我試圖將 Spark 用于一個非常簡單的用例:給定大量檔案 (90k),其中包含數百萬個設備的設備時間序列資料,將給定設備的所有時間序列讀取分組為一組檔案(劃分)。現在假設我們的目標是 100 個磁區,并且給定的設備資料顯示在同一個輸出檔案中并不重要,只是同一個磁區。
鑒于這個問題,我們想出了兩種方法來做到這一點 - repartitionthenwrite或writewithpartitionBy應用于Writer. 其中任何一個的代碼都非常簡單:
repartition(添加了哈希列以確保與partitionBy以下代碼的比較是一對一的):
df = spark.read.format("xml") \
.options(rowTag="DeviceData") \
.load(file_path, schema=meter_data) \
.withColumn("partition", hash(col("_DeviceName")).cast("Long") % num_partitions) \
.repartition("partition") \
.write.format("json") \
.option("codec", "org.apache.hadoop.io.compress.GzipCodec") \
.mode("overwrite") \
.save(output_path)
partitionBy:
df = spark.read.format("xml") \
.options(rowTag="DeviceData") \
.load(file_path, schema=meter_data) \
.withColumn("partition", hash(col("_DeviceName")).cast("Long") % num_partitions) \
.write.format("json") \
.partitionBy(“partition”) \
.option("codec", "org.apache.hadoop.io.compress.GzipCodec") \
.mode("overwrite") \
.save(output_path)
在我們的測驗repartition中比partitionBy. 為什么是這樣?
根據我的理解,這repartition會導致洗牌,我的 Spark 學習告訴我要盡可能避免。另一方面,partitionBy(根據我的理解)只對每個節點進行本地排序操作 - 不需要洗牌。我是否誤解了一些讓我認為partitionBy會更快的東西?
uj5u.com熱心網友回復:
TLDR:當您呼叫時partitionBy,Spark 會觸發排序,而不是哈希重新磁區。這就是為什么它在你的情況下要慢得多。
我們可以用一個玩具例子來檢查:
spark.range(1000).withColumn("partition", 'id % 100)
.repartition('partition).write.csv("/tmp/test.csv")
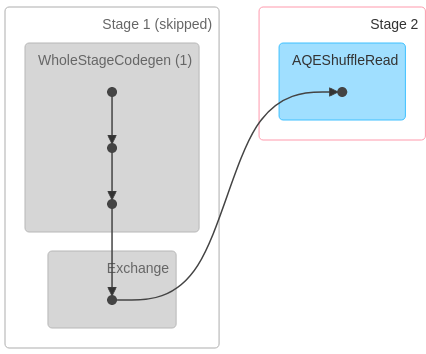
不要關注灰色階段,它被跳過,因為它是在之前的作業中計算的。
然后,與partitionBy:
spark.range(1000).withColumn("partition", 'id % 100)
.write.partitionBy("partition").csv("/tmp/test2.csv")
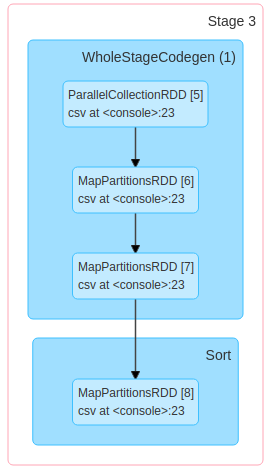
You can check that you can add repartition before partitionBy, the sort will still be there. So what's happening? Notice that the sort in the second DAG does not trigger a shuffle. It is a map partition. In fact, when you call partitionBy, spark does not shuffle the data as one would expect at first. Spark sorts each partition individually and then each executor writes his data in the according partition, in a separate file. Therefore, note that with partitionBy you are not writing num_partitions files but something between num_partitions and num_partitions * num_executors files. Each partition has one file per executor containing data belonging to that partition.
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/360773.html
標籤:阿帕奇火花 火花 apache-spark-sql apache-spark-xml
上一篇:Spark未完全讀取AVRO檔案