目錄
- 一、HAVING 子句
- 二、HAVING 子句的構成要素
- 三、相對于 HAVING 子句,更適合寫在 WHERE 子句中的條件
- 請參閱
學習重點
使用
COUNT函式等對表中資料進行匯總操作時,為其指定條件的不是WHERE子句,而是HAVING子句,聚合函式可以在
SELECT子句、HAVING子句和ORDER BY子句中使用,
HAVING子句要寫在GROUP BY子句之后,
WHERE子句用來指定資料行的條件,HAVING子句用來指定分組的條件,
一、HAVING 子句
使用前一節學過的 GROUP BY 子句,可以得到將表分組后的結果,在此,我們來思考一下通過指定條件來選取特定組的方法,例如,如何才能取出“聚合結果正好為 2 行的組”呢(圖 8)?
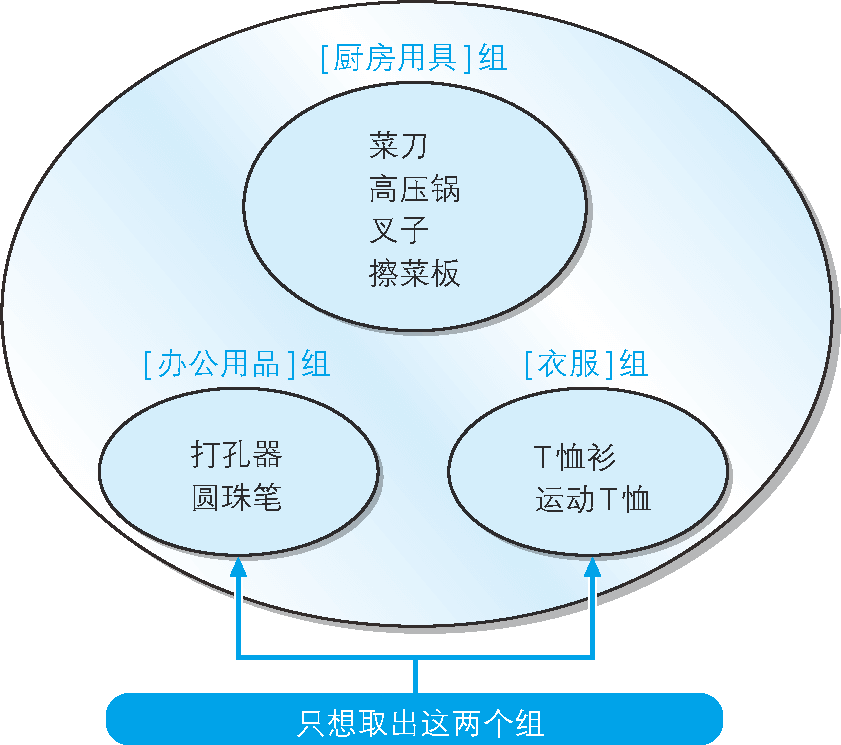
圖 8 取出符合指定條件的組
說到指定條件,估計大家都會首先想到 WHERE 子句,但是,WHERE 子句只能指定記錄(行)的條件,而不能用來指定組的條件(例如,“資料行數為 2 行”或者“平均值為 500”等),
因此,對集合指定條件就需要使用其他的子句了,此時便可以用 HAVING 子句 [1],
KEYWORD
HAVING子句
HAVING 子句的語法如下所示,
語法 3 HAVING 子句
SELECT <列名1>, <列名2>, <列名3>, ……
FROM <表名>
GROUP BY <列名1>, <列名2>, <列名3>, ……
HAVING <分組結果對應的條件>
HAVING 子句必須寫在 GROUP BY 子句之后,其在 DBMS 內部的執行順序也排在 GROUP BY 子句之后,
? 使用 HAVING 子句時 SELECT 陳述句的順序
SELECT → FROM → WHERE → GROUP BY → HAVING
法則 13
HAVING子句要寫在GROUP BY子句之后,
接下來就讓我們練習一下 HAVING 子句吧,例如,針對按照商品種類進行分組后的結果,指定“包含的資料行數為 2 行”這一條件的 SELECT 陳述句,請參見代碼清單 20,
代碼清單 20 從按照商品種類進行分組后的結果中,取出“包含的資料行數為2行”的組
SELECT product_type, COUNT(*)
FROM Product
GROUP BY product_type
HAVING COUNT(*) = 2;
執行結果
product_type | count
--------------+------
衣服 | 2
辦公用品 | 2
我們可以看到執行結果中并沒有包含資料行數為 4 行的“廚房用具”,未使用 HAVING 子句時的執行結果中包含“廚房用具”,但是通過設定 HAVING 子句的條件,就可以選取出只包含 2 行資料的組了(代碼清單 21),
代碼清單 21 不使用 HAVING 子句的情況
SELECT product_type, COUNT(*)
FROM Product
GROUP BY product_type;
執行結果

下面我們再來看一個使用 HAVING 子句的例子,這次我們還是按照商品種類對表進行分組,但是條件變成了“銷售單價的平均值大于等于 2500 日元”,
首先來看一下不使用 HAVING 子句的情況,請參見代碼清單 22,
代碼清單 22 不使用 HAVING 子句的情況
SELECT product_type, AVG(sale_price)
FROM Product
GROUP BY product_type;
執行結果
product_type | avg
--------------+----------------------
衣服 | 2500.0000000000000000
辦公用品 | 300.0000000000000000
廚房用具 | 2795.0000000000000000
按照商品種類進行切分的 3 組資料都顯示出來了,下面我們使用 HAVING 子句來設定條件,請參見代碼清單 23,
代碼清單 23 使用 HAVING 子句設定條件的情況
SELECT product_type, AVG(sale_price)
FROM Product
GROUP BY product_type
HAVING AVG(sale_price) >= 2500;
執行結果
product_type | avg
--------------+----------------------
衣服 | 2500.0000000000000000
廚房用具 | 2795.0000000000000000
銷售單價的平均值為 300 日元的“辦公用品”在結果中消失了,
二、HAVING 子句的構成要素
HAVING 子句和包含 GROUP BY 子句時的 SELECT 子句一樣,能夠使用的要素有一定的限制,限制內容也是完全相同的,HAVING 子句中能夠使用的 3 種要素如下所示,
-
常數
-
聚合函式
-
GROUP BY子句中指定的列名(即聚合鍵)
代碼清單 20 中的例文指定了 HAVING COUNT(*)= 2 這樣的條件,其中 COUNT(*) 是聚合函式,2 是常數,全都滿足上述要求,反之,如果寫成了下面這個樣子就會發生錯誤(代碼清單 24),
代碼清單 24 HAVING 子句的不正確使用方法
SELECT product_type, COUNT(*)
FROM Product
GROUP BY product_type
HAVING product_name = '圓珠筆';
執行結果
ERROR: 列"product,product_name"必須包含在GROUP BY子句當中,或者必須在聚合函式中使用
行 4: HAVING product_name = '圓珠筆';
product_name 列并不包含在 GROUP BY 子句之中,因此不允許寫在 HAVING 子句里,在思考 HAVING 子句的使用方法時,把一次匯總后的結果(類似表 2 的表)作為 HAVING 子句起始點的話更容易理解,
表 2 按照商品種類分組后的結果
product_type |
COUNT(*) |
|---|---|
| 廚房用具 | 4 |
| 衣服 | 2 |
| 辦公用品 | 2 |
可以把這種情況想象為使用 GROUP BY 子句時的 SELECT 子句,匯總之后得到的表中并不存在 product_name 這個列,SQL 當然無法為表中不存在的列設定條件了,
三、相對于 HAVING 子句,更適合寫在 WHERE 子句中的條件
也許有的讀者已經發現了,有些條件既可以寫在 HAVING 子句當中,又可以寫在 WHERE 子句當中,這些條件就是聚合鍵所對應的條件,原表中作為聚合鍵的列也可以在 HAVING 子句中使用,因此,代碼清單 25 中的 SELECT 陳述句也是正確的,
代碼清單 25 將條件書寫在 HAVING 子句中的情況
SELECT product_type, COUNT(*)
FROM Product
GROUP BY product_type
HAVING product_type = '衣服';
執行結果
product_type | count
--------------+------
衣服 | 2
上述 SELECT 陳述句的回傳結果與代碼清單 26 中 SELECT 陳述句的回傳結果是相同的,
代碼清單 26 將條件書寫在 WHERE 子句中的情況
SELECT product_type, COUNT(*)
FROM Product
WHERE product_type = '衣服'
GROUP BY product_type;
執行結果
product_type | count
--------------+------
衣服 | 2
雖然條件分別寫在 WHERE 子句和 HAVING 子句當中,但是條件的內容以及回傳的結果都完全相同,因此,大家可能會覺得兩種書寫方式都沒問題,
如果僅從結果來看的話,確實如此,但筆者卻認為,聚合鍵所對應的條件還是應該書寫在 WHERE 子句之中,
理由有兩個,
首先,根本原因是 WHERE 子句和 HAVING 子句的作用不同,如前所述,HAVING 子句是用來指定“組”的條件的,因此,“行”所對應的條件還是應該寫在 WHERE 子句當中,這樣一來,書寫出的 SELECT 陳述句不但可以分清兩者各自的功能,理解起來也更加容易,
WHERE 子句 = 指定行所對應的條件
HAVING 子句 = 指定組所對應的條件
其次,對初學者來說,研究 DBMS 的內部實作這一話題有些深奧,這里就不做介紹了,感興趣的讀者可以參考隨后的專欄——WHERE 子句和 HAVING 子句的執行速度,
法則 14
聚合鍵所對應的條件不應該書寫在
HAVING子句當中,而應該書寫在WHERE子句當中,
專欄
WHERE子句和HAVING子句的執行速度在
WHERE子句和HAVING子句中都可以使用的條件,最好寫在WHERE子句中的另一個理由與性能即執行速度有關系,由于性能不在本教程介紹的范圍之內,因此暫不進行說明,通常情況下,為了得到相同的結果,將條件寫在WHERE子句中要比寫在HAVING子句中的處理速度更快,回傳結果所需的時間更短,為了理解其中原因,就要從 DBMS 的內部運行機制來考慮,使用
COUNT函式等對表中的資料進行聚合操作時,DBMS 內部就會進行排序處理,排序處理是會大大增加機器負擔的高負荷的處理[2],因此,只有盡可能減少排序的行數,才能提高處理速度,通過
WHERE子句指定條件時,由于排序之前就對資料進行了過濾,因此能夠減少排序的資料量,但HAVING子句是在排序之后才對資料進行分組的,因此與在WHERE子句中指定條件比起來,需要排序的資料量就會多得多,雖然 DBMS 的內部處理不盡相同,但是對于排序處理來說,基本上都是一樣的,此外,
WHERE子句更具速度優勢的另一個理由是,可以對WHERE子句指定條件所對應的列創建索引,這樣也可以大幅提高處理速度,創建索引是一種非常普遍的提高 DBMS 性能的方法,效果也十分明顯,這對WHERE子句來說也十分有利,KEYWORD
- 索引(index)
請參閱
- 對表進行聚合查詢
- 對表進行分組
- 為聚合結果指定條件
- 對查詢結果進行排序
(完)
HAVING是 HAVE( 擁有 )的現在分詞,并不是通常使用的英語單詞, ??雖然 Oracle 等資料庫會使用散列(hash)處理來代替排序,但那同樣也是加重機器負擔的處理, ??
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/374428.html
標籤:SQL Server