我正在從事一個專案,每天從網路上抓取大量資料并將它們輸入到資料庫中。我一直試圖盡可能有條不紊地做這件事。我能夠創建一個能夠從多個頁面中提取資料的決議函式。但是,當我添加決議項功能時,我一直失敗。我已經閱讀了 Scrapy 檔案并嘗試盡可能地遵循它,但無濟于事。
我被困了幾天,想向 Stack Overflow 社區尋求幫助。如果我的問題很長,我深表歉意。我一直很困惑,我想看看我是否能得到一個徹底的解釋/指導,而不是一個接一個地為我遇到的每個問題發布一個問題。我只是想讓我的專案盡可能高效和做得好。非常感謝任何和所有幫助。謝謝^^
完整代碼:
import scrapy
from scrapy import Request
from datetime import datetime
from scrapy.crawler import CrawlerProcess
dt_today = datetime.now().strftime('%Y%m%d')
file_name = dt_today ' HPI Data'
# Create Spider class
class UneguiApartments(scrapy.Spider):
name = 'unegui_apts'
allowed_domains = ['www.unegui.mn']
custom_settings = {'FEEDS': {f'{file_name}.csv': {'format': 'csv'}},
'USER_AGENT': "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36"}
start_urls = [
'https://www.unegui.mn/l-hdlh/l-hdlh-zarna/oron-suuts-zarna/'
]
def parse(self, response):
cards = response.xpath('//li[contains(@class,"announcement-container")]')
for card in cards:
name = card.xpath(".//a[@itemprop='name']/@content").extract_first()
price = card.xpath(".//*[@itemprop='price']/@content").extract_first()
date_block = card.xpath("normalize-space(.//div[contains(@class,'announcement-block__date')]/text())").extract_first().split(',')
date = date_block[0].strip()
city = date_block[1].strip()
link = card.xpath(".//a[@itemprop='url']/@href").extract_first()
yield Request(link, callback=self.parse_item)
yield {'name': name,
'price': price,
'date': date,
'city': city,
'link': 'https://www.unegui.mn' link
}
def parse_item(self, response):
# extract things from the listinsg item page
spanlist = response.xpath('.//span[contains(@class, )]//text()').extract()
alist = response.xpath(".//a[@itemprop='url']/@href").extract()
list_item1 = spanlist[0].strip()
list_item2 = spanlist[1].strip()
list_item3 = alist[0].strip()
list_item4 = alist[1].strip()
yield {'item1': list_item1,
'item2': list_item2,
'item3': list_item3,
'item4':list_item4
}
next_url = response.xpath(
"//a[contains(@class,'red')]/parent::li/following-sibling::li/a/@href").extract_first()
if next_url:
# go to next page until no more pages
yield response.follow(next_url, callback=self.parse)
# main driver
if __name__ == "__main__":
process = CrawlerProcess()
process.crawl(UneguiApartments)
process.start()
當前結果:
運行日志: 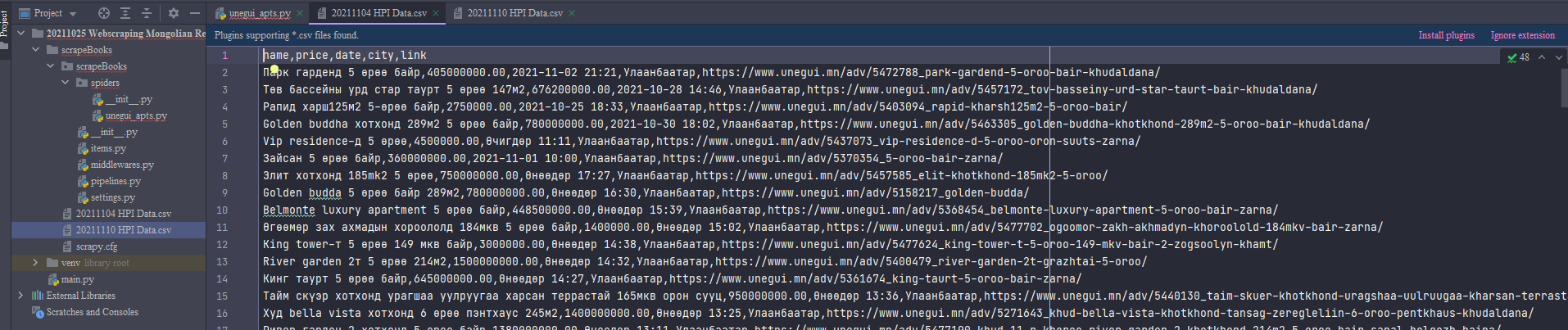
專案圖片片段:

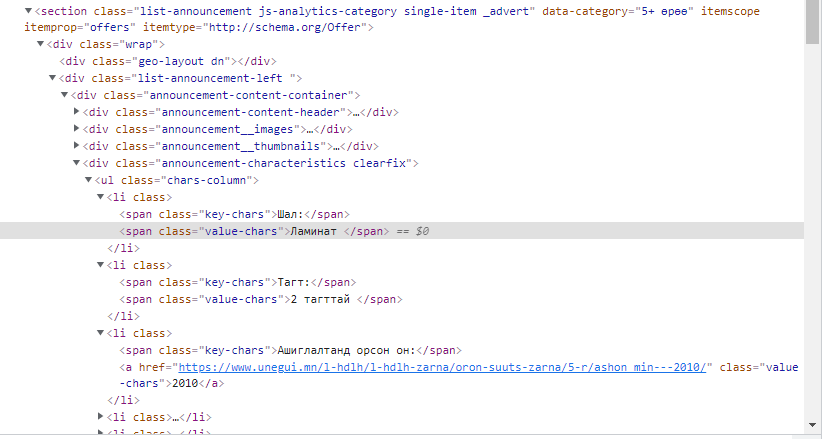
專案 HTML 片段:
旁注,如果有人有時間或興趣進一步指導我。將來我計劃添加到我的代碼中,以便我可以:
- 使用 selenium 之類的東西能夠抓取動態頁面(例如,能夠點擊顯示文本/資料的按鈕,然后能夠抓取它)。
- 清理、轉換和規范化抓取的資料。
- 添加到 DBeaver 資料庫。
- Check and remove duplicates so there is only 1 unique apartment listing in the database.
- Run a scheduled web scraper once a day automatically.
Hopefully, I want to scrape all categories of data from https://www.unegui.mn using scraps and make a spider for each category. The website has ~94,000 listings. Once completed, ideally I want to add a few more different websites to get additional advertisement listings.
Currently, I am scraping and outputting as a CSV file. Ideally, I want to be able to not only output as a CSV file on choice but to upload my data directly to a DBeaver database. I understand this is a large undertaking, but I really want to make a complex and diverse scrapy code that can be used to collect a large volume of data daily. Is this too ambitious? Once again, thank you for any and all input, and I apologize for the long post.
Questions:
- Is it better to use one spider for each category from one website, or one spider per website?
- Should I put all my web listings scraping code into one project folder or split them up?
- Is there a naming convention I should follow?
- Will using ItemLoader() and Input and Output make my code more efficient and faster? If not, taking into consideration my future additions, what path/method should I implement?
- 我是否應該遵循任何其他方法或約定來使我的代碼盡可能高效和結構良好?
uj5u.com熱心網友回復:
看看你的日志似乎有一個錯誤:
raise ValueError(f'Missing scheme in request url: {self._url}')
ValueError: Missing scheme in request url: /adv/5040771_belmonte/
我懷疑這條線有問題,因為它可能會產生對相對 url 的請求,其中 Scrapy 的 Request 物件總是希望 url 是絕對的:
cards = response.xpath('//li[contains(@class,"announcement-container")]')
for card in cards:
name = card.xpath(".//a[@itemprop='name']/@content").extract_first()
price = card.xpath(".//*[@itemprop='price']/@content").extract_first()
date_block = card.xpath("normalize-space(.//div[contains(@class,'announcement-block__date')]/text())").extract_first().split(',')
date = date_block[0].strip()
city = date_block[1].strip()
link = card.xpath(".//a[@itemprop='url']/@href").extract_first()
yield Request(link, callback=self.parse_item)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
yield {'name': name,
'price': price,
'date': date,
'city': city,
'link': 'https://www.unegui.mn' link
}
link這里的變數可以是一個相對鏈接(就像你的 lgos 中提到的那個/adv/5040771_belmonte。
要明確解決此問題,請使用 urljoin:
yield Request(response.urljoin(link), callback=self.parse_item)
或使用response.follow快捷方式:
yield response.follow(link, callback=self.parse_item)
此外,您應該在回呼之間使用專案結轉:
def parse(self, response):
cards = response.xpath('//li[contains(@class,"announcement-container")]')
for card in cards:
# ...
item = {'name': name,
'price': price,
'date': date,
'city': city,
'link': 'https://www.unegui.mn' link
}
yield response.follow(link, callback=self.parse_item, meta={"item": item})
def parse_item(self, response):
# retrieve previously scraped item
item = response.meta['item']
# ... parse additional details
item.update({'item1': list_item1,
'item2': list_item2,
'item3': list_item3,
'item4':list_item4
})
yield item
# ... next url
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/356353.html
上一篇:添加行sql時在列中重新編號