當我閱讀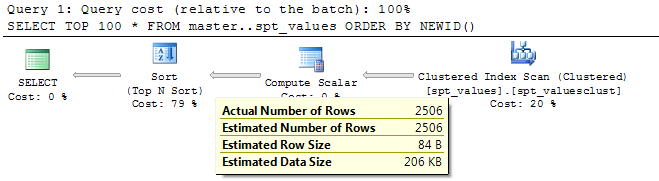
查詢計劃也是我的本地 SSMS 副本提供給我的,它為每一行分配一個隨機的 guid 值,但此分配將生成一個結果集,該結果集遵循我在執行SELECT * FROM whatever_table.
是的,除非order by使用sql,否則不保證結果集的任何順序,但我見過的幾乎所有實作都回傳一個與插入順序(即磁盤上資料的物理布局)強烈重疊的結果集,這是出于明顯的 IO 效率原因.
由于SQL Server使用TOP N Sort,這意味著它會只是隨機化的順序頂部N的結果集,我會用得到的行SELECT * FROM whatever_table。這在某種程度上是每次運行查詢時或多或少相同結果集的隨機排序,而不是整個表中行的隨機化。
然而,這個對不同問題的回答會過濾掉整個表格行中隨機生成的值并隨機化選擇。
我錯了嗎?
更新:
當然我錯了。我的錯誤在于我對如何TOP N Sort運作的錯誤假設。我認為它需要N結果集的第一行,然后對該子集進行排序。相反,它會找到最大值(如果order by newid() asc使用的話,大概是最小值)并在找到值時停止尋找下一個值N。感謝您的評論讓我看到了我的想法錯誤。
uj5u.com熱心網友回復:
ORDER BY有兩個不同的目的。它可用于對查詢回傳給客戶端的行進行排序。并且它可以用來幫助定義在定義TOPor OFFSET ... FETCH(也是視窗函式)時要考慮的順序。
在某些情況下,就像這里一樣,它被用于兩者。該TOP子句查找頂部行,首先考慮該ORDER BY子句定義的請求排序順序。由于這ORDER BY也是ORDER BY最外層查詢,因此它也用于定義將行回傳給客戶端1的順序。
在其他情況下,當諸如TOP或OFFSET ... FETCH在子查詢中使用時,對應的ORDER BY是僅用于確定哪些行被包括在子查詢,并且它具有在其回傳的最后完整的行的順序沒有正式的影響。
1并且許多實作將嘗試通過選擇適當的索引或至少僅對行進行一次排序來實作這兩個目的來利用這種組合性質。
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/379985.html
標籤:sql sql-server
上一篇:獲取沒有架構的表名
下一篇:TypeError:WebDriver.__init__()在SeleniumPython中使用firefox_options作為引數得到了意外的關鍵字引數“firefox_options”錯誤