我在同一個資料集上運行了不同的分類器。運行分類器后,我得到了一些統計值。
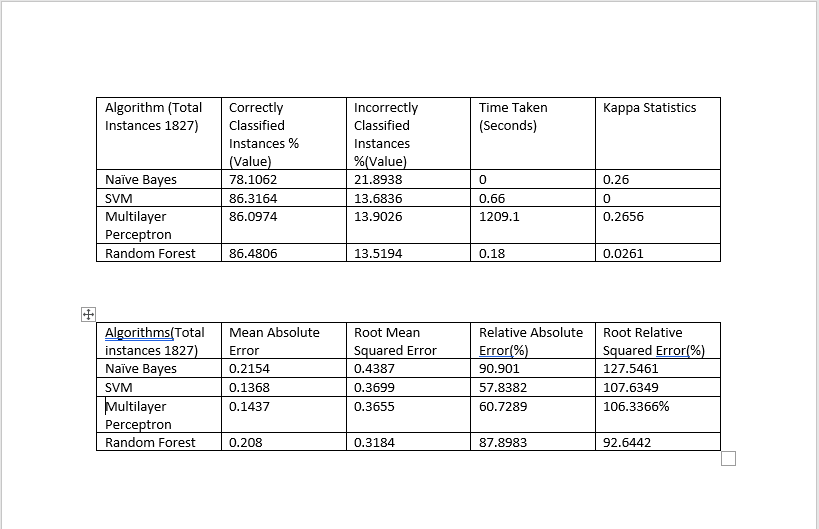
這是所有分類器的總結
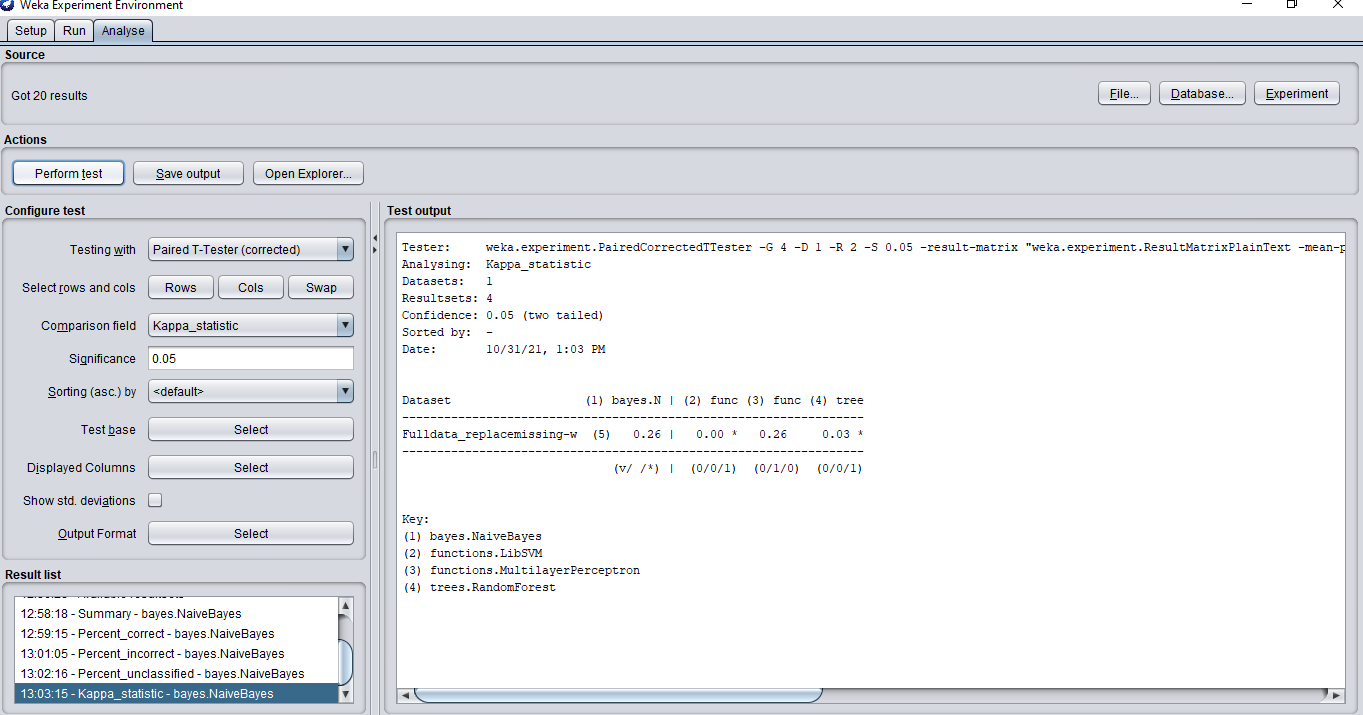
我正在使用 Weka 來訓練模型。Weka 本身有一種方法可以比較不同的演算法。為此,我們需要使用Experiment選項卡。我也為相同的資料集完成了這個選項。
使用實驗選項卡時,Weka 給了我 Kappa 統計的結果
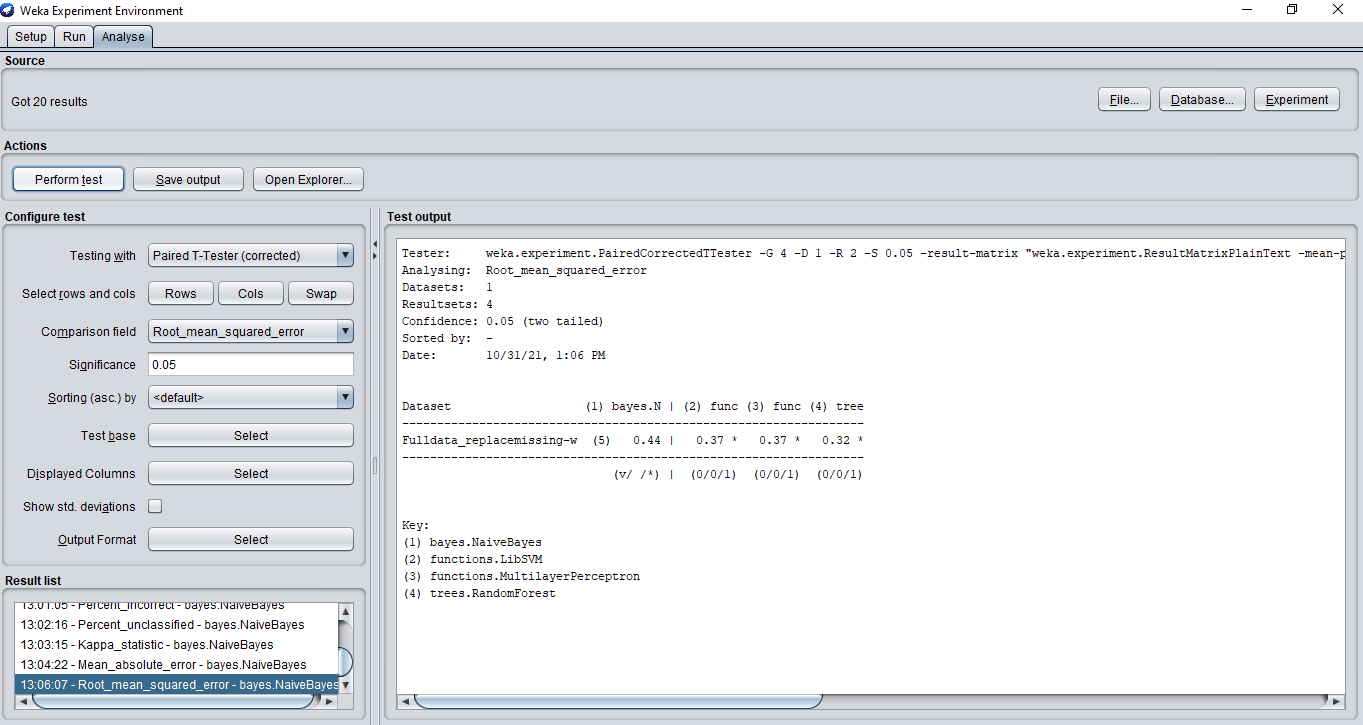
均方根誤差是
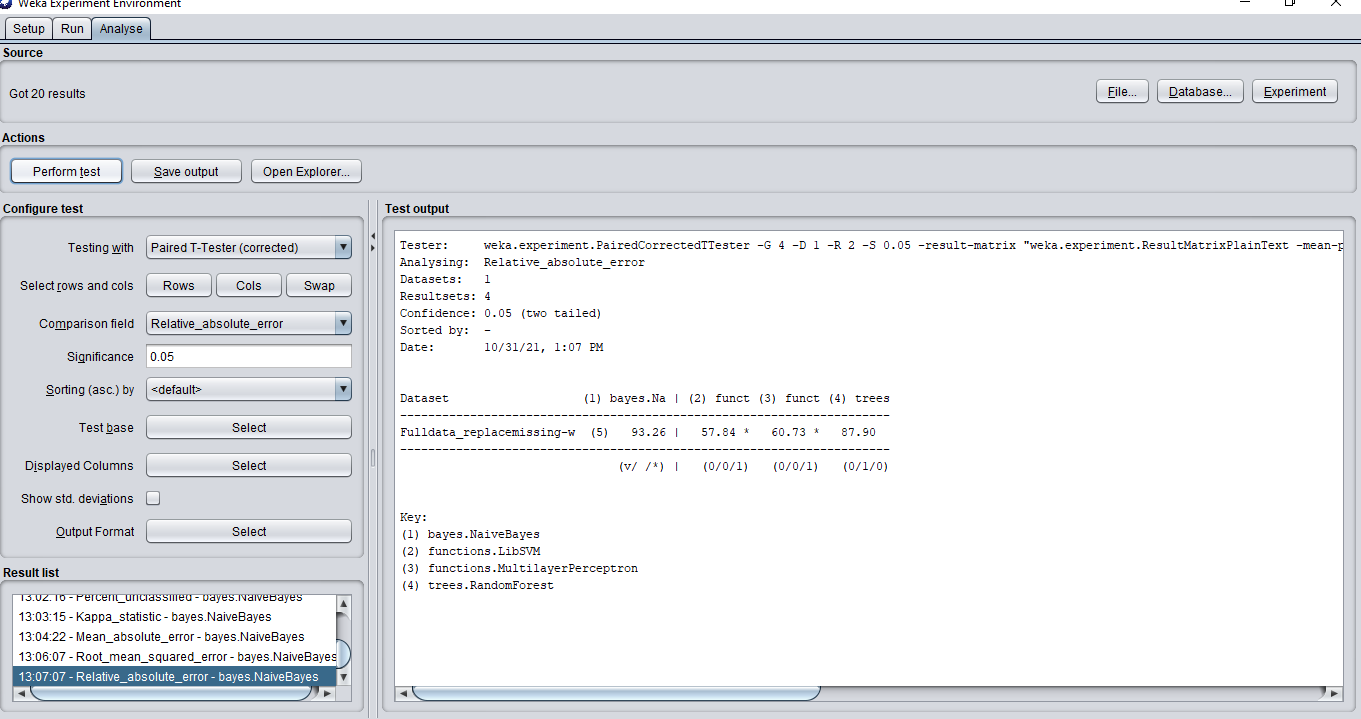
相對絕對誤差
等等.....
現在我無法理解我從“實驗”選項卡中獲得的值與我在第一張圖片中的表格格式中共享的值有何相似之處?
uj5u.com熱心網友回復:
我假設初始表中填充了從 Weka Explorer 中的交叉驗證運行獲得的統計資訊。
資源管理器在單個交叉驗證運行中聚合預測,因此看起來您有一個該大小的測驗集。它僅用作探索工具,因此得名。
實驗器記錄在您在實驗期間執行的運行次數中從每個折疊對生成的指標(如準確度、rmse 等)。然后可以使用顯著性測驗分析跨多個分類器和/或資料集收集的指標。默認情況下,使用 10 次 10 倍 CV 的運行,建議用于此類比較。這會為每個度量產生 100 個單獨的值,從中生成均值和標準差。*/v 表示是否存在統計上顯著的輸/贏。
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/347343.html
上一篇:K-NearestNeighbors程式總是報告相同的類值
下一篇:訓練自定義word2vec模型