我正在嘗試將 dict 轉換為 Pandas DataFrame,如下所示:
dff = pd.DataFrame(
{
'CEO': 'ucMMe Mhll',
'address': 'vs5dlt3 B Se1kC eve0nre',
'address2': '-',
'city': 'a CSatanral',
'companyName': 'Agilent Technologies Inc.',
'country': 'nUatei tdetSs',
'description': "tns oo el' yty",
'employees': 17124,
'exc': 'gdgdgd',
'industry': 'sgeiTeotiroaLbtans r',
'issueType': 'abc',
'phone': '14087832319',
'primarySicCode': 4008,
'sector': ',atnSii Scilcofe,nnse TecisaPliinafs cedorhv cre',
'securityName': 'elooIne.nen htc iisTcgAgl',
'state': 'ailairofnC',
'symbol': 'A',
'tags': ['nllh he', 'gth', 'acsl', 'isiad', 'nr aitT'],
'website': 'win.gcm.',
'zip': '0752501-19'} )
當我列印出 DataFrame 時,我看到以下輸出:
print(dff)
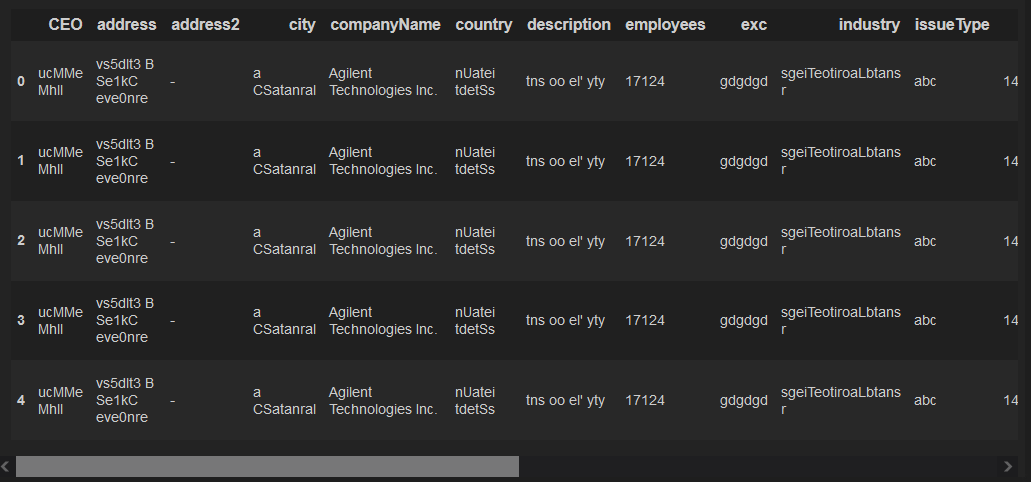
我希望只在 DataFrame 中看到 1 行,但它給出了 5。我不明白為什么。我在這里做錯了什么?
uj5u.com熱心網友回復:
你沒有做錯任何事。由于tags是一個串列,Pandas 將所有其他欄位廣播到與tags資料幀相同的大小并制作一個資料幀。你可以做:
pd.Series(your_dict).to_frame().T
或者將你的 dict 包裹起來,[]表明它是一行(記錄方向):
pd.DataFrame([your_dict])
uj5u.com熱心網友回復:
這是因為您的標簽行有 5 個,因此它嘗試“為其余部分填空”。要解決此問題,請在其周圍放置第二層括號,以便將其視為一行,而不是 5。
dff = pd.DataFrame(
{
'CEO': 'ucMMe Mhll',
'address': 'vs5dlt3 B Se1kC eve0nre',
'address2': '-',
'city': 'a CSatanral',
'companyName': 'Agilent Technologies Inc.',
'country': 'nUatei tdetSs',
'description': "tns oo el' yty",
'employees': 17124,
'exc': 'gdgdgd',
'industry': 'sgeiTeotiroaLbtans r',
'issueType': 'abc',
'phone': '14087832319',
'primarySicCode': 4008,
'sector': ',atnSii Scilcofe,nnse TecisaPliinafs cedorhv cre',
'securityName': 'elooIne.nen htc iisTcgAgl',
'state': 'ailairofnC',
'symbol': 'A',
'tags': [['nllh he', 'gth', 'acsl', 'isiad', 'nr aitT']], # Double brackets to indicate 1 cell
'website': 'win.gcm.',
'zip': '0752501-19'} )
uj5u.com熱心網友回復:
您可以將每個字典值包裝在一個串列中:
dff = pd.DataFrame({k: [v] for k,v in dct.items()})
>>> dff
CEO address ... website zip
0 ucMMe Mhll vs5dlt3 B Se1kC eve0nre ... win.gcm. 0752501-19
[1 rows x 20 columns]
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/370949.html
上一篇:將列名添加到csv檔案的行名
下一篇:R/Shiny:JSON閱讀庫