我有一個 data.frame 并且想要平均一列存在 NA 的列。
在執行計算時,我注意到 R 無法計算平均值,結果回傳 NA。
OBS:我無法洗掉帶有 NA 的行,因為它會洗掉具有我感興趣的值的其他列。
df1<-read.table(text="st date ph
1 01/02/2004 5
16 01/02/2004 6
2 01/02/2004 8
2 01/02/2004 8
2 01/02/2004 8
16 01/02/2004 6
1 01/02/2004 NA
1 01/02/2004 5
16 01/02/2004 NA
", sep="", header=TRUE)
df2<-df1%>%
group_by(st, date)%>%
summarise(ph=mean(ph))
View(df2)
出去
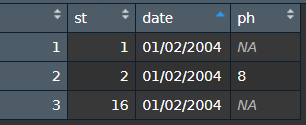
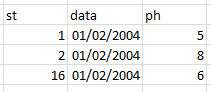
我的期望是這樣的結果:
uj5u.com熱心網友回復:
你需要使用na.rm = TRUE:
df2<-df1%>%
group_by(st, date)%>%
summarise(ph=mean(ph, na.rm = TRUE))
df2
# A tibble: 3 x 3
# Groups: st [3]
st date ph
<int> <chr> <dbl>
1 1 01/02/2004 5
2 2 01/02/2004 8
3 16 01/02/2004 6
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/358126.html
上一篇:R中求和分數的計算序列