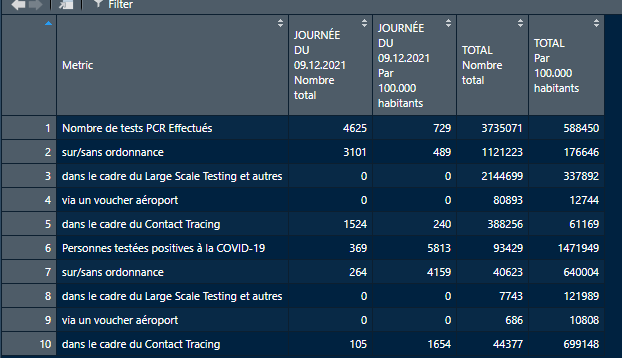
我是使用 r 進行網路抓取的新手,我正在嘗試獲取可能不是文本的每日更新物件。url在
備用:
如果您只是想提取專案,那么您可以將每一列提取為串列中的一個專案。替換 br 元素,使這些元素中的內容以逗號分隔的串列結尾:
library(rvest)
library(magrittr)
library(stringi)
library(xml2)
page <- read_html("https://covid19.public.lu/en.html")
xml_find_all(page, ".//br") %>% xml_add_sibling("span", ",") #This method from https://stackoverflow.com/a/46755666 @hrbrmstr
xml_find_all(page, ".//br") %>% xml_remove()
columns <- page %>% html_elements(".cmp-gridStat__item")
map(columns, ~ .x %>%
html_elements("p") %>%
html_text(trim = T) %>%
gsub("\n\\s{2,}", " ", .)
%>%
stri_remove_empty())
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/381182.html