我有一個資料框,有兩種型別的行:SWITCH 和 RESULT 我的期望是洗掉相鄰的“SWITCH”并僅保留塊中的最后一個 SWITCH,但保留所有 RESULT 行。
我使用資料框 iterrows 做到了,我基本上是逐行掃描的。這不是pythonic。如果你看到更好的方法,你能提出建議嗎?下面是示例資料,以及我使用的代碼:
import pandas as pd
data = {'TYPE':['SWITCH','SWITCH','SWITCH',
'SWITCH','RESULT','RESULT','RESULT',
'RESULT','RESULT','SWITCH','SWITCH',
'RESULT','RESULT','RESULT','RESULT'],
'RESULT':['YES',
'NO','NO','YES',
'DONE','DONE','DONE',
'DONE','DONE','NO',
'YES','DONE','DONE',
'DONE','DONE']}
df = pd.DataFrame(data)
l = []
start=-1
for index, row in df.iterrows():
type = row["TYPE"]
if type == "RESULT":
if start == -1:
start = index
elif type == "SWITCH":
if start== -1:
df.drop(index=[*range(index, index 1, 1)], inplace=True)
continue
end = index-1
if start <= end:
df.drop(index=[*range(start,end,1)], inplace=True)
start = index 1
print(df)
剛剛檢查了輸出,發現我的代碼沒有做我想要的:
在應用代碼之前
由于索引 0~索引 3 都是“SWITCH”,我想洗掉索引 0/1/2 并只保留索引 3,因為這是一個“開關塊”同樣,對于索引 9/10,我想保留僅索引 10
TYPE RESULT
0 SWITCH YES
1 SWITCH NO
2 SWITCH NO
3 SWITCH YES
4 RESULT DONE
5 RESULT DONE
6 RESULT DONE
7 RESULT DONE
8 RESULT DONE
9 SWITCH NO
10 SWITCH YES
11 RESULT DONE
12 RESULT DONE
13 RESULT DONE
14 RESULT DONE
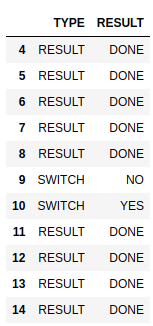
預期輸出:
TYPE RESULT
3 SWITCH YES
4 RESULT DONE
5 RESULT DONE
6 RESULT DONE
7 RESULT DONE
8 RESULT DONE
10 SWITCH YES
11 RESULT DONE
12 RESULT DONE
13 RESULT DONE
14 RESULT DONE
實際輸出:
TYPE RESULT
8 RESULT DONE
9 SWITCH NO
10 SWITCH YES
11 RESULT DONE
12 RESULT DONE
13 RESULT DONE
14 RESULT DONE
uj5u.com熱心網友回復:
如果我理解正確,對于每組連續的行,TYPE == "SWITCH"您要保留最后一行。這可以按如下方式完成:
df_processed = df[(df.TYPE != "SWITCH") | (df.TYPE.shift(-1) != "SWITCH")]
提供的示例資料的輸出是

uj5u.com熱心網友回復:
迭代資料幀的行被認為是不好的做法,應該避免。
我相信您正在尋找以下方面的東西:
# Get the rows where TYPE == RESULT
df_type_result = df[df['TYPE'] == 'RESULT']
# Get the last index when the result type == SWITCH
idxs = df.reset_index().groupby(['TYPE', 'RESULT']).last().loc['SWITCH']['index']
df_type_switch = df.loc[idxs]
# Concatenate and sort the results
df_result = pd.concat([df_type_result, df_type_switch]).sort_index()
df_result
uj5u.com熱心網友回復:
懶惰的解決方案
df["DROP"] = df["TYPE"].shift(-1)
df = df.loc[~((df["TYPE"]=="SWITCH")&(df["DROP"]=="SWITCH"))]
df.drop(columns="DROP", inplace=True)
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/370952.html
上一篇:如何使用pandas在特定列的csv檔案中查找特定單詞
下一篇:如何使用兩個物件創建R資料框?