背景
在某些場景,要求快速的DML,并且對資料可靠性要求不是非常高,
例如游戲的會話資訊,傳感器上傳的最新資料,運算的中間結果,等等,
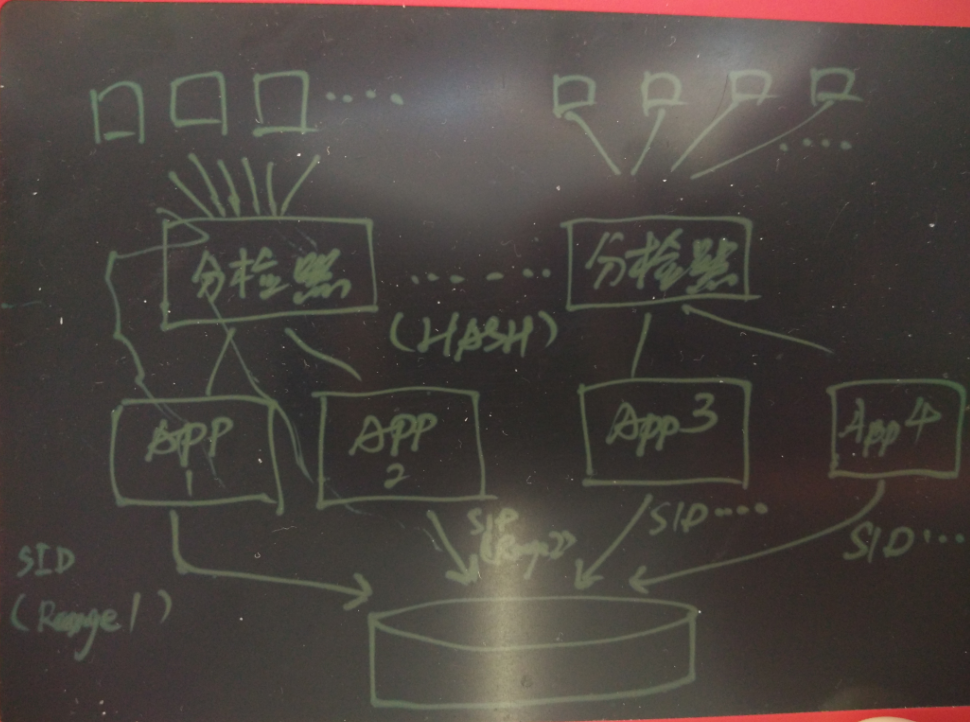
例如在一個場景中,有非常多的傳感器的資料要不斷的被更新和查詢,可以使用這種方法,每個傳感器的ID哈希后分配給對應的會話,這個傳感器,
上面的需求,PostgreSQL 臨時表都能滿足,
但是臨時表也存在一定的限制或弊端,
臨時表為會話級記憶體表,跨會話不共享資料和結構,不寫REDO,
超過一定大小時會落盤,不是純記憶體的,
同時臨時表繼承了普通表的多版本,但是實際上會話級不需要多版本,
會話斷開需要重建臨時表結構,
雖然現在的SSD IO能力很強,但是與記憶體還有一定的插件,同時SSD 擦寫次數受限,所以臨時表或者普通表難以滿足本文開頭提到的場景需求,
Oracle 12C 推出列存盤記憶體表,但是它是基于OLAP的應用場景,并不適合本文開頭提到的場景,
PostgreSQL 社區也在考慮增加記憶體表的功能,本文是一個引子,可以看到社區在這方面的努力,
PostgreSQL記憶體表之路
在postgrespro發表的postgres roadmap中,可以看到,他們正在搞熱插拔的存盤引擎,
https://wiki.postgresql.org/wiki/Postgres_Professional_roadmap
Pluggable storages
We achieved a significant progress in PostgreSQL extendability: FDWs, custom access methods, generic WAL. And we're not so far from having pluggable storage engines. Concept of API will be presented at PGCon. We are planning to implement the following types of storage engines: In-memory row-oriented storage engine with optional support of transactions and optional support of persistency; Columnar storage engine; In-memory columnar storage engine; On-disk row-oriented storage engine with undo-log for better bloat control.
行式記憶體引擎、列式記憶體引擎、列存磁盤存盤引擎、以及回滾段模式的行式磁盤存盤引擎,
目前還沒有看到代碼方面的輸出,但是在postgrespro的專案里有一個與記憶體表非常類似的專案,會話級變數,
資料保存在記憶體中,目前支持如下操作
https://github.com/postgrespro/pg_variables
操作看起來是不是有點像redis呢?
Integer variables
| Function | Returns |
|---|---|
pgv_set_int(package text, name text, value int) |
void |
pgv_get_int(package text, name text, strict bool default true) |
int |
Text variables
| Function | Returns |
|---|---|
pgv_set_text(package text, name text, value text) |
void |
pgv_get_text(package text, name text, strict bool default true) |
text |
Numeric variables
| Function | Returns |
|---|---|
pgv_set_numeric(package text, name text, value numeric) |
void |
pgv_get_numeric(package text, name text, strict bool default true) |
numeric |
Timestamp variables
| Function | Returns |
|---|---|
pgv_set_timestamp(package text, name text, value timestamp) |
void |
pgv_get_timestamp(package text, name text, strict bool default true) |
timestamp |
Timestamp with timezone variables
| Function | Returns |
|---|---|
pgv_set_timestamptz(package text, name text, value timestamptz) |
void |
pgv_get_timestamptz(package text, name text, strict bool default true) |
timestamptz |
Date variables
| Function | Returns |
|---|---|
pgv_set_date(package text, name text, value date) |
void |
pgv_get_date(package text, name text, strict bool default true) |
date |
Jsonb variables
| Function | Returns |
|---|---|
pgv_set_jsonb(package text, name text, value jsonb) |
void |
pgv_get_jsonb(package text, name text, strict bool default true) |
jsonb |
同樣支持集合哦
Records
The following functions are provided by the module to work with collections of record types.
To use pgv_update(), pgv_delete() and pgv_select() functions required package and variable must exists.
Otherwise the error will be raised.
It is necessary to set variable with pgv_insert() function to use these functions.
pgv_update(), pgv_delete() and pgv_select() functions check the variable type.
If the variable type does not record type the error will be raised.
| Function | Returns | Description |
|---|---|---|
pgv_insert(package text, name text, r record) |
void |
Inserts a record to the variable collection. If package and variable do not exists they will be created. The first column of r will be a primary key. If exists a record with the same primary key the error will be raised. If this variable collection has other structure the error will be raised. |
pgv_update(package text, name text, r record) |
boolean |
Updates a record with the corresponding primary key (the first column of r is a primary key). Returns true if a record was found. If this variable collection has other structure the error will be raised. |
pgv_delete(package text, name text, value anynonarray) |
boolean |
Deletes a record with the corresponding primary key (the first column of r is a primary key). Returns true if a record was found. |
pgv_select(package text, name text) |
set of record |
Returns the variable collection records. |
pgv_select(package text, name text, value anynonarray) |
record |
Returns the record with the corresponding primary key (the first column of r is a primary key). |
pgv_select(package text, name text, value anyarray) |
set of record |
Returns the variable collection records with the corresponding primary keys (the first column of r is a primary key). |
下面更像redis了
Miscellaneous functions
| Function | Returns | Description |
|---|---|---|
pgv_exists(package text, name text) |
bool |
Returns true if package and variable exists. |
pgv_remove(package text, name text) |
void |
Removes the variable with the corresponding name. Required package and variable must exists, otherwise the error will be raised. |
pgv_remove(package text) |
void |
Removes the package and all package variables with the corresponding name. Required package must exists, otherwise the error will be raised. |
pgv_free() |
void |
Removes all packages and variables. |
pgv_list() |
table(package text, name text) |
Returns set of records of assigned packages and variables. |
pgv_stats() |
table(package text, used_memory bigint) |
Returns list of assigned packages and used memory in bytes. |
Note that pgv_stats() works only with the PostgreSQL 9.6 and newer.
目前資料僅支持會話級,會話斷開則自動釋放,期待真正的記憶體表引擎吧,這只是個引子,
存盤邏輯結構

術語
package : 包名
name : 變數名
value : 標量型別的值
r : 集合型別的單條記錄
pk : 集合型別的主鍵
測驗
安裝記憶體表插件
export PATH=/home/digoal/pgsql9.6/bin:$PATH git clone https://github.com/postgrespro/pg_variables cd pg_variables/ make USE_PGXS=1 make USE_PGXS=1 install make USE_PGXS=1 installcheck postgres=# create extension pg_variables; CREATE EXTENSION
標量測驗
postgres=# select pgv_set_int('pkg1','k1',100); pgv_set_int ------------- (1 row) postgres=# select pgv_get_int('pkg1','k1'); pgv_get_int ------------- 100 (1 row) postgres=# select pgv_set_jsonb('pkg1','k2','{"a":"b", "c":{"hello":"digoal"}}'); pgv_set_jsonb --------------- (1 row) postgres=# select pgv_get_jsonb('pkg1','k2'); pgv_get_jsonb -------------------------------------- {"a": "b", "c": {"hello": "digoal"}} (1 row)
更新與自增用法
postgres=# select pgv_set_int(pkg,k, pgv_get_int(pkg,k)+1 ) from (values ('pkg1','k1')) t(pkg,k); pgv_set_int ------------- (1 row) postgres=# select pgv_get_int('pkg1','k1'); pgv_get_int ------------- 102 (1 row) postgres=# select pgv_set_int(pkg,k, pgv_get_int(pkg,k)+1 ) from (values ('pkg1','k1')) t(pkg,k); pgv_set_int ------------- (1 row) postgres=# select pgv_get_int('pkg1','k1'); pgv_get_int ------------- 103 (1 row)
性能,每秒標量更新達到了239萬次,
postgres=# select count(*) from (select pgv_set_int('pkg1','k1',id) from generate_series(1,10000000) t(id) ) t; count ---------- 10000000 (1 row) Time: 4185.179 ms postgres=# select pgv_get_int('pkg1','k1'); pgv_get_int ------------- 10000000 (1 row) Time: 0.470 ms postgres=# select 10000000/4.185; ?column? ---------------------- 2389486.260454002389 (1 row) Time: 0.869 ms
集合測驗
postgres=# select pgv_insert('pkg2', 'k1', row(1::int, 'hello world'::text, current_date::date)); pgv_insert ------------ (1 row) postgres=# select * from pgv_select('pkg2', 'k1') as t(c1 int,c2 text,c3 date); c1 | c2 | c3 ----+-------------+------------ 1 | hello world | 2016-08-18 (1 row) postgres=# select count(*) from (select pgv_insert('pkg2', 'k1', row(c1,'test'::text,current_date::date)) from generate_series(2,100000) t(c1)) t; count ------- 99999 (1 row) postgres=# select * from pgv_select('pkg2', 'k1', array[1,2,3]) as t(c1 int,c2 text,c3 date); c1 | c2 | c3 ----+-------------+------------ 1 | hello world | 2016-08-18 2 | test | 2016-08-18 3 | test | 2016-08-18 (3 rows)
記憶體表和普通表的JOIN
postgres=# select t1.*,t2.* from (select * from pgv_select('pkg2', 'k1') as t(c1 int,c2 text,c3 date)) t1, tbl1 t2 where t1.c1=t2.id and t2.id<10; c1 | c2 | c3 | id | info ----+-------------+------------+----+---------------------------------- 8 | test | 2016-08-18 | 8 | a8a7e0f849c5895820bbca32d7e798b1 4 | test | 2016-08-18 | 4 | f6954fb12336881d590fa7a50dd03916 9 | test | 2016-08-18 | 9 | 45ff843fcd5372e525368829f9846def 5 | test | 2016-08-18 | 5 | d8afe53f0a7d553716caa9ffaef7ea3d 7 | test | 2016-08-18 | 7 | 2b20f485974500d7b3ecb1f4c1d0f975 2 | test | 2016-08-18 | 2 | 3d36418926b2e0e2dc7090da17e39451 6 | test | 2016-08-18 | 6 | 6923416bbca7634f01f7f79030609f64 1 | hello world | 2016-08-18 | 1 | 3bb6c833f1b10139edf7e2f2eb4f4a69 3 | test | 2016-08-18 | 3 | de5b51374e1db3ccac9c61af75b69a33 (9 rows)
更新與洗掉記憶體表的資料
postgres=# select pgv_update('pkg2', 'k1', t) from (select c1,'new val'::text,'2017-01-01'::date from pgv_select('pkg2', 'k1', 1) as tb(c1 int, c2 text, c3 date)) t; pgv_update ------------ t (1 row) Time: 0.665 ms postgres=# select * from pgv_select('pkg2', 'k1', 1) as tb(c1 int, c2 text, c3 date); c1 | c2 | c3 ----+---------+------------ 1 | new val | 2017-01-01 (1 row) Time: 0.518 ms postgres=# select pgv_delete('pkg2', 'k1', 1); pgv_delete ------------ t (1 row) Time: 0.440 ms
管理記憶體物件
postgres=# select * from pgv_exists('pkg1','k1'); pgv_exists ------------ f (1 row) Time: 0.491 ms postgres=# select pgv_list(); pgv_list ----------- (pkg2,k1) (1 row) Time: 0.455 ms postgres=# select pgv_stats(); pgv_stats ----------------- (pkg2,16785408) (1 row) Time: 0.514 ms postgres=# select pgv_remove('pkg2','k1'); pgv_remove ------------ (1 row) Time: 1.868 ms postgres=# select pgv_stats(); pgv_stats -------------- (pkg2,24576) (1 row) Time: 0.367 ms postgres=# select pgv_remove('pkg2'); pgv_remove ------------ (1 row) Time: 0.415 ms postgres=# select pgv_stats(); pgv_stats ----------- (0 rows) Time: 0.369 ms
資料持久化
postgres=# select count(*) from (select pgv_insert('pkg2', 'k1', row(c1,'test'::text,current_date::date)) from generate_series(2,10000000) t(c1)) t; count --------- 9999999 (1 row) 在事務中持久化資料 postgres=# begin; postgres=# create table tbl as select * from pgv_select('pkg2','k1') as t(c1 int, c2 text, c3 date); postgres=# end; postgres=# select count(*) from tbl; count --------- 9999999 (1 row)
PostgreSQL 記憶體表
本文來自博客園,作者:古道輕風,轉載請注明原文鏈接:https://www.cnblogs.com/88223100/p/PostgreSQL_Memory_Table.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/374422.html
標籤:PostgreSQL
上一篇:時序資料庫有哪些特點? TimescaleDB時序資料庫介紹
下一篇:pg_probackup