假設我的資料框是這樣的:
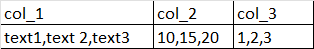
使用以下代碼在每列內拆分資料:
col_names = ['col1','col2','col3']
for i in range(len(df)):
s = tuple(zip(df[col_names[0]].str.split(",")[i],df[col_names[1]].str.split(",")[i],df[col_names[2]].str.split(",")[i])
我更改了此代碼,以便它使用串列理解動態作業以處理 col_names 中可變數量的列,如下所示:
for i in range (len(df)):
s = tuple(zip(df[col].str.split(",")[i] for col in col_names)
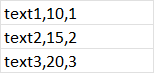
用于提供輸出的初始代碼為:
但是現在在添加串列理解之后它看起來像:
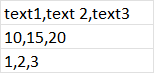
這段代碼有什么問題?
uj5u.com熱心網友回復:
#1) 您的代碼效率極低,因為它df[col].str.split(",")為每個i.
#2) 您的直接錯誤是 zip。您將一個迭代器作為引數傳遞給它。您需要向它傳遞多個引數。正確的轉換方式是zip(*(........))
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/369899.html
上一篇:ReactJS將json轉換為[name:value:]對
下一篇:生成一列時間