場景
最近作業中,發現某同步JOB在執行中經常拋出SQL執行超時的問題,查看日志發現每次SQL執行的時間都是線性增長的,回圈執行50次以后執行時間甚至超過了5分鐘
JOB執行流程分析
首先,對于JOB流程進行分析,查看是否是JOB設計上的問題
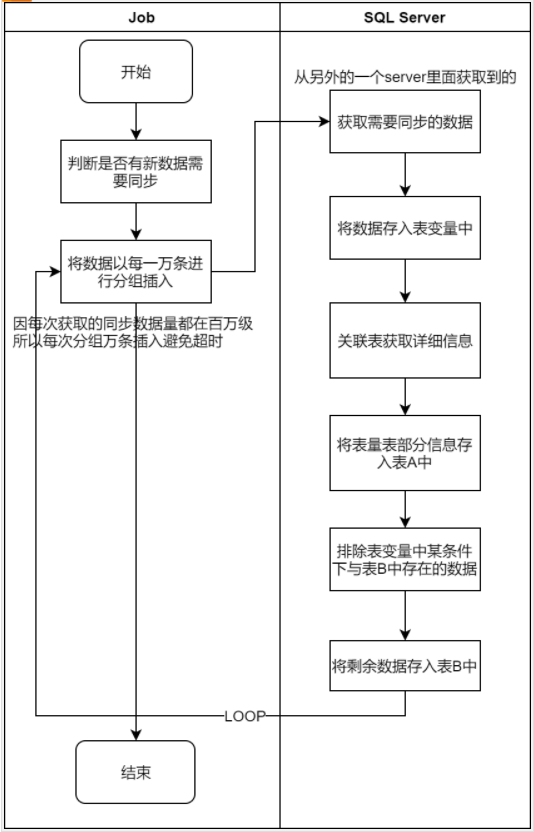
通過對流程的分析,發現每次獲取的需要同步的資料最多只有一萬條,不存在大資料寫入導致超時的問題,
那么在對獲取詳細資訊這個程序進行分析,發現關聯的表中最多的資料已經上億了,可能是這里導致了整體SQL執行變慢的原因,這里能算可疑點一,
再接著往下一個流程看與表B對比重復資料時,隨著回圈執行表B的資料會越來越多,那么會不會這里是導致回圈執行下執行時間稱線性增長的主要原因呢,
逐一排除問題
之前我們通過分析JOB執行流程,發現了兩個可疑點,那么現在具體分析SQL的問題
CREATE TABLE #TableTemp ( 欄位A int null, 欄位B int null, 欄位C int null ) INSERT INTO #TableTemp( 欄位A, 欄位B )SELECT a.欄位A, 欄位B FROM ServerA.dbo.TableB a WITH(NOLOCK) LEFT JOIN dbo.TableA b WITH(NOLOCK) a.Id = b.Id UPDATE a SET a.欄位C = b.欄位D FROM #TableTemp a LEFT JOIN dbo.TableC b WITH(NOLOCK) ON a.欄位A =b.id INSERT INTO dbo.目標TableA( 欄位A, 欄位B ) SELECT 欄位A, 欄位B FROM #TableTemp WITH(NOLOCK) INSERT INTO dbo.目標TableB( 欄位A, 欄位B, 欄位C ) SELECT DISTINCT a.欄位A, a.欄位B, a.欄位C FROM #TableTemp a WITH(NOLOCK) LEFT JOIN dbo.目標TableB b ON a.欄位A = b.欄位A AND a.欄位B = b.欄位B WHERE a.PK IS NULL
先來查看可疑點一,是不是這里出了問題,因為表TableC資料已經是幾億的量,但單獨將該SQL執行發現,因為索引的存在發現執行并不是特別慢,所以可以排除掉該問題
那么來看看可疑點二呢
INSERT INTO dbo.目標TableB( 欄位A, 欄位B, 欄位C ) SELECT DISTINCT a.欄位A, a.欄位B, a.欄位C FROM #TableTemp a WITH(NOLOCK) LEFT JOIN dbo.目標TableB b ON a.欄位A = b.欄位A AND a.欄位B = b.欄位B WHERE a.PK IS NULL
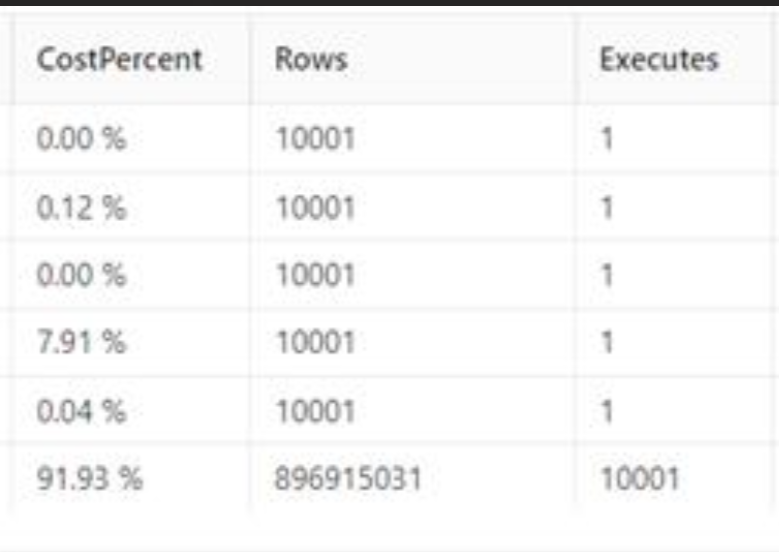
可以看到該SQL插入的同時還查詢了自身是否存在條件下相同的資料,查看表目標TableB發現,該表沒有主鍵也沒有索引,再通過DBA那邊提供的SQL分析發現,這句SQL對于dbo.目標TableB進行了全表掃描,再加上插入的1W條資料,相當于對于dbo.目標TableB全表掃描了1w次,隨著回圈的執行該表資料越來越多,執行時間也就越來越長,看來這里就是導致執行時間線性增長的主要原因了,
解決問題
根據上面問題的排除,我們已經得知問題的關鍵所在就是進行了1w次的全表掃描,導致了SQL執行時間過長,那么解決問題的關鍵所在就是避免這么多次的全表掃描,那么最直接的解決方法,就是建立索引避免全表掃描
1.通過使用臨時表代替表變數
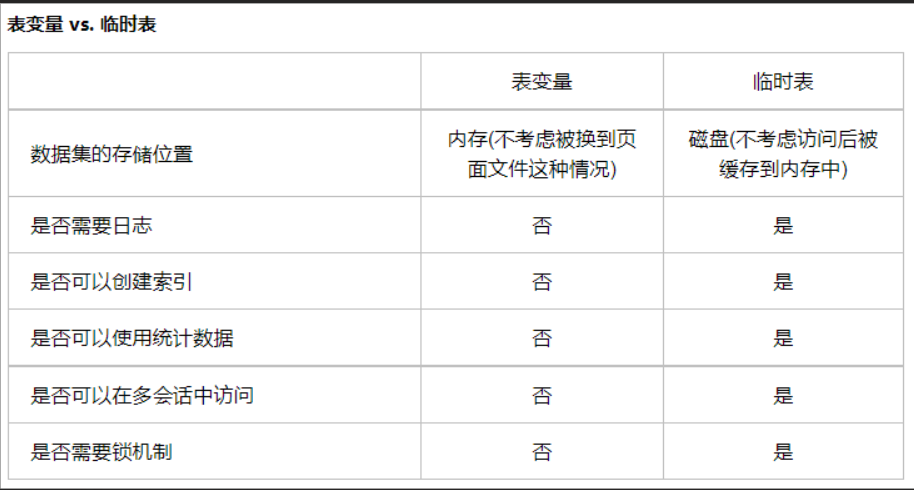
先來看看,表變數與臨時表的區別,可以看到表變數是無法使用索引的,所以我們使用索引避免全表掃描的話必須要代替掉表變數,然后在臨時表的欄位A上我們創建索引
2.修改目標TableB的寫入邏輯
現有寫入邏輯會先判斷是否在目標TableB中是否存在,不存在時則寫入表中,保持業務的情況下,我們稍微修改下邏輯,再寫入之前先排除掉與目標TableB中的資料,將剩余資料寫入表中,就能避免回圈1W次的目標TableB表查詢了
通過這兩處修改后,再執行該JOB發現問題得到了完美的解決,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/350733.html
標籤:SQL Server