在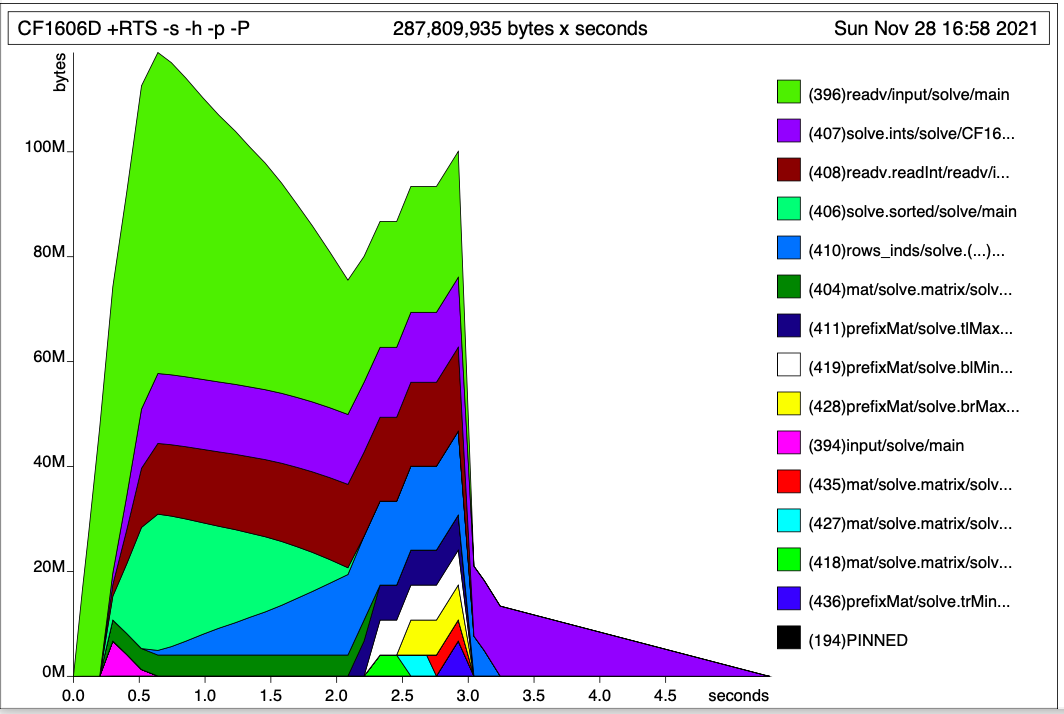
函式readvandreadv.readInt負責決議整數并將它們保存到二維串列中,大約需要 50-70 MB,而不是大約 16 MB =(10 6 個整數)×(每個整數 8 個位元組 每個鏈接 8 個位元組)。
有沒有希望我可以得到低于 256 MB 的總記憶體?我已經在使用Text包進行輸入。也許我應該完全避免使用串列并直接從標準輸入讀取整數到陣列。我們怎樣才能做到這一點?或者,是其他地方的問題嗎?
代碼
{-# OPTIONS_GHC -O2 #-}
module CF1606D where
import qualified Data.Text as T
import qualified Data.Text.IO as TI
import qualified Data.Text.Read as TR
import Control.Monad
import qualified Data.List as DL
import qualified Data.IntSet as DS
import Control.Monad.ST
import Data.Array.ST.Safe
import Data.Int (Int32)
import Data.Array.Unboxed
solve :: IO ()
solve = do
~[n,m] <- readv
-- 2D list
input <- {-# SCC input #-} replicateM (fromIntegral n) readv
let
ints = [1..]
sorted = DL.sortOn (head.fst) (zip input ints)
(rows,indices) = {-# SCC rows_inds #-} unzip sorted
-- 2D list converted into matrix:
matrix = mat (fromIntegral n) (fromIntegral m) rows
infinite = 10^7
asc x y = [x,x 1..y]
desc x y = [y,y-1..x]
-- Four prefix-matrices:
tlMax = runSTUArray $ prefixMat max 0 asc asc (subtract 1) (subtract 1) =<< matrix
blMin = runSTUArray $ prefixMat min infinite desc asc ( 1) (subtract 1) =<< matrix
trMin = runSTUArray $ prefixMat min infinite asc desc (subtract 1) ( 1) =<< matrix
brMax = runSTUArray $ prefixMat max 0 desc desc ( 1) ( 1) =<< matrix
good _ (i,j)
| tlMax!(i,j) < blMin!(i 1,j) && brMax!(i 1,j 1) < trMin!(i,j 1) = Left (i,j)
| otherwise = Right ()
{-# INLINABLE good #-}
nearAns = foldM good () [(i,j)|i<-[1..n-1],j<-[1..m-1]]
ans = either (\(i,j)-> "YES\n" color n (take i indices) " " show j) (const "NO") nearAns
putStrLn ans
type I = Int32
type S s = (STUArray s (Int, Int) I)
type R = Int -> Int -> [Int]
type F = Int -> Int
mat :: Int -> Int -> [[I]] -> ST s (S s)
mat n m rows = newListArray ((1,1),(n,m)) $ concat rows
prefixMat :: (I->I->I) -> I -> R -> R -> F -> F -> S s -> ST s (S s)
prefixMat opt worst ordi ordj previ prevj mat = do
((ilo,jlo),(ihi,jhi)) <- getBounds mat
pre <- newArray ((ilo-1,jlo-1),(ihi 1,jhi 1)) worst
forM_ (ordi ilo ihi) $ \i-> do
forM_ (ordj jlo jhi) $ \j -> do
matij <- readArray mat (i,j)
prei <- readArray pre (previ i,j)
prej <- readArray pre (i, prevj j)
writeArray pre (i,j) (opt (opt prei prej) matij)
return pre
color :: Int -> [Int] -> String
color n inds = let
temp = DS.fromList inds
colors = [if DS.member i temp then 'B' else 'R' | i<-[1..n]]
in colors
readv :: Integral t => IO [t]
readv = map readInt . T.words <$> TI.getLine where
readInt = fromIntegral . either (const 0) fst . TR.signed TR.decimal
{-# INLINABLE readv #-}
main :: IO ()
main = do
~[n] <- readv
replicateM_ n solve
上面代碼的快速描述:
- 讀取
n每個具有m整數的行。 - 按第一個元素對行進行排序。
- Now compute four 'prefix matrices', one from each corner. For top-left and bottom-right corners, it's the prefix-maximum, and for the other two corners, it's the prefix-minimum that we need to compute.
- Find a cell [i,j] at which these prefix matrices satisfy the following condition: top_left [i,j] < bottom_left [i,j] and top_right [i,j] > bottom_right [i,j]
- For rows 1 through i, mark their original indices (i.e. position in the unsorted input matrix) as Blue. Mark the rest as Red.
Sample input and Commands
Sample input: inp3.txt.
Command:
> stack ghc -- -main-is CF1606D.main -with-rtsopts="-s -h -p -P" -rtsopts -prof -fprof-auto CF1606D
> gtime -v ./CF1606D < inp3.txt > outp
...
...
MUT time 2.990s ( 3.744s elapsed) # RTS -s output
GC time 4.525s ( 6.231s elapsed) # RTS -s output
...
...
Maximum resident set size (kbytes): 408532 # >256 MB (gtime output)
> stack exec -- hp2ps -t0.1 -e8in -c CF1606D.hp && open CF1606D.ps
Question about GC: As shown above in the RTS -s output, GC seems to be taking longer than the actual logic execution. Is this normal? Is there a way to visualize the GC activity over time? I tried making matrices strict but that didn't have any impact.
Probably this is not a functional-friendly problem at all (although I'll be happy to be disproved on this). For example, Java uses GC too but there are lots of successful Java submissions. Still, I want to see how far I can push. Thanks!
uj5u.com熱心網友回復:
與普遍看法相反,Haskell 對此類問題非常友好。真正的問題是arrayGHC 附帶的庫完全是垃圾。另一個大問題是在 Haskell 中每個人都被教導在應該使用陣列的地方使用串列,這通常是代碼緩慢和記憶體膨脹程式的主要來源之一。因此,GC 需要很長時間也就不足為奇了,因為分配的東西太多了。下面是對下面提供的解決方案提供的輸入的運行:
1,483,547,096 bytes allocated in the heap
566,448 bytes copied during GC
18,703,640 bytes maximum residency (3 sample(s))
1,223,400 bytes maximum slop
32 MiB total memory in use (0 MB lost due to fragmentation)
Tot time (elapsed) Avg pause Max pause
Gen 0 1399 colls, 0 par 0.009s 0.009s 0.0000s 0.0011s
Gen 1 3 colls, 0 par 0.002s 0.002s 0.0006s 0.0016s
TASKS: 4 (1 bound, 3 peak workers (3 total), using -N1)
SPARKS: 0 (0 converted, 0 overflowed, 0 dud, 0 GC'd, 0 fizzled)
INIT time 0.001s ( 0.001s elapsed)
MUT time 0.484s ( 0.517s elapsed)
GC time 0.011s ( 0.011s elapsed)
EXIT time 0.001s ( 0.002s elapsed)
Total time 0.496s ( 0.530s elapsed)
下面提供的解決方案使用了一個陣列庫massiv,這使得無法提交給 codeforces。然而,希望目標是在 Haskell 上變得更好,而不是在某些網站上獲得積分。
紅藍矩陣可以分為兩個階段:讀取和求解
讀
閱讀尺寸
在main函式中,我們只讀取陣列的總數和每個陣列的維度。我們也列印結果。這里沒有什么令人興奮的。(請注意,鏈接的檔案inp3.txt具有比在該問題所定義的限制更大的陣列:n*m <= 10^6)
import Control.Monad.ST
import Control.Monad
import qualified Data.ByteString as BS
import Data.Massiv.Array as A hiding (B)
import Data.Massiv.Array.Mutable.Algorithms (quicksortByM_)
import Control.Scheduler (trivialScheduler_)
main :: IO ()
main = do
t <- Prelude.read <$> getLine
when (t < 1 || t > 1000) $ error $ "Invalid t: " show t
replicateM_ t $ do
dimsStr <- getLine
case Prelude.map Prelude.read (words dimsStr) of
-- Test file fails this check: && n * m <= 10 ^ (6 :: Int) -> do
[n, m] | n >= 2 && m > 0 && m <= 5 * 10 ^ (5 :: Int) -> do
mat <- readMatrix n m
case solve mat of
Nothing -> putStrLn "NO"
Just (ix, cs) -> do
putStrLn "YES"
putStr $ foldMap show cs
putStr " "
print ix
_ -> putStrLn $ "Unexpected dimensions: " show dimsStr
讀取陣列
將輸入加載到陣列中是原始問題中問題的主要來源:
- 無需依賴
text, ascii 字符是問題預期的唯一有效輸入。 - 輸入被讀入串列串列。該串列串列是記憶體開銷的真正來源。
- 排序串列的速度慢得離譜,而且很耗記憶體。
通常在這種情況下,使用類似conduit. 特別是,將輸入讀取為位元組流并將這些位元組決議為數字將是最佳解決方案。話雖如此,在問題描述中對每個陣列的寬度有嚴格的要求,因此我們可以將輸入逐行讀取為 aByteString然后決議每行中的數字(為簡單起見假設為無符號)并寫入這些數字同時進入陣列。這確保在這個階段我們將只分配結果陣列和一行作為位元組序列。這可以通過像 那樣的決議庫來完成attoparsec,但問題很簡單,只需臨時進行即可。
type Val = Word
readMatrix :: Int -> Int -> IO (Matrix P Val)
readMatrix n m = createArrayS_ (Sz2 n m) readMMatrix
readMMatrix :: MMatrix RealWorld P Val -> IO ()
readMMatrix mat =
loopM_ 0 (< n) ( 1) $ \i -> do
line <- BS.getLine
--- ^ reads at most 10Mb because it is known that input will be at most
-- 5*10^5 Words: 19 digits max per Word and one for space: 5*10^5 * 20bytes
loopM 0 (< m) ( 1) line $ \j bs ->
let (word, bs') = parseWord bs
in bs' <$ write_ mat (i :. j) word
where
Sz2 n m = sizeOfMArray mat
isSpace = (== 32)
isDigit w8 = w8 >= 48 && w8 <= 57
parseWord bs =
case BS.uncons bs of
Just (w8, bs')
| isDigit w8 -> parseWordLoop (fromIntegral (w8 - 48)) bs'
| otherwise -> error $ "Unexpected byte: " show w8
Nothing -> error "Unexpected end of input"
parseWordLoop !acc bs =
case BS.uncons bs of
Nothing -> (acc, bs)
Just (w8, bs')
| isSpace w8 -> (acc, bs')
| isDigit w8 -> parseWordLoop (acc * 10 fromIntegral (w8 - 48)) bs'
| otherwise -> error $ "Unexpected byte: " show w8
解決
這是我們實施實際解決方案的步驟。我沒有嘗試修復這個 SO 問題中提供的解決方案,而是繼續翻譯了問題中鏈接的C 解決方案。我走這條路的原因有兩個:
- C 解決方案是非常必要的,我想證明命令式陣列操作對 Haskell 來說并不是那么陌生,所以我嘗試創建一個盡可能接近的翻譯。
- 我知道解決方案有效
請注意,應該可以使用arraypackage重寫下面的解決方案,因為最終需要的只是read,write和allocate操作。
computeSortBy ::
(Load r Ix1 e, Manifest r' e)
=> (e -> e -> Ordering)
-> Vector r e
-> Vector r' e
computeSortBy f vec =
withLoadMArrayST_ vec $ quicksortByM_ (\x y -> pure $ f x y) trivialScheduler_
solve :: Matrix P Val -> Maybe (Int, [Color])
solve a = runST $ do
let sz@(Sz2 n m) = size a
ord :: Vector P Int
ord = computeSortBy
(\x y -> compare (a ! (y :. 0)) (a ! (x :. 0))) (0 ..: n)
mxl <- newMArray @P sz minBound
loopM_ (n - 1) (>= 0) (subtract 1) $ \ i ->
loopM_ 0 (< m) ( 1) $ \j -> do
writeM mxl (i :. j) (a ! ((ord ! i) :. j))
when (i < n - 1) $
writeM mxl (i :. j)
=<< max <$> readM mxl (i :. j) <*> readM mxl (i 1 :. j)
when (j > 0) $
writeM mxl (i :. j)
=<< max <$> readM mxl (i :. j) <*> readM mxl (i :. j - 1)
mnr <- newMArray @P sz maxBound
loopM_ (n - 1) (>= 0) (subtract 1) $ \ i ->
loopM_ (m - 1) (>= 0) (subtract 1) $ \ j -> do
writeM mnr (i :. j) (a ! ((ord ! i) :. j))
when (i < n - 1) $
writeM mnr (i :. j)
=<< min <$> readM mnr (i :. j) <*> readM mnr (i 1 :. j)
when (j < m - 1) $
writeM mnr (i :. j)
=<< min <$> readM mnr (i :. j) <*> readM mnr (i :. j 1)
mnl <- newMArray @P (Sz m) maxBound
mxr <- newMArray @P (Sz m) minBound
let goI i
| i < n - 1 = do
loopM_ 0 (< m) ( 1) $ \j -> do
val <- min (a ! ((ord ! i) :. j)) <$> readM mnl j
writeM mnl j val
when (j > 0) $
writeM mnl j . min val =<< readM mnl (j - 1)
loopM_ (m - 1) (>= 0) (subtract 1) $ \j -> do
val <- max (a ! ((ord ! i) :. j)) <$> readM mxr j
writeM mxr j val
when (j < m - 1) $
writeM mxr j . max val =<< readM mxr (j 1)
let goJ j
| j < m - 1 = do
mnlVal <- readM mnl j
mxlVal <- readM mxl (i 1 :. j)
mxrVal <- readM mxr (j 1)
mnrVal <- readM mnr ((i 1) :. (j 1))
if mnlVal > mxlVal && mxrVal < mnrVal
then pure $ Just (i, j)
else goJ (j 1)
| otherwise = pure Nothing
goJ 0 >>= \case
Nothing -> goI (i 1)
Just pair -> pure $ Just pair
| otherwise = pure Nothing
mAns <- goI 0
Control.Monad.forM mAns $ \ (ansFirst, ansSecond) -> do
resVec <- createArrayS_ @BL (Sz n) $ \res ->
iforM_ ord $ \i ordIx -> do
writeM res ordIx $! if i <= ansFirst then R else B
pure (ansSecond 1, A.toList resVec)
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/374170.html
標籤:arrays performance haskell stdin
上一篇:Haskell中的伯努利函式