我得到了以下形式的 .csv 檔案:
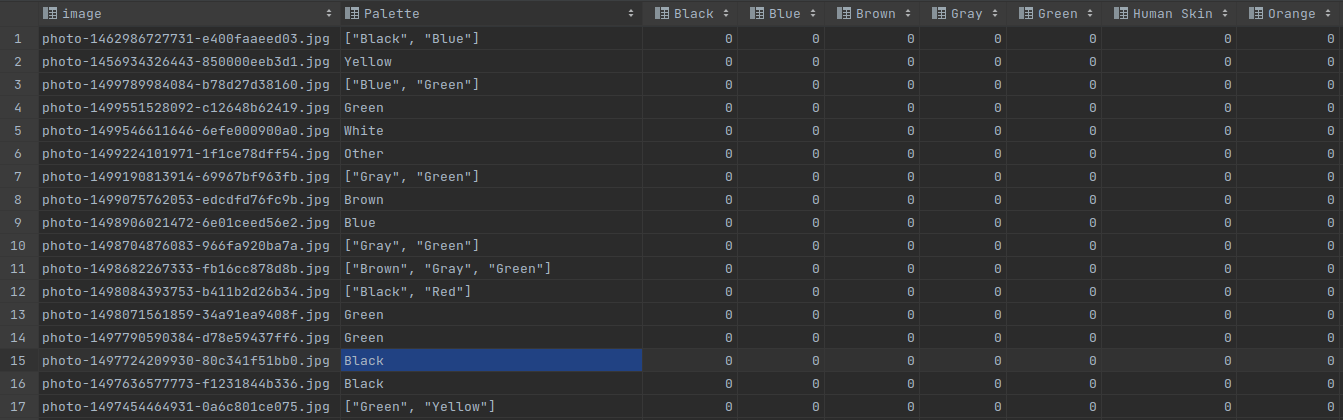
當我在“調色板”部分找到它時,我需要決議整個 csv 檔案并將相應顏色的 0 替換為 1。
例如,對于第一行,影像的“調色板”部分有 2 個值,“黑色”和“藍色”。我需要用 1 替換同一行中的相應顏色(所以黑色和藍色部分)。
任何幫助,將不勝感激。
謝謝
uj5u.com熱心網友回復:
我有一些東西,但我不確定它會如何擴展。
測驗資料框:
df = pd.DataFrame({
"image" : ['photo1', 'photo2', 'photo3', 'photo4'],
"palette" : ['["Black", "Blue"]', 'Yellow', 'Black', '["Yellow", "Blue"]']
})
輸出:
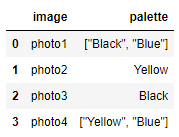
第一步:將字串轉換為實際串列。
def wrap_eval(x):
try:
return eval(x)
except:
return [x]
df["palette"] = df["palette"].apply(wrap_eval)
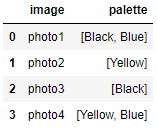
輸出; 它看起來非常相似,但是如果您檢查例如,df.loc[0, "palatte"],您將看到我們現在有一個字串串列,而不是一個看起來像串列的字串:
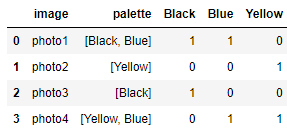
現在,我們將向下迭代行,(1)測驗以查看每行的“調色板”串列中的每種顏色是否存在一列,(2)如果不存在,則添加該列,并帶有值一直向下為零,最后 (3),該列現在將存在,因此將其在此行中的值設定為 1。
for i, row in df.iterrows():
for colour in row["palette"]:
try:
df[colour] # (1) in the steps above.
except:
df[colour] = 0 # (2)
finally:
df.loc[i, colour] = 1 # (3)
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/380611.html
上一篇:當行名和列名彼此相等時用零替換值