2、預備知識-python核心用法常用資料分析庫(下)
概述
Python 是當今世界最熱門的編程語言,而它最大的應用領域之一就是資料分析,在python眾多資料分析工具中,pandas是python中非常常用的資料分析庫,在資料分析,機器學習,深度學習等領域經常被使用,使用 Pandas 我們可以 Excel/CSV/TXT/MySQL 等資料讀取,然后進行各種清洗、過濾、透視、聚合分析,也可以直接繪制折線圖、餅圖等資料分析圖表,在功能上它能夠實作自動化的對大檔案處理,能夠實作 Excel 的幾乎所有功能并且更加強大,
本實驗將通過實戰的方式,介紹pandas資料分析庫的基本使用,讓大家在短時間內快速掌握python的資料分析庫pandas的使用,為后續專案編碼做知識儲備
實驗環境
- Python 3.7
- Pycharm
任務二:Pandas資料分析實戰-1
【任務目標】
本任務主要目標為使用pandas進行資料分析實戰,在實戰程序中帶大家了解pandas模塊的一下功能:
- 了解資料
- 分析資料問題
- 清洗資料
- 整合代碼
【任務步驟】
1、準備作業
打開CMD視窗后,執行如下命令,打開jupyter notebook編輯器
jupyter notebook
成功執行以上命令后,系統將自動打開默認瀏覽器,如下圖所示:
成功打開瀏覽器后,按如下流程創建 notebook 檔案
對新建notebook進行重命名操作
2、notebook 檔案新建完成后,接下來在新建的 notebook 中撰寫代碼
- 了解資料
在處理任何資料之前,我們的第一任務是理解資料以及資料是干什么用的,我們嘗試去理解資料的列/行、記錄、資料格式、語意錯誤、缺失的條目以及錯誤的格式,這樣我們就可以大概了解資料分析之前要做哪些“清理”作業,
本次我們需要一個 patient_heart_rate.csv 的資料檔案,這個資料很小,可以讓我們一目了然,這個資料是 csv 格式,資料是描述不同個體在不同時間的心跳情況,資料的列資訊包括人的年齡、體重、性別和不同時間的心率,
- 加載資料即查看資料集
import pandas as pd
df = pd.read_csv('data/patient_heart_rate.csv')
df.head()
運行結果如下:
分析資料問題
- 沒有列頭
- 一個列有多個引數
- 列資料的單位不統一
- 缺失值
- 重復資料
- 非 ASCII 字符
- 有些列頭應該是資料,而不應該是列名引數
3、清洗資料
3.1、 沒有列頭
如果我們拿到的資料像上面的資料一樣沒有列頭,Pandas 在讀取 csv 提供了自定義列頭的引數,下面我們就通過手動設定列頭引數來讀取 csv,代碼如下:
import pandas as pd
column_names= ['id', 'name', 'age', 'weight','m0006',
'm0612','m1218','f0006','f0612','f1218']
df = pd.read_csv('data/patient_heart_rate.csv', names = column_names)
df.head()
運行結果如下:
上面的結果展示了我們自定義的列頭,我們只是在這次讀取 csv 的時候,多了傳了一個引數 names = column_names,這個就是告訴 Pandas 使用我們提供的列頭,
4、一個列有多個引數
在資料中不難發現,Name 列包含了兩個引數 Firtname 和 Lastname,為了達到資料整潔目的,我們決定將 name 列拆分成 Firstname 和 Lastname
使用 str.split(expand=True),將串列拆成新的列,再將原來的 Name 列洗掉
df[['first_name','last_name']] = df['name'].str.split(expand=True)
df.drop('name', axis=1, inplace=True)
df.head()
運行結果如下:
5、列資料的單位不統一
如果仔細觀察資料集可以發現 Weight 列的單位不統一,有的單位是 kgs,有的單位是 lbs
lbs_weight_s = df[df.weight.str.contains("lbs").fillna(False)]['weight']
lbs_weight_s = lbs_weight_s.apply(lambda lbs: "%.2fkgs" % (float(lbs[:-3])/2.2) )
df.loc[lbs_weight_s.index,'weight'] = lbs_weight_s
運行結果如下:
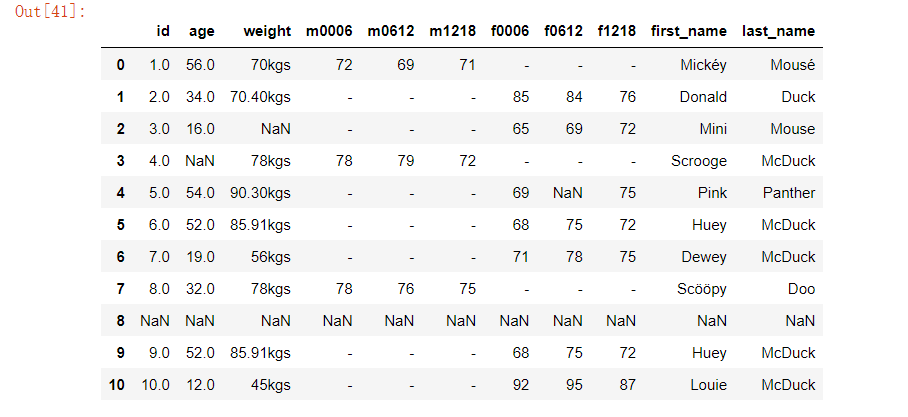
6、缺失值處理
在資料集中有些年齡、體重、心率是缺失的,我們又遇到了資料清洗最常見的問題——資料缺失,一般是因為沒有收集到這些資訊,我們可以咨詢行業專家的意見,典型的處理缺失資料的方法:
- 刪:洗掉資料缺失的記錄
- 贗品:使用合法的初始值替換,數值型別可以使用 0,字串可以使用空字串“”
- 均值:使用當前列的均值
- 高頻:使用當前列出現頻率最高的資料
- 源頭優化:如果能夠和資料收集團隊進行溝通,就共同排查問題,尋找解決方案,
7、重復資料處理
有的時候資料集中會有一些重復的資料,執行以下代碼觀察資料集前10條資料
df.head(10)
運行結果如下:
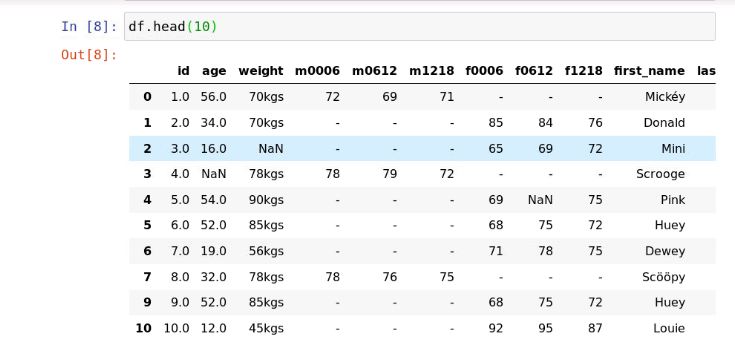
觀察以上結果,可以發現在我們的資料集中也存在重復的資料,如下
首先我們校驗一下是否存在重復記錄,如果存在重復記錄,就使用 Pandas 提供的 drop_duplicates() 來洗掉重復資料,
df.drop_duplicates(['first_name','last_name'],inplace=True)
df.head(10)
運行結果如下:
洗掉weight欄位重復的資料
df.drop_duplicates(['weight'],inplace=True)
df.head(10)
運行結果如下
8、 非ASCII 字符
在資料集中 Fristname 和 Lastname 有一些非 ASCII 的字符,
處理非 ASCII 資料方式有多種
- 洗掉
- 替換
- 僅僅提示一下
我們使用洗掉的方式:
df['first_name'].replace({r'[^\x00-\x7F]+':''}, regex=True, inplace=True)df['last_name'].replace({r'[^\x00-\x7F]+':''}, regex=True, inplace=True)df.head()
運行結果如下:
9、有些列頭應該是資料,而不應該是列名引數
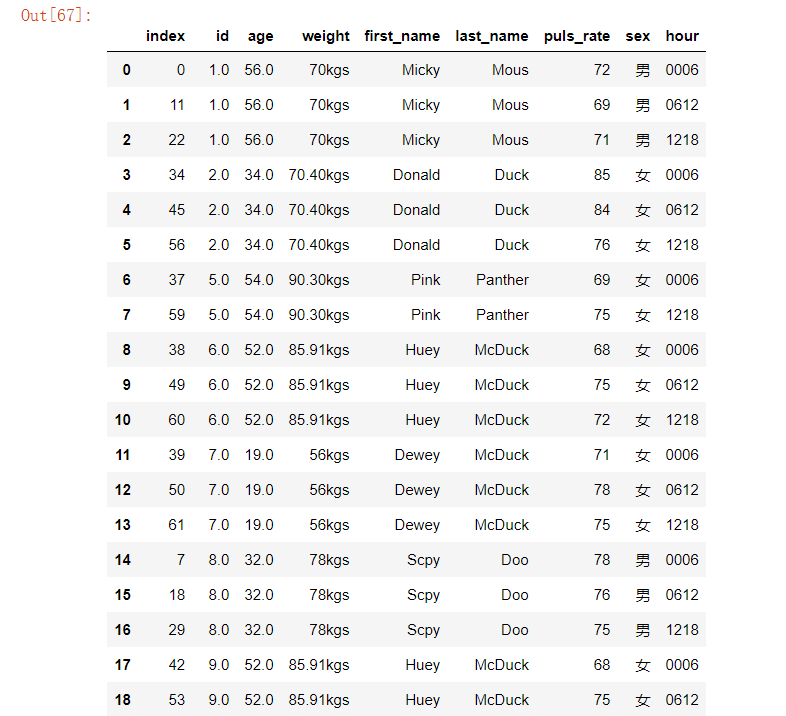
有一些列頭是有性別和時間范圍組成的,這些資料有可能是在處理收集的程序中進行了行列轉換,或者收集器的固定命名規則,這些值應該被分解為性別(m,f),小時單位的時間范圍(00-06,06-12,12-18)
sorted_columns = ['id','age','weight','first_name','last_name']df = pd.melt(df, id_vars=sorted_columns, var_name='sex_hour', value_name='puls_rate')df = df[df.puls_rate != '-'].dropna()df = df.sort_values(['id','first_name','last_name']).reset_index()def split_sex_date(sex_hour): sex = sex_hour[:1] if 'f' == sex: sex = '女' elif 'm' == sex: sex = '男' hour = sex_hour[1:] return pd.Series([sex,hour])df[['sex','hour']] = df.sex_hour.apply(split_sex_date)df.drop('sex_hour',axis=1)
運行結果如下:
任務三:Pandas資料分析實戰-2
【任務目標】
本任務主要目標為使用pandas進行資料分析實戰,在實戰程序中帶大家了解pandas模塊的一下功能:
- 日期的處理
- 字符編碼的問題
【任務步驟】
1、參考【任務一】第1步中操作,在jupyter notebook編輯中重新新建一個notebook 檔案,命名為 pandas-data-processing-3,如下圖所示:
2、預覽資料
這次我們使用 Artworks.csv,我們選取 100 行資料來完成本次內容,具體步驟:
- 匯入Pandas
- 讀取 csv 資料到 DataFrame(要確保資料已經下載到指定路徑)
DataFrame 是 Pandas 內置的資料展示的結構,展示速度很快,通過 DataFrame 我們就可以快速的預覽和分析資料,代碼如下:
import pandas as pddf = pd.read_csv('./data/Artworks.csv').head(100)df.head(10)
運行結果如下:
2、統計日期資料
我們仔細觀察一下 Date 列的資料,有一些資料是年的范圍(1976-1977),而不是單獨的一個年份,在我們使用年份資料畫圖時,就不能像單獨的年份那樣輕易的畫出來,我們現在就使用 Pandas 的 value_counts() 來統計一下每種資料的數量,
首先,選擇要統計的列,并呼叫 value_counts():
df['Date'].value_counts()
運行結果如下:
3、日期資料問題
Date 列資料,除了年份是范圍外,還有三種非正常格式,下面我們將這幾種列出來:
- 問題一,時間范圍(1976-77)
- 問題二,估計(c. 1917,1917 年前后)
- 問題三,缺失資料(Unknown)
- 問題四,無意義資料(n.d.)
接下來我們會處理上面的每一個問題,使用 Pandas 將這些不規則的資料轉換為統一格式的資料,
問題一和二是有資料的只是格式上欠妥當,問題三和四實際上不是有效資料,針對前兩個問題,我們可以通過代碼將據格式化來達到清洗的目的,然而,后兩個問題,代碼上只能將其作為缺失值來處理,簡單起見,我們將問題三和四的資料處理為0,
處理問題一
問題一的資料都是兩個年時間范圍,我們選擇其中的一個年份作為清洗之后的資料,為了簡單起見,我們就使用開始的時間來替換這樣問題的資料,因為這個時間是一個四位數的數字,如果要使用結束的年份,我們還要補齊前兩位的數字,
首先,我們需要找到問題一的資料,這樣我們才能將其更新,要保證其他的資料不被更新,因為其他的資料有可能是已經格式化好的,也有可能是我們下面要處理的,
我們要處理的時間范圍的資料,其中包含有“-”,這樣我們就可以通過這個特殊的字串來過濾我們要處理的資料,然后,通過 split() 利用“-”將資料分割,將結果的第一部分作為處理的最終結果,
代碼如下
row_with_dashes = df['Date'].str.contains('-').fillna(False)for i, dash in df[row_with_dashes].iterrows(): df.at[i,'Date'] = dash['Date'][0:4]df['Date'].value_counts()
運行結果如下:
處理問題二
問題二的資料體現了資料本身的不準確性,是一個估計的年份時間,我們將其轉換為年份,那么,就只要保留最后四位數字即可,該資料的特點就是資料包含“c”,這樣我們就可以通過這一特征將需要轉換的資料過濾出來,
row_with_cs = df['Date'].str.contains('c').fillna(False)for i,row in df[row_with_cs].iterrows(): df.at[i,'Date'] = row['Date'][-4:]df[row_with_cs]
運行結果如下:
處理問題三四
將這問題三四的資料賦值成初始值 0
df['Date'] = df['Date'].replace('Unknown','0',regex=True)
df['Date'] = df['Date'].replace('n.d.','0',regex=True)
df['Date']
運行結果如下:
4、附:完成代碼
注意:完整代碼中洗掉了資料展示部分
import pandas as pd
df = pd.read_csv('../data/Artworks.csv').head(100)
df.head(10)
df['Date'].value_counts()
row_with_dashes = df['Date'].str.contains('-').fillna(False)
for i, dash in df[row_with_dashes].iterrows():
df.at[i,'Date'] = dash['Date'][0:4]
df['Date'].value_counts()
row_with_cs = df['Date'].str.contains('c').fillna(False)
for i,row in df[row_with_cs].iterrows():
df.at[i,'Date'] = row['Date'][-4:]
df['Date'].value_counts()
df['Date'] = df['Date'].replace('Unknown','0',regex=True)
df['Date'] = df['Date'].replace('n.d.','0',regex=True)
df['Date'].value_counts()
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/340439.html
標籤:其他
上一篇:資料庫的結構