當名為“ID”和“Year”的兩列中的關聯值重復時,我想洗掉名為“employee”的列中的重復值。例如,如果這是 DataFrame:
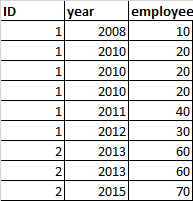
這就是我想要得到的:
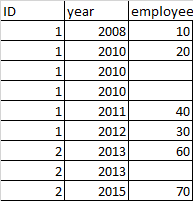
這是我所做的,但沒有奏效:
df.loc[((df["ID"].duplicated()) & (df["year"].duplicated()) ), ["employee"]] = ''
我發現“員工”的值已從某些不應洗掉的單元格中洗掉。
uj5u.com熱心網友回復:
你可以做
df.loc[df[['ID','year']].duplicated(),'employee'] = ''
uj5u.com熱心網友回復:
您可以使用np.where().
import numpy as np
df['employee'] = np.where(df[['ID','year']].duplicated(), '', df['employee'])
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/343213.html
上一篇:超過AppEngine最大實體數
下一篇:為DataClass創建鎖函式