我正在嘗試將sklearn 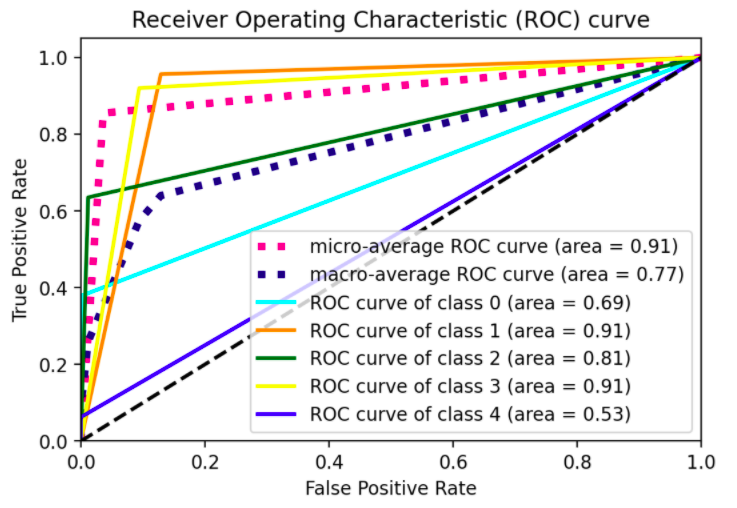
那種直線彎曲一次。我想看看不同閾值下的模型性能,而不僅僅是一個,類似于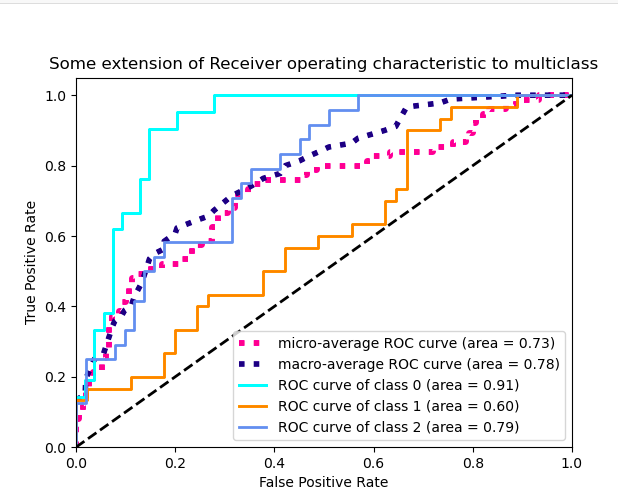
uj5u.com熱心網友回復:
重點是您使用
predict()而不是predict_proba()/decision_function()來定義您的y_hat. 這意味著 - 考慮到閾值向量是由中的不同值的數量定義的y_hat(請參閱此處以供參考),每個類別的閾值很少,并且僅在其上計算(這反過來意味著您的曲線在只有幾點)。tprfpr事實上,考慮一下檔案所說的傳遞給
y_scoresin 的內容roc_curve(),無論是概率估計還是決策值。在來自 的示例中sklearn,決策值用于計算分數。鑒于您正在考慮 aRandomForestClassifier(),考慮您的概率估計y_hat應該是要走的路。那么對輸出進行標簽二值化有什么意義呢?ROC 的標準定義是二進制分類。要傳遞到多類問題,您必須使用 OneVsAll 方法將您的問題轉換為二元問題,以便您擁有
n_class大量 ROC 曲線。(實際上,請注意,因為SVC()默認情況下以 OvO 方式處理多類問題,在示例中,他們不得不通過應用OneVsRestClassifier建構式強制使用 OvA ;使用 aRandomForestClassifier你沒有這樣的問題,因為那是固有的多類問題,請參閱此處以供參考) . 在這些方面,一旦你切換到predict_proba()你會發現標簽二值化預測沒有多大意義。# all imports import numpy as np import matplotlib.pyplot as plt from itertools import cycle from sklearn import svm, datasets from sklearn.metrics import roc_curve, auc from sklearn.model_selection import train_test_split from sklearn.preprocessing import label_binarize from sklearn.datasets import make_classification from sklearn.ensemble import RandomForestClassifier # dummy dataset X, y = make_classification(10000, n_classes=5, n_informative=10, weights=[.04, .4, .12, .5, .04]) train, test, ytrain, ytest = train_test_split(X, y, test_size=.3, random_state=42) # random forest model model = RandomForestClassifier() model.fit(train, ytrain) yhat = model.predict_proba(test) def plot_roc_curve(y_test, y_pred): n_classes = len(np.unique(y_test)) y_test = label_binarize(y_test, classes=np.arange(n_classes)) # Compute ROC curve and ROC area for each class fpr = dict() tpr = dict() roc_auc = dict() thresholds = dict() for i in range(n_classes): fpr[i], tpr[i], thresholds[i] = roc_curve(y_test[:, i], y_pred[:, i], drop_intermediate=False) roc_auc[i] = auc(fpr[i], tpr[i]) # Compute micro-average ROC curve and ROC area fpr["micro"], tpr["micro"], _ = roc_curve(y_test.ravel(), y_pred.ravel()) roc_auc["micro"] = auc(fpr["micro"], tpr["micro"]) # First aggregate all false positive rates all_fpr = np.unique(np.concatenate([fpr[i] for i in range(n_classes)])) # Then interpolate all ROC curves at this points mean_tpr = np.zeros_like(all_fpr) for i in range(n_classes): mean_tpr = np.interp(all_fpr, fpr[i], tpr[i]) # Finally average it and compute AUC mean_tpr /= n_classes fpr["macro"] = all_fpr tpr["macro"] = mean_tpr roc_auc["macro"] = auc(fpr["macro"], tpr["macro"]) # Plot all ROC curves #plt.figure(figsize=(10,5)) plt.figure(dpi=600) lw = 2 plt.plot(fpr["micro"], tpr["micro"], label="micro-average ROC curve (area = {0:0.2f})".format(roc_auc["micro"]), color="deeppink", linestyle=":", linewidth=4,) plt.plot(fpr["macro"], tpr["macro"], label="macro-average ROC curve (area = {0:0.2f})".format(roc_auc["macro"]), color="navy", linestyle=":", linewidth=4,) colors = cycle(["aqua", "darkorange", "darkgreen", "yellow", "blue"]) for i, color in zip(range(n_classes), colors): plt.plot(fpr[i], tpr[i], color=color, lw=lw, label="ROC curve of class {0} (area = {1:0.2f})".format(i, roc_auc[i]),) plt.plot([0, 1], [0, 1], "k--", lw=lw) plt.xlim([0.0, 1.0]) plt.ylim([0.0, 1.05]) plt.xlabel("False Positive Rate") plt.ylabel("True Positive Rate") plt.title("Receiver Operating Characteristic (ROC) curve") plt.legend()
最后,請考慮它roc_curve()還有一個drop_intermediate用于丟棄次優閾值的引數(了解它可能很有用)。
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/377464.html
標籤:Python 机器学习 scikit-学习 鹏 auc
上一篇:基于事件日期前一個月的聚合