這很好用。
Once we merge, however, we have a problem. The merge itself works by:
- comparing
HvsJto see what changed onbr1; - comparing
HvsLto see what changed onbr2; and - combining these changes, and applying the combined changes to the snapshot in
H.
This keeps "our" changes on br1 and adds "their" changes on br2, if that's the direction we're doing the merge. Or, it keeps "our" changes on br2 and adds "their" changes on br1. Either way the result is the same (except for conflict resolutions, if any, which depend on how we choose to resolve the conflict).
We now have Git make a new merge commit, M, which has:
- one snapshot, but
- two parents.
It looks like this:
I--J
/ \
...--G--H M
\ /
K--L
I have taken the labels away because at this point we often do that: M is now the latest main commit instead, and when we add another new commit N it just extends main:
I--J
/ \
...--G--H M--N
\ /
K--L
N is an ordinary single parent commit as usual, so the niceness of comparing the snapshot in M vs that in N works as usual, finding the changes as usual.
Merge commit M, on the other hand, is quite thorny. How should git log show the changes? Changes, in Git, require that we look at "the" parent commit. But M does not have the parent. M has two parents, J and L. Which one should we use?
The -m flag means run two separate git diff operations, one against J, and then a second one against L. That way we'll see what changed vs J, i.e., what we brought in via K-L, and then we'll also see what changed vs L, i.e., what we brought in via I-J.
Adding --first-parent means follow just one of these lines so that at M we'll see, e.g., what happened in K-L, but then we won't look at K or L at all any more. We'll just move back to J. The effect is that Git pretends, for the duration of -m --first-parent, that the commit graph looks like this:
...--G--H--I--J--M--N
This is, more or less, literally what you asked for—but it's not what Bitbucket is doing.
Undoing the merge mess several other ways
We can, if we so choose, have git log compare M vs both J and L—i.e., make two separate git diffs—but then discard most of the results of these two diffs. Git has two different "combined diff" modes, which you can get with -c or --cc.
Unfortunately, neither one does what you want. They're also rather difficult to explain (and I still don't really know what the true difference between the two is, though they are demonstrably different: I can show some differences, but I don't know what the goals are, of the two different options).
History Simplification
The real key here though is this. Suppose there is some file F that appears in all three commits M, J, and L. Remember, this particular snippet of our picture looks like this:
I--J
/ \
...--H M
\ /
K--L
- If F is the same in all three commits, it's not "interesting" in this merge. Nobody made any changes to it.
- If F matches in
JvsM, but is different inLvsM, then "something interesting" happened. The same is true if F matches inLvsM, but is different inJvsM.
What git log does in most cases here is to try to find out about the final state of the file. Why does file F look the way it does in M? But think about this: If F differs in J vs M but matches in L vs M, then anything we did to the file along the top row is irrelevant! We threw away the top-row copy of file F and kept only the bottom-row copy.
So, if you're asking git log about file F at this point, git log simply does not bother to look at commits I-J. It follows only the bottom row.
On the other hand, if F exactly matches in J-vs-M but differs in L-vs-M, git log -- F will follow only the top row, because we threw away anything that came out of the bottom row.
This is History Simplification in a nutshell. The git log command will, at merge points, throw out one "side" of the merge entirely if it can. If the file(s) we care about match one side, that's the side git log will pick. If the file(s) we care about match all sides of the merge, git log will pick one side at random, and follow that side.
This means git log never even looks at any of the files on the "other side" of the merge so you will not see any of those commits in the git log output. The program is assuming that since the merge took "one side" over the other, that's the interesting side, and everything that might show up on the other is irrelevant dross, to be discarded.
This is sometimes what you want
The reason git log does this kind of history simplification is that it assumes your goal is to know why the file looks the way it does in the latest version. Any irrelevant-dross-commits that got throw out don't matter, so let's not even look at them.
When that's what you want, that's what you want! But sometimes you want to know: I'm sure I changed this myself, where was that? or something similar. Here, you must tell git log not to do history simplification at all. The flag for this is --full-history. There are other history simplification flags, so that you can control the simplification: it is useful after all. Read through the git log documentation History Simplification section to see them.
It's worth adding one more point here, having to do with so-called evil merges (see Evil merges in git?). We could have:
...--J
\
M
/
...--L
where the snapshot files in M are utterly unrelated to the files in either J or L. More commonly, we might have some file in M that has a change hidden away in it that does not come from the top or bottom rows at all, but rather was produced due to the fact that there were conflicts and/or the combined changes didn't work.
If the "hidden" change is due to conflicts, that's not so bad, but if someone stuck in an unrelated fix, we have an issue. In particular, git log by default does not display merge commits at all when using git log -- path. It assumes that anything interesting that will show up from the path argument will be found on either the top or bottom row, in a commit before the merge. But an "evil merge" might introduce an "interesting change" that isn't in either row, and this is when you must force git log to look at merge commits, using -m, or -c, or --cc.
What Bitbucket do with their software is of course up to them. We don't know if they are currently using --full-history --cc for instance. We don't know whether, in future, they might change the internal git log options. So there's no real point in trying to make your command-line git log output exactly match your Bitbucket view output, as the latter is not under your control in the first place. If you are going to use git log, then, concentrate instead on knowing what git log is doing and how to make that work to your advantage.
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/334182.html
標籤:git logging merge commit history
上一篇:在另一個提交后恢復提交