作者簡介
- 王振華,趣頭條大資料總監,趣頭條大資料負責人,
- 王海勝,趣頭條大資料工程師,10 年互聯網作業經驗,曾在 eBay、唯品會等公司從事大資料開發相關作業,有豐富的大資料落地經驗,
- 高昌健,Juicedata 解決方案架構師,十年互聯網行業從業經歷,曾在知乎、即刻、小紅書多個團隊擔任架構師職位,專注于分布式系統、大資料、AI 領域的技術研究,
背景
趣頭條大資料平臺目前有一個近千節點的 HDFS 集群,承載著存盤最近幾個月熱資料的功能,每日新增資料達到了百 TB 規模,日常的 ETL 和 ad-hoc 任務都會依賴這個 HDFS 集群,導致集群負載持續攀升,特別是 ad-hoc 任務,因為趣頭條的業務模式需要頻繁查詢最新的資料,每天大量的 ad-hoc 查詢請求進一步加重了 HDFS 集群的壓力,也影響了 ad-hoc 查詢的性能,長尾現象明顯,集群負載高居不下,對很多業務組件的穩定性也造成了影響,如 Flink 任務 checkpoint 失敗、Spark 任務 executor 丟失等,
因此需要一種方案使得 ad-hoc 查詢盡量不依賴 HDFS 集群的資料,一方面可以降低 HDFS 集群的整體壓力,保障日常 ETL 任務的穩定性,另一方面也能減少 ad-hoc 查詢耗時的波動,優化長尾現象,
方案設計
趣頭條的 ad-hoc 查詢主要依靠 Presto 計算引擎,JuiceFS 的 Hadoop SDK 可以無縫集成到 Presto 中,無需改動任何代碼,以不侵入業務的方式自動分析每一個查詢,將需要頻繁讀取的資料自動從 HDFS 拷貝至 JuiceFS,后續的 ad-hoc 查詢就可以直接獲取 JuiceFS 上已有的快取資料,避免對 HDFS 產生請求,從而降低 HDFS 集群壓力,
另外由于 Presto 集群是部署在 Kubernetes 上,有彈性伸縮集群的需求,因此需要能夠將快取資料持久化,如果使用獨立的 HDFS 或者某些快取方案的話,成本會很高,此時 OSS 成為最理想的選擇,
整體方案設計如下圖所示,綠色部分表示 JuiceFS 的組件,主要包含兩部分:JuiceFS 元資料服務(下圖中的 JuiceFS Cluster)及 JuiceFS Hadoop SDK(下圖與 Presto worker 關聯的組件),
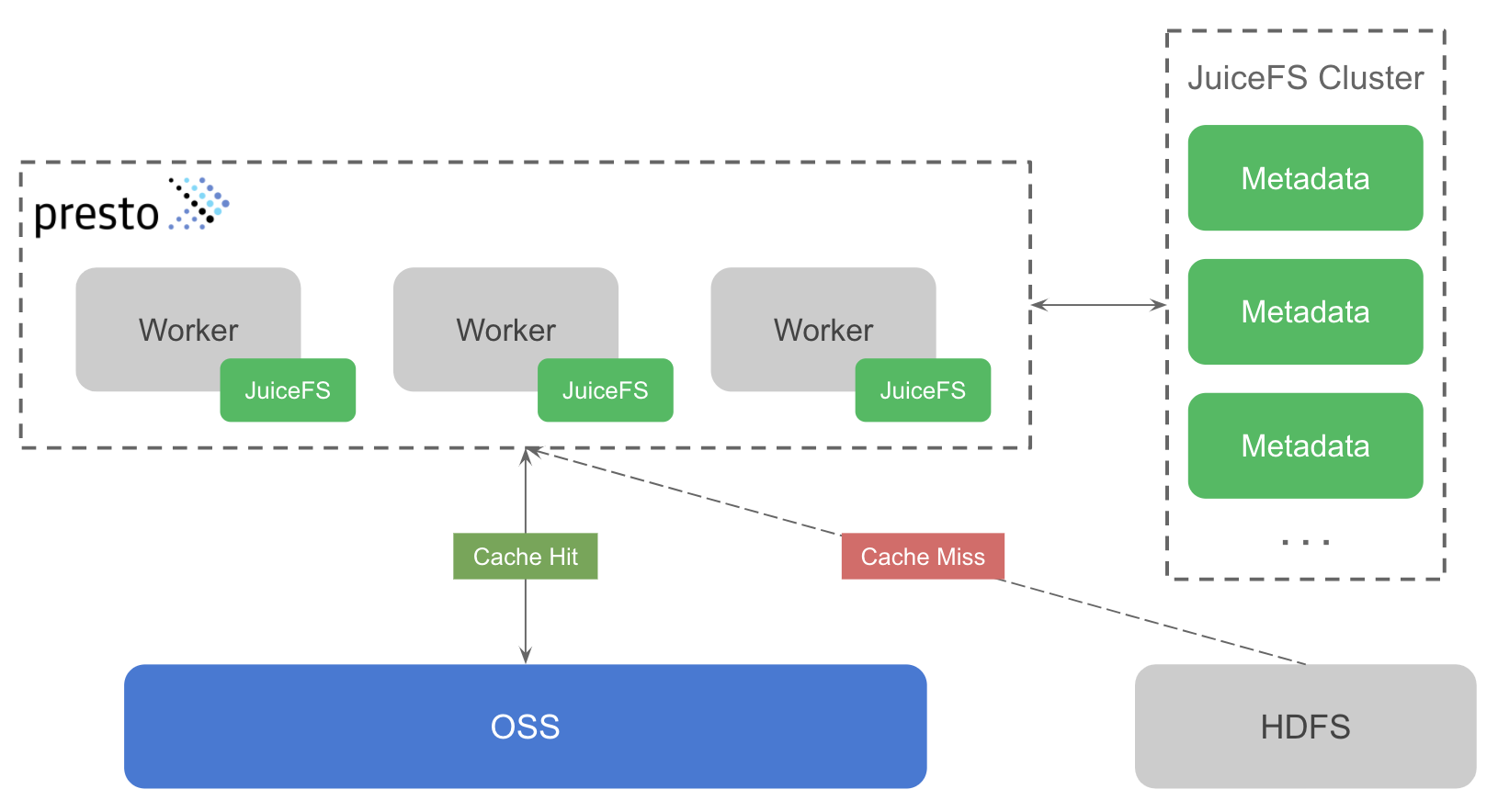
JuiceFS 元資料服務用于管理檔案系統中所有檔案的元資訊,如檔案名、目錄結構、檔案大小、修改時間等,元資料服務是一個分布式集群,基于 Raft 一致性協議,保證元資料強一致性的同時,還能確保集群的可用性,
JuiceFS Hadoop SDK(以下簡稱 SDK)是一個客戶端庫,可以無縫集成到所有 Hadoop 生態組件中,這里的方案即是集成到 Presto worker 中,SDK 支持多種使用模式,既可以替代 HDFS 將 JuiceFS 作為大資料平臺的底層存盤,也可以作為 HDFS 的快取系統,這個方案使用的便是后一種模式,SDK 支持在不改動 Hive Metastore 的前提下,將 HDFS 中的資料透明快取到 JuiceFS 中,ad-hoc 查詢的資料如果命中快取將不再需要請求 HDFS,同時 SDK 還能保證 HDFS 與 JuiceFS 間資料的一致性,也就是說當 HDFS 中的資料發生變更時,JuiceFS 這邊的快取資料也能同步更新,不會對業務造成影響,這是通過比較 HDFS 與 JuiceFS 中檔案的修改時間(mtime)來實作的,因為 JuiceFS 實作了完整的檔案系統功能,所以檔案具有 mtime 這個屬性,通過比較 mtime 保證了快取資料的一致性,
為了防止快取占用過多空間,需要定期清理快取資料,JuiceFS 支持根據檔案的訪問時間(atime)來清理 N 天前的資料,之所以選擇用 atime 是為了確保那些經常被訪問的資料不會被誤洗掉,需要注意的是,很多檔案系統為了保證性能都不會實時更新 atime,例如 HDFS 是通過設定 dfs.namenode.accesstime.precision 來控制更新 atime 的時間間隔,默認是最快 1 小時更新 1 次,快取的建立也有一定的規則,會結合檔案的 atime、mtime 和大小這些屬性來決定是否快取,避免快取一些不必要的資料,
測驗方案
為了驗證以上方案的整體效果,包括但不限于穩定性、性能、HDFS 集群的負載等,我們將測驗流程分為了多個階段,每個階段負責收集及驗證不同的指標,不同階段之間可能也會進行資料的橫向比較,
測驗結果
HDFS 集群負載
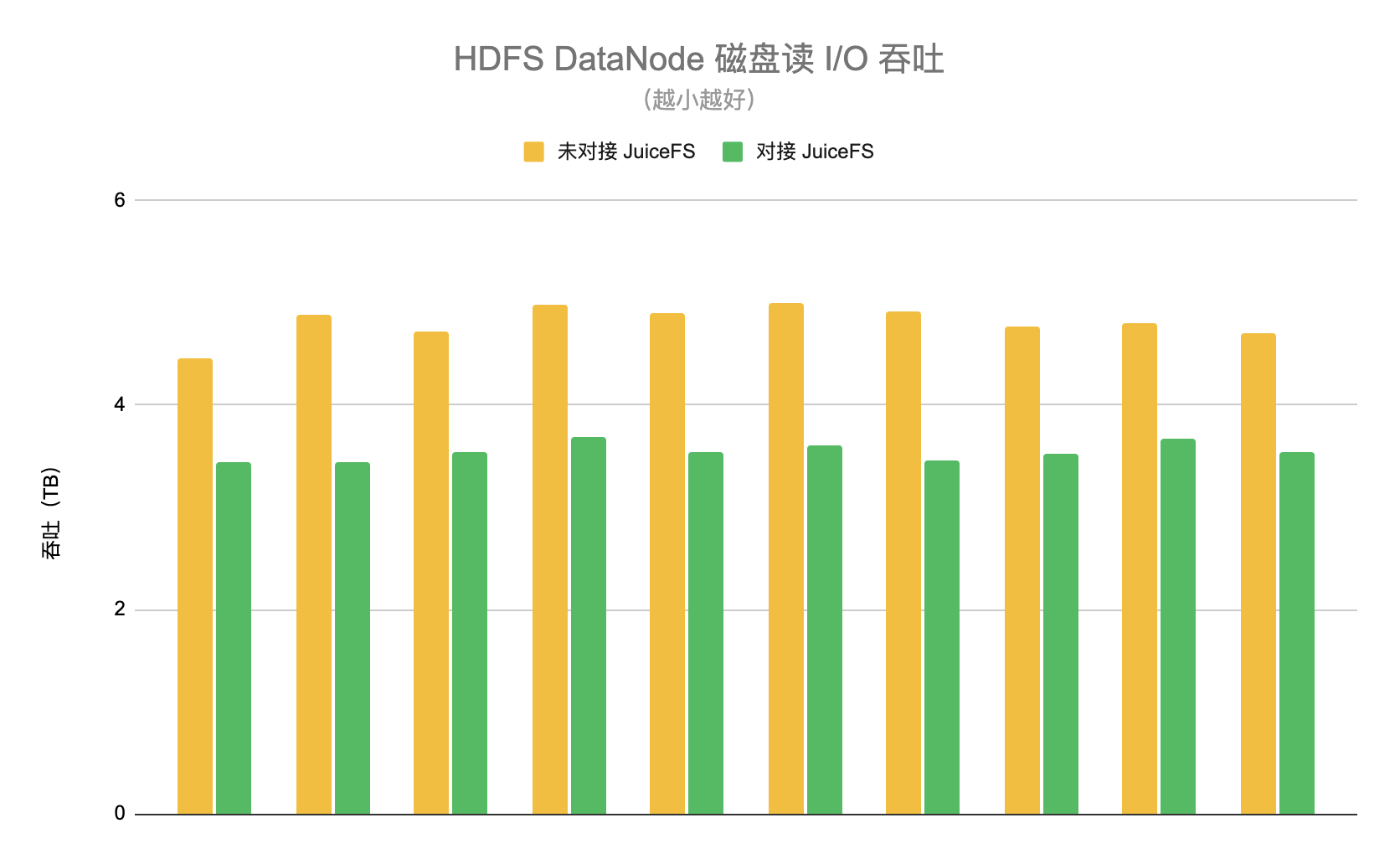
我們設計了兩個階段分別開啟和關閉 JuiceFS 的功能,在開啟階段隨機選取 10 臺 HDFS DataNode,統計這一階段每臺 DataNode 平均每天的磁盤讀 I/O 吞吐,平均值約為 3.5TB,在關閉階段同樣選擇這 10 個節點,統計下來的平均值約為 4.8TB,因此使用 JuiceFS 以后可以降低 HDFS 集群約 26% 的負載,如下圖所示,
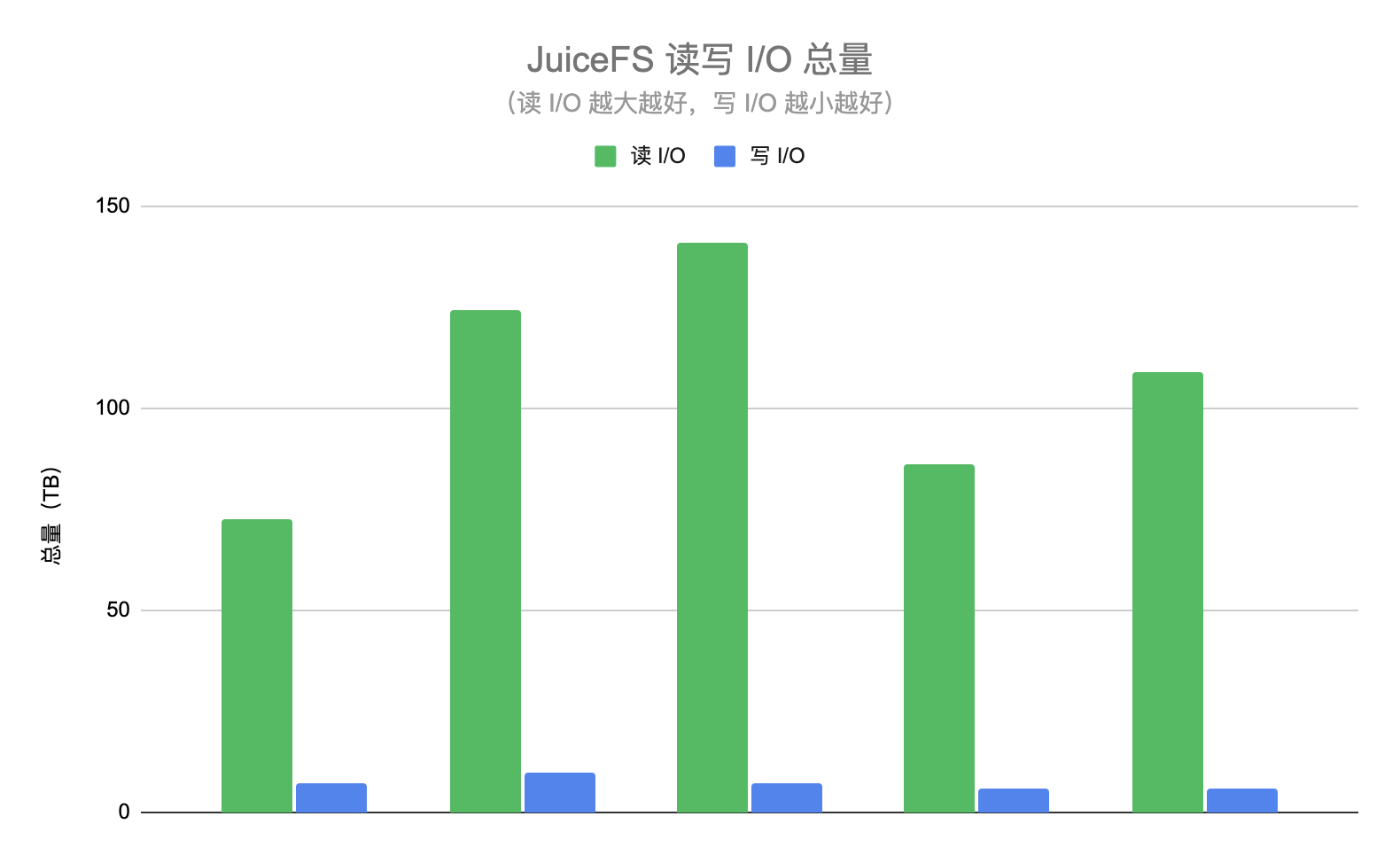
從另一個維度也能反映 HDFS 集群負載降低的效果,在這兩個階段我們都統計了讀取及寫入 JuiceFS 的 I/O 總量,JuiceFS 的讀 I/O 表示為 HDFS 集群降低的 I/O 量,如果沒有使用 JuiceFS 那么這些請求將會直接查詢 HDFS,JuiceFS 的寫 I/O 表示從 HDFS 拷貝的資料量,這些請求會增大 HDFS 的壓力,讀 I/O 總量應該越大越好,而寫 I/O 總量越小越好,下圖展示了某幾天的讀寫 I/O 總量,可以看到讀 I/O 基本是寫 I/O 的 10 倍以上,也就是說 JuiceFS 資料的命中率在 90% 以上,即超過 90% 的 ad-hoc 查詢都不需要請求 HDFS,
平均查詢耗時
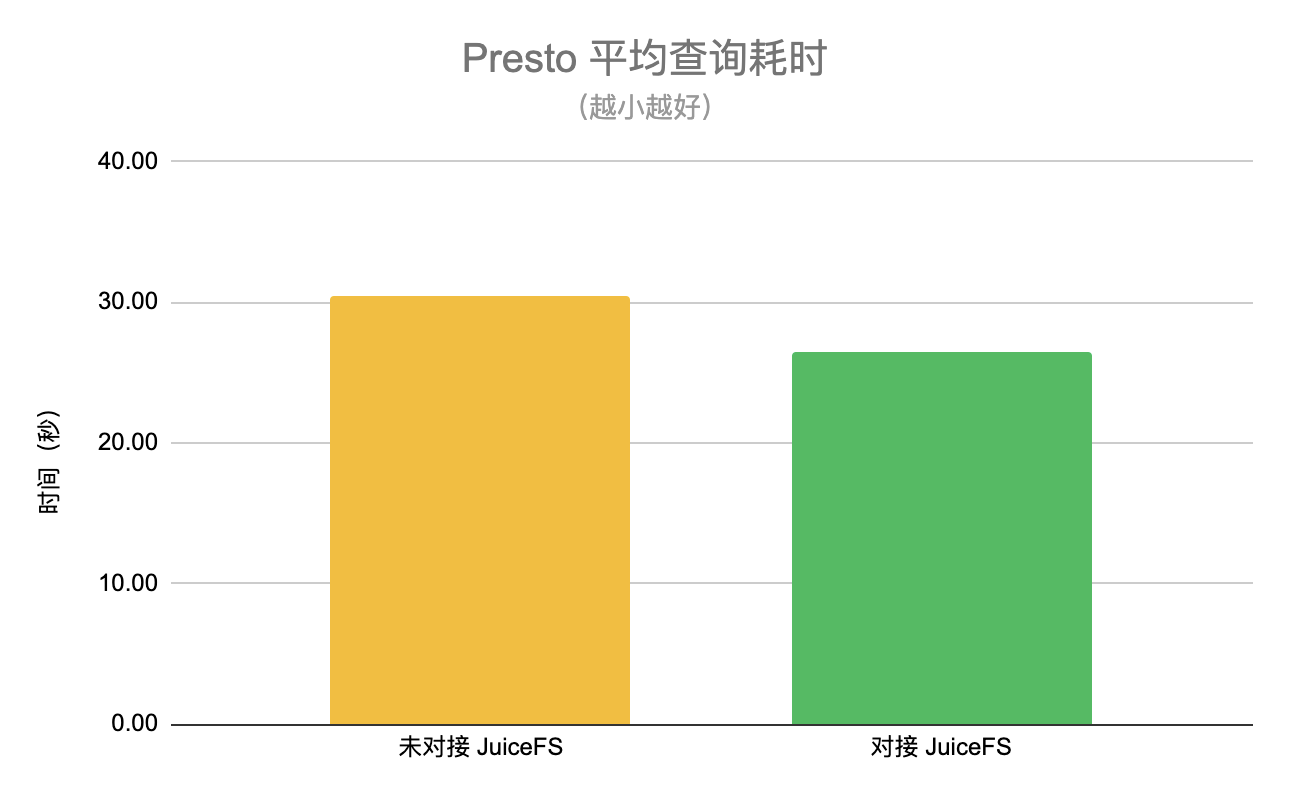
在某一階段將各 50% 流量的查詢請求分配給未對接和已對接 JuiceFS 的兩個集群,并分別統計平均查詢耗時,從下圖可以看到,使用 JuiceFS 以后平均查詢耗時降低約 13%,
測驗總結
JuiceFS 的方案在不改動業務配置的前提下,以對業務透明的方式大幅降低了 HDFS 集群的負載,超過 90% 的 Presto 查詢不再需要請求 HDFS,同時還降低了 13% 的 Presto 平均查詢耗時,超出最初設定的測驗目標預期,之前長期存在的大資料組件不穩定的問題也得到解決,
值得注意的是,整個測驗流程也很順暢,JuiceFS 僅用數天就完成了測驗環境的基礎功能和性能驗證,很快進入到生產環境灰度測驗階段,在生產環境中 JuiceFS 的運行也非常平穩,承受住了全量請求的壓力,程序中遇到的一些問題都能很快得到修復,
未來展望
展望未來還有更多值得嘗試和優化的地方:
- 進一步提升 JuiceFS 快取資料的命中率,降低 HDFS 集群負載,
- 增大 Presto worker 本地快取盤的空間,提升本地快取的命中率,優化長尾問題,
- Spark 集群接入 JuiceFS,覆寫更多 ad-hoc 查詢場景,
- 將 HDFS 平滑遷移至 JuiceFS,完全實作存盤和計算分離,降低運維成本,提升資源利用率,
專案地址:
Github (https://github.com/juicedata/juicefs)如有幫助的話歡迎 star (0?0?),鼓勵鼓勵我們喲!
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/337573.html
標籤:其他