我有一個像這樣的資料框:
--------- ------------------
|rownumber| Moving_Ratio|
--------- ------------------
| 1000|105.67198820168865|
| 1001|105.65729748456914|
| 1002| 105.6426671752822|
| 1003|105.62808965618223|
| 1004|105.59623035662119|
| 1005|105.52385366516299|
| 1006|105.44762361744378|
| 1007|105.35977134665733|
| 1008|105.25685407339793|
| 1009|105.16307473993363|
| 1010|105.06600545864703|
| 1011|104.96056753478364|
| 1012|104.84525664217107|
| 1013| 104.7401615868953|
| 1014| 104.6283459710509|
| 1015|104.53484736833259|
| 1017|104.43492576734955|
| 1019|104.33599903547659|
| 1020|104.24640223269283|
| 1021|104.15275303890549|
--------- ------------------
有 10k 行,我剛剛為示例視圖截斷了它。資料絕不是線性的,看起來像這樣:
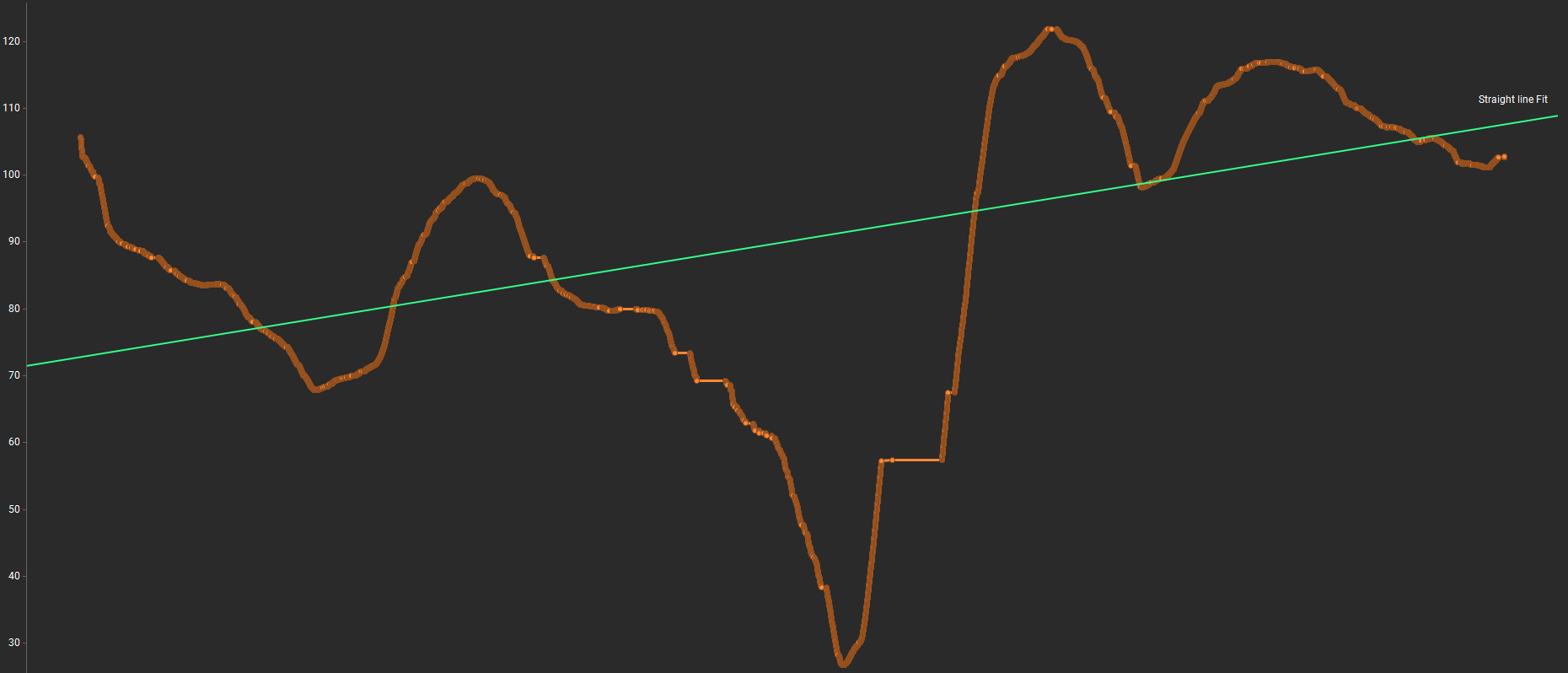
但是,我并不擔心每個資料點的完美擬合。我基本上是想擬合一條捕捉曲線方向并找到它的斜率的線。如由統計軟體生成的影像中的綠線所示。
我試圖放在一行中的特征列是Moving_Ratio
的最小值和最大值Moving_Ratio是:
----------------- ------------------
|min(Moving_Ratio)| max(Moving_Ratio)|
----------------- ------------------
|26.73629202745194|121.84100616620908|
----------------- ------------------
我嘗試使用以下代碼創建一個簡單的線性模型:
vect_assm = VectorAssembler(inputCols =['Moving_Ratio'], outputCol='features')
df_vect=vect_assm.transform(df)\
lir = LinearRegression(featuresCol = 'features', labelCol='rownumber', maxIter=50,
regParam=0.3, elasticNetParam=0.8)
model = lir.fit(df_vect)
Predictions = model.transform(df_vect)
coeff=model.coefficients
當我查看預測時,我似乎得到的值遠不及與這些行號對應的原始資料。
Predictions.show()
--------- ------------------ -------------------- -----------------
|rownumber| Moving_Ratio| features| prediction|
--------- ------------------ -------------------- -----------------
| 1000|105.67198820168865|[105.67198820168865]|8935.419272488462|
| 1001|105.65729748456914|[105.65729748456914]| 8934.20373303444|
| 1002| 105.6426671752822| [105.6426671752822]|8932.993191845864|
| 1003|105.62808965618223|[105.62808965618223]|8931.787018623438|
| 1004|105.59623035662119|[105.59623035662119]|8929.150916159619|
| 1005|105.52385366516299|[105.52385366516299]| 8923.1623232745|
| 1006|105.44762361744378|[105.44762361744378]|8916.854895949407|
| 1007|105.35977134665733|[105.35977134665733]| 8909.58582253401|
| 1008|105.25685407339793|[105.25685407339793]|8901.070240542358|
| 1009|105.16307473993363|[105.16307473993363]|8893.310750051145|
| 1010|105.06600545864703|[105.06600545864703]|8885.279042666287|
| 1011|104.96056753478364|[104.96056753478364]| 8876.55489697866|
| 1012|104.84525664217107|[104.84525664217107]|8867.013842017961|
| 1013| 104.7401615868953| [104.7401615868953]|8858.318065966234|
| 1014| 104.6283459710509| [104.6283459710509]|8849.066217228752|
| 1015|104.53484736833259|[104.53484736833259]|8841.329954963563|
| 1017|104.43492576734955|[104.43492576734955]|8833.062240915566|
| 1019|104.33599903547659|[104.33599903547659]|8824.876844336828|
| 1020|104.24640223269283|[104.24640223269283]|8817.463424838508|
| 1021|104.15275303890549|[104.15275303890549]| 8809.71470236567|
--------- ------------------ -------------------- -----------------
Predictions.select(min('prediction'),max('prediction')).show()
----------------- ------------------
| min(prediction)| max(prediction)|
----------------- ------------------
|2404.121157489531|10273.276308929268|
----------------- ------------------
coeff[0]
82.74200940195973
預測的最小值和最大值完全在輸入資料之外。我究竟做錯了什么?任何幫助將不勝感激
uj5u.com熱心網友回復:
初始化 LinearRegression 物件時, featuresCol 應列出所有特征(自變數),labelCol 應列出標簽(因變數)。由于您正在預測 'Moving_Ratio',請設定 featuresCol='rownumber' 和 labelCol='Moving_Ratio' 以正確指定 LinearRegression。
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/360757.html
上一篇:如何從SparkDataframe插入、更新資料庫中的行
下一篇:Spark-檢查兩個字串列的交集