聯合索引的最左前綴原則屬于面試高頻題,想必大部分同學都知道一些,但是,那些不符合最左前綴的部分,會怎么樣呢(索引下推)
索引下推不算高頻題,知道的同學應該不是很多(不過并不代表有啥難度哈,挺簡單的),學起來裝波杯

老規矩,背誦版在文末,點擊 大廠面試火箭計劃 可以直達我收錄整理的各大廠面試真題
引子
看下面這張用戶表,包含主鍵 id、身份證號 id_card、姓名 name、年齡 age和性別 sex,并且在 id_card 上建立了輔助索引(普通索引/非聚集索引)
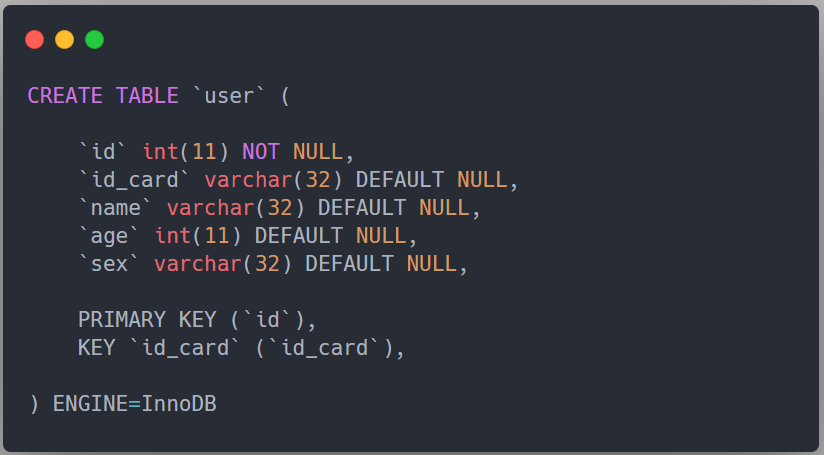
如果現在有一個高頻請求,要根據市民的身份證號查詢他的姓名:
select name from user where id_card = xxx;
眾所周知,這會導致回表查詢,通過 id_card 這棵輔助索引樹只能找到主鍵 id,然后需要再回到主鍵索引(聚集索引)樹上根據主鍵 id 查找相應的 name,
所以,這個時候,我們可以建立一個 (id_card, name) 的聯合索引來進行優化,對于這條陳述句來說,也就是覆寫索引,在這個高頻請求上用到覆寫索引,不再需要回表查整行記錄,大幅減少了陳述句的執行時間,
不過,索引欄位的維護總是有代價的,如果為每一種查詢都設計一個聯合索引,索引是不是太多了?反過來說,單獨為一個不頻繁的請求創建一個聯合索引是不是有點浪費了,因此在建立冗余索引來支持覆寫索引時就需要我們去做出一些權衡考慮了,
具體來說,我們應該怎么做呢?
最左前綴原則
B+ 樹這種索引結構,可以利用聯合索引的 “最左前綴” 來定位記錄,
何為聯合索引的最左前綴原則?
從本質上來說,聯合索引也是一棵 B+ 樹,不同的是聯合索引的鍵值的數量不是 1,而是大于等于 2,我們來看下兩個整型列組成的聯合索引,假定兩個鍵值的名稱分別為 a、b
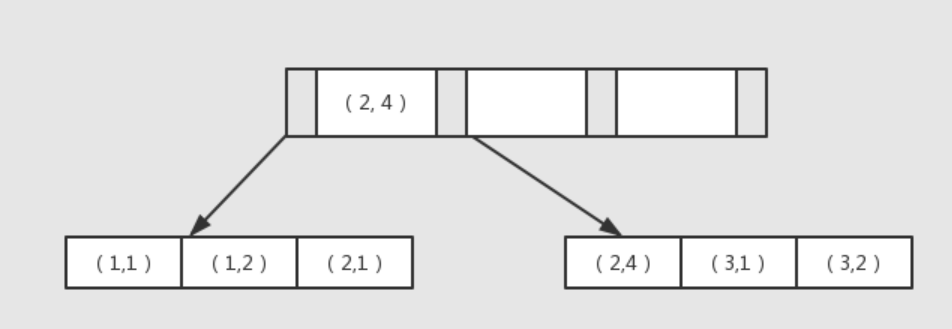
從圖中可以看到多個鍵值的 B+ 樹情況,鍵值都是排序的,通過葉子節點可以邏輯上順序讀取所有資料,就上面圖中所示,即為 (1,1)、(1、2)、(2、1)、(2、4)、(3、1)、(3、2),資料是按照 (a, b) 的順序進行存放,
?? 這里 “鍵值都是排好序” 的這種說法可能會讓大伙很疑惑,似乎只有 a 列是排序的,b 列并沒有排序啊,
注意!這里的排序,意思是確定了第一個鍵,對于第一個鍵相同的記錄來說,查詢的結果是對第二個鍵進行了排序,
這也是使用聯合索引的第二個好處,即已經對第二個鍵值進行了排序處理,可以避免多一次排序操作,舉個例子:有些應用程式都需要查詢某個用戶的購物情況,并按照時間進行排序,取出最近 n 次的購買記錄,這時使用聯合索引就可以避免多一次排序操作,因為索引本身在葉子節點已經排序了,
更進一步說,假設有聯合索引(a,b,c),下列陳述句可以直接通過聯合索引得到結果:
SELECT ... FROM TABLE WHERE a=xxx ORDER BY bSELECT ... FROM TABLE WHERE a=xxx AND b=xxx ORDER BY c
但是對于下面的陳述句,聯合索引不能直接得到結果,其還需要執行一次排序操作,因為索引 (a,c) 并未排序:
SELECT ... FROM TABLE WHERE a=xxx ORDER BY c
說了這么多,好像和最左前綴啥關系也沒有啊

考慮下,對于下面這條陳述句,能否用到聯合索引(a, b)?
select * from table where a = XXX and b= XXX;
這個當然沒問題,
那對于 a 列的單獨查詢,能否用到聯合索引(a, b)?
select * from table where a = XXX;
當然也可以,我們不是說了,a 列是已經排好序的
但是對于 b 列的單獨查詢則不能使用聯合索引(a, b)!
select * from table where b = XXX;
因為把葉子節點中的 b 值單獨拎出來看它不是有序的:1、2、1、4、1、2,因此對于 b 的查詢是使用不到 (a,b) 這個聯合索引的,
同樣的道理,對于(a, b, c)聯合索引來說,查詢 (a, b) 可以用到這個聯合索引,但是查詢 (b, c) 就沒辦法使用這個聯合索引,因為 b 和 c 列的有序性都是依托于 a 列的存在的,
This,就是聯合索引的最左前綴原則,只要查詢的是聯合索引的最左 N 個欄位,就可以利用該聯合索引來加速查詢,
基于上面對最左前綴索引的說明以及用戶表的例子,我們來討論一個問題:在建立聯合索引的時候,如何安排索引內的欄位順序?
有兩點原則,
首先,第一原則,如果通過調整順序,可以少維護一個索引,那么這個欄位順序往往就是需要優先考慮采用的
很好理解,當已經有了 (a,b) 這個聯合索引后,一般就不需要單獨在 a 上建立索引了,
那么,再思考一個問題:如果既有聯合查詢 (a,b),又有基于 a、b 各自的查詢呢?
顯然,如果查詢條件里面只有 b 的陳述句,是無法使用 (a,b) 這個聯合索引的,這時候你不得不維護另外一個 b 列的索引,也就是說你需要同時維護 (a,b)、(b) 這兩個索引,
舉個用戶表例子,有這樣三個高頻查詢需求:
- 根據 name 查詢 id:
select id from user where name = xxx; - 根據 age 查詢 id:
select id from user where age= xxx; - 根據 name 和 age 查詢 id:
select id from user where name = xxx and age = xxx;
這個時候,我們有兩種索引建立的選擇:
-
聯合索引 (age, name) + 單欄位索引 (name)
-
聯合索引 (name, age) + 單欄位索引 (age)
怎么選?

這種場景下,我們要考慮的原則就是空間,
顯然,name 欄位是要比 age 欄位大的,所以,第二種選擇占用的空間要小于第一種選擇,推薦大伙兒使用第二種選擇:聯合索引 (name, age) + 單欄位索引 (age)
索引下推
最左前綴可以用于在索引中定位記錄,那么,那些不符合最左前綴的部分,會怎么樣呢?
以用戶表的聯合索引(name, age)為例,假設現在有一個需求,找出所有姓 “張” 并且 20 歲的男性:
select * from tuser where name like '張%' and age = 20 and sex = male
《高性能 MySQL》 書中提到:對于聯合索引,如果查詢中有某個列的范圍查詢,則其右邊所有列都無法使用索引進行快速定位
所以對于這條陳述句來說,其實并不能完全踩中 (name, age) 這個聯合索引,他只能踩到 name,
具體來說,這個陳述句在搜索(name,age)的聯合索引樹的時候,并不會去看 age 的值,只是按順序把 “name 第一個字是張” 的記錄一條條取出來,然后開始回表,到主鍵索引上找出資料行,再一個一個判斷其他條件是否滿足,從下圖可以看出來,需要回表 3 次,
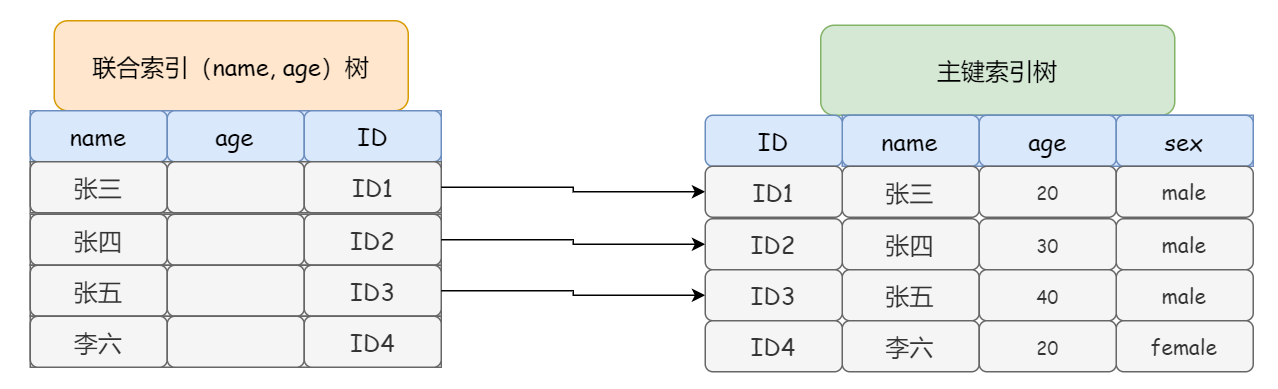
這是 MySQL 5.6 之前的做法,簡單總結,當進行索引查詢時,首先根據索引來查找記錄,然后再根據 where 條件來過濾記錄
而 MySQL 5.6 開始,資料庫在取出索引的同時,會根據 where 條件直接過濾掉不滿足條件的記錄,減少回表次數,這就是 索引下推 (Index Condition Pushdown,ICP) ,一種根據索引進行查詢的優化方式
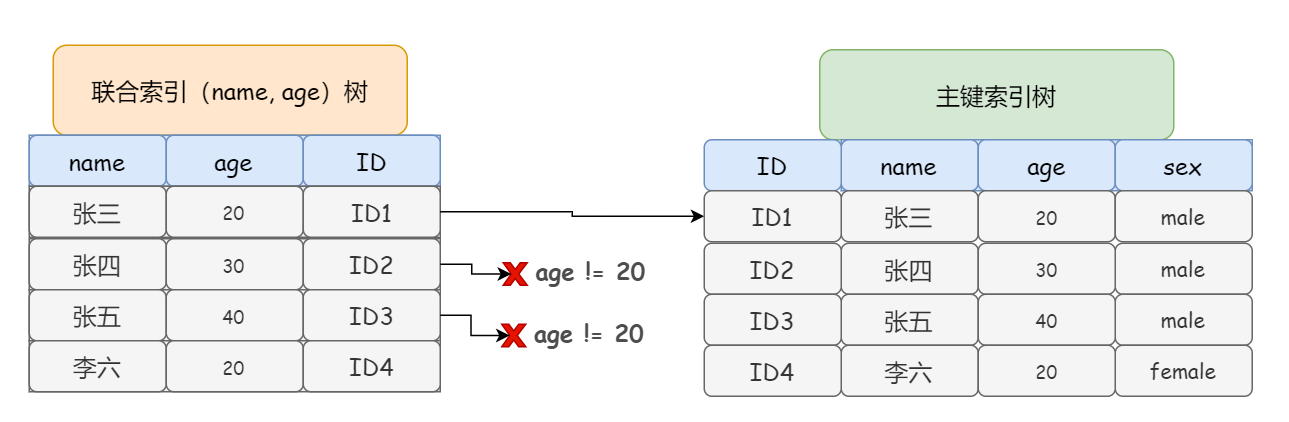
從圖中可以看出來,InnoDB 在 (name,age) 索引內部就判斷了 age 是否等于 20,對于不等于 20 的記錄,直接判斷并跳過,所以只需要對 ID1 這條記錄進行回表判斷就可以了,
?? 面試官:講一下聯合索引的最左前綴原則,為什么得最左匹配,不按照這個來為什么失效?
?? 小牛肉:最左前綴原則就是只要查詢的是聯合索引的最左 N 個欄位,就可以利用該聯合索引來加速查詢,
不按照最左匹配來為什么失效,其原因就在于聯合索引的 B+ 樹中的鍵值是排好序的,不過,這里指的排好序,其實是相對的,舉個例子,有 (a, b, c) 聯合索引,a 首先是排序好的,而 b 列是在 a 列排序的基礎上做的排序,同樣的 c 是在 a,b 有序的基礎上做的排序,所以說,如果有
where a = xxx order by b = xxx這種請求的話,是可以直接在這顆聯合索引樹上查出來的,不用對 b 列進行額外的排序;而如果是where a = xxx order by c = xxx這種請求的話,還需要額外對 c 列進行一次排序才行,另外,如果有對 a,b,c 的聯合條件查詢的話,并且 a 是模糊匹配或者說是范圍查詢的話,其實并不能完全踩中聯合索引(a,b,c),a 列右邊的所有列都無法使用索引進行快速定位了,所以這個時候就需要進行回表判斷,也就是說資料庫會首先根據索引來查找記錄,然后再根據 where 條件來過濾記錄,
不過在 MySQL 5.6 中支持了索引下推 ICP,資料庫在取出索引的同時,會根據 where 條件直接過濾掉不滿足條件的記錄,減少回表次數
大廠面試火箭計劃
點擊 大廠面試火箭計劃 直達
目前網路上提供的面試題答案大部分都是短短的幾行字,并且沒有邏輯,面試官一聽就知道是背的,我覺得這無法滿足大部分同學的訴求,
如何讓面試官知道我不是背的?如何知其然而知其所以然?
So,我希望的是以面試題為導向,建立完整的知識體系,讓八股文變得有價值,而不是東一錘西一棒
后續準備以牛客上的面經帖為導向,對每個面試題提供 偏口語化的背誦版 + 偏專業化的詳解版,已經會的同學呢可以直接看背誦版,還不太了解的同學呢可以結合詳解版一起看
所有的面試題都已經按照知識體系的順序進行過排序,并且我會加入一些補充題用于完善
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/384095.html
標籤:MySQL
上一篇:生成亂數以求和到目標的方法