隨著業務的不斷發展,資料庫中的資料會越來越多,相應地,單表的資料量也會越到越大,大到一個臨界值,單表的查詢性能就會下降,
這個臨界值,并不能一概而論,它與硬體能力、具體業務有關,
雖然在很多 MySQL 運維規范里,都建議單表不超過 500w、1000w,
但實際上,我在生產環境,也見過大小超過 2T,記錄數過億的表,同時,業務不受影響,
單表過大時,業務通常會考慮兩種拆分方案:水平切分和垂直切分,
水平拆分 VS 垂直拆分
水平切分,拆分的維度是行,一般會根據某種規則或演算法將表中的記錄拆分到多張表中,
拆分后的表既可在一個實體,也可在多個不同實體中,如果是后者,又會涉及到分布式事務,
垂直切分,拆分的維度是列,一般是將列拆分到多個業務模塊中,這種拆分更多的是上層業務的拆分,
從改造的復雜程度來說,前者小于后者,
所以,在單表資料量過大時,業界用得較多的還是水平拆分,
常見的水平拆分方案有:分庫分表、磁區表,
雖然分庫分表是一個比較徹底的水平拆分方案,但一方面,它的改造需要一定的時間;另一方面,它對開發的能力也有一定的要求,相對來說,磁區表就比較簡單,也無需業務改造,
磁區表
很多人可能會認為 MySQL 的優勢在于 OLTP 應用,對于 OLAP 應用就不太適合,所以,也不太推薦磁區表這種偏 OLAP 的特性,
但實際上,對于某些業務型別,還是比較適合使用磁區表的,尤其是那些有明顯冷熱資料之分,且資料的冷熱與時間相關的業務,
下面,我們看看磁區表的優點:
-
提升查詢性能
對于磁區表的查詢操作,如果查詢條件中包含磁區鍵,則這個查詢操作就只會被下推到符合條件的磁區內進行,無關磁區將自動過濾掉,
在資料量比較大的情況下,能提升查詢速度,
-
對業務透明
將表從一個非磁區表轉換為磁區表,業務端無需做任何改造,
-
管理方便
在對單個磁區進行洗掉、遷移和維護時,不會影響到其它磁區,
尤其是針對單個磁區的洗掉(DROP)操作,避免了針對這個磁區所有記錄的 DELETE 操作,
遺憾的是,MySQL 磁區表不支持并行查詢,理論上,當一個查詢涉及到多個磁區時,磁區與磁區之間應進行并行查詢,這樣才能充分利用多核 CPU 資源,
但 MySQL 并不支持,包括早期的官方檔案,也提到了這個問題,也將這個功能的實作放到了優先級串列中,
These features are not currently implemented in MySQL Partitioning, but are high on our list of priorities. - Queries involving aggregate functions such as SUM() and COUNT() can easily be parallelized. A simple example of such a query might be SELECT salesperson_id, COUNT(orders) as order_total FROM sales GROUP BY salesperson_id;. By “parallelized,” we mean that the query can be run simultaneously on each partition, and the final result obtained merely by summing the results obtained for all partitions. - Achieving greater query throughput in virtue of spreading data seeks over multiple disks.
MySQL 8.0 中磁區表的變化
在 MySQL 5.7 中,對于磁區表,有個很重大的更新,即 InnoDB 存盤引擎原生支持了磁區,無需再通過 ha_partition 介面來實作,
所以,在 MySQL 5.7 中,如果要創建基于 MyISAM 存盤引擎的磁區表,會提示 warning ,
The partition engine, used by table 'sbtest.t_range', is deprecated and will be removed in a future release. Please use native partitioning instead.
而在 MySQL 8.0 中,則更為徹底,server 層移除了 ha_partition 介面代碼,
如果要使用磁區表,只能使用支持原生磁區的存盤引擎,在 MySQL 8.0 中,就只有 InnoDB,
這就意味著,在 MySQL 8.0 中,如果要創建 MyISAM 磁區表,基本上就不可能了,
這也從另外一個角度說明了為什么生產上不建議使用 MyISAM 表,
mysql> CREATE TABLE t_range (
-> id INT,
-> name VARCHAR(10)
-> ) ENGINE = MyISAM
-> PARTITION BY RANGE (id) (
-> PARTITION p0 VALUES LESS THAN (5),
-> PARTITION p1 VALUES LESS THAN (10)
-> );
ERROR 1178 (42000): The storage engine for the table doesn't support native partitioning
為什么磁區鍵必須是主鍵的一部分?
在使用磁區表時,大家常常會碰到下面這個報錯,
mysql> CREATE TABLE opr (
-> opr_no INT,
-> opr_date DATETIME,
-> description VARCHAR(30),
-> PRIMARY KEY (opr_no)
-> )
-> PARTITION BY RANGE COLUMNS (opr_date) (
-> PARTITION p0 VALUES LESS THAN ('20210101'),
-> PARTITION p1 VALUES LESS THAN ('20210102'),
-> PARTITION p2 VALUES LESS THAN MAXVALUE
-> );
ERROR 1503 (HY000): A PRIMARY KEY must include all columns in the table's partitioning function (prefixed columns are not considered).
即磁區鍵必須是主鍵的一部分,
上面的 opr 是一張操作流水表,其中,opr_no 是操作流水號,一般都會被設定為主鍵,opr_date 是操作時間,基于操作時間來進行磁區,是一個常見的磁區場景,
為了突破這個限制,可將 opr_date 作為主鍵的一部分,
mysql> CREATE TABLE opr (
-> opr_no INT,
-> opr_date DATETIME,
-> description VARCHAR(30),
-> PRIMARY KEY (opr_no, opr_date)
-> )
-> PARTITION BY RANGE COLUMNS (opr_date) (
-> PARTITION p0 VALUES LESS THAN ('20210101'),
-> PARTITION p1 VALUES LESS THAN ('20210102'),
-> PARTITION p2 VALUES LESS THAN MAXVALUE
-> );
Query OK, 0 rows affected (0.04 sec)
但是這么創建,又會帶來一個新的問題,即對于同一個 opr_no ,可插入到不同磁區中,如下所示:
mysql> insert into opr values(1,'2020-12-31 00:00:01','abc');
Query OK, 1 row affected (0.00 sec)
mysql> insert into opr values(1,'2021-01-01 00:00:01','abc');
Query OK, 1 row affected (0.00 sec)
mysql> select * from opr partition (p0);
+--------+---------------------+-------------+
| opr_no | opr_date | description |
+--------+---------------------+-------------+
| 1 | 2020-12-31 00:00:01 | abc |
+--------+---------------------+-------------+
1 row in set (0.00 sec)
mysql> select * from opr partition (p1);
+--------+---------------------+-------------+
| opr_no | opr_date | description |
+--------+---------------------+-------------+
| 1 | 2021-01-01 00:00:01 | abc |
+--------+---------------------+-------------+
1 row in set (0.00 sec)
這實際上違背了業務對于 opr_no 的唯一性要求,
既然這樣,有的童鞋會建議給 opr_no 添加個唯一索引,But,現實是殘酷的,
mysql> create unique index uk_opr_no on opr (opr_no);
ERROR 1503 (HY000): A UNIQUE INDEX must include all columns in the table's partitioning function (prefixed columns are not considered)
即便是添加唯一索引,磁區鍵也必須包含在唯一索引中,
總而言之,對于 MySQL 磁區表,無法從資料庫層面保證非磁區列在表級別的唯一性,只能確保其在磁區內的唯一性,
這也是 MySQL 磁區表所為人詬病的地方之一,
但實際上,這個鍋讓 MySQL 背并不合適,對于 Oracle 索引組織表( InnoDB 即是索引組織表),同樣也有這個限制,
Oracle 官方檔案( http://docs.oracle.com/cd/E11882_01/server.112/e40540/schemaob.htm#CNCPT1514),在談到索引組織表(Index-Organized Table,簡稱 IOT)的特性時,就明確提到了 “磁區鍵必須是主鍵的一部分”,
Note the following characteristics of partitioned IOTs:
- Partition columns must be a subset of primary key columns.
- Secondary indexes can be partitioned locally and globally.
- OVERFLOW data segments are always equipartitioned with the table partitions.
下面,我們看看剛開始的建表 SQL ,在 Oracle 中的執行效果,
SQL> CREATE TABLE opr_oracle (
2 opr_no NUMBER,
3 opr_date DATE,
4 description VARCHAR2(30),
5 PRIMARY KEY (opr_no)
6 )
7 ORGANIZATION INDEX
8 PARTITION BY RANGE (opr_date) (
9 PARTITION p0 VALUES LESS THAN (TO_DATE('20170713', 'yyyymmdd')),
10 PARTITION p1 VALUES LESS THAN (TO_DATE('20170714', 'yyyymmdd')),
11 PARTITION p2 VALUES LESS THAN (MAXVALUE)
12 );
PARTITION BY RANGE (opr_date) (
*
ERROR at line 8:
ORA-25199: partitioning key of a index-organized table must be a subset of the
primary key
同樣報錯,
注意,這里指定了 ORGANIZATION INDEX ,創建的是索引組織表,
看來,磁區鍵必須是主鍵的一部分并不是 MySQL 的限制,而是索引組織表的限制,
之所以對索引組織表有這樣的限制,個人認為,還是基于性能考慮,
假設磁區鍵和主鍵是兩個不同的列,在進行插入操作時,雖然也指定了磁區鍵,但還是需要掃描所有磁區才能判斷插入的主鍵值是否違反了唯一性約束,這樣的話,效率會比較低下,違背了磁區表的初衷,
而對于堆表則沒有這樣的限制,
在堆表中,主鍵和表中的資料是分開存盤的,在判斷插入的主鍵值是否違反唯一性約束時,只需利用到主鍵索引,
但與 MySQL 不一樣的是,Oracle 實作了全域索引,所以針對上面的,同一個 opr_no,允許插入到不同磁區中的問題,可通過全域唯一索引來規避,
SQL> CREATE TABLE opr_oracle (
2 opr_no NUMBER,
3 opr_date DATE,
4 description VARCHAR2(30),
5 PRIMARY KEY (opr_no, opr_date)
6 )
7 ORGANIZATION INDEX
8 PARTITION BY RANGE (opr_date) (
9 PARTITION p0 VALUES LESS THAN (TO_DATE('20170713', 'yyyymmdd')),
10 PARTITION p1 VALUES LESS THAN (TO_DATE('20170714', 'yyyymmdd')),
11 PARTITION p2 VALUES LESS THAN (MAXVALUE)
12 );
Table created.
SQL> create unique index uk_opr_no on opr_oracle (opr_no);
Index created.
SQL> insert into opr_oracle values(1,to_date('2020-12-31 00:00:01','yyyy-mm-dd hh24:mi:ss'),'abc');
1 row created.
SQL> insert into opr_oracle values(1,to_date('2020-12-31 00:00:01','yyyy-mm-dd hh24:mi:ss'),'abc');
insert into opr_oracle values(1,to_date('2020-12-31 00:00:01','yyyy-mm-dd hh24:mi:ss'),'abc')
*
ERROR at line 1:
ORA-00001: unique constraint (SCOTT.SYS_IOT_TOP_87350) violated
但 MySQL 卻無能為力,之所以會這樣,是因為 MySQL 磁區表只實作了本地磁區索引(Local Partitioned Index),而沒有實作 Oracle 中的全域索引(Global Index),
本地磁區索引 VS 全域索引
本地磁區索引和全域索引的原理圖如下所示:
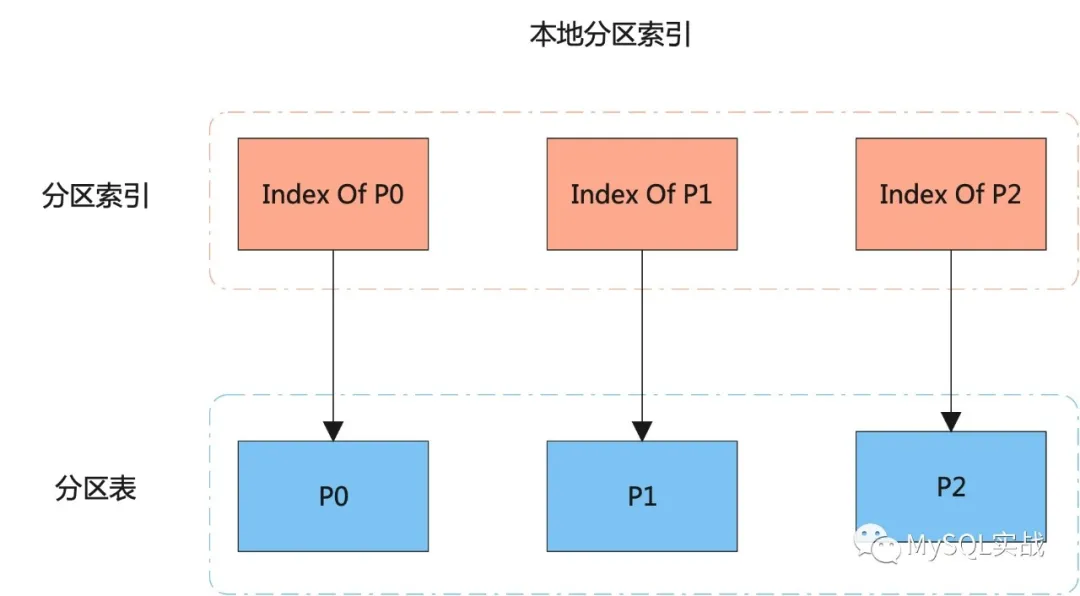
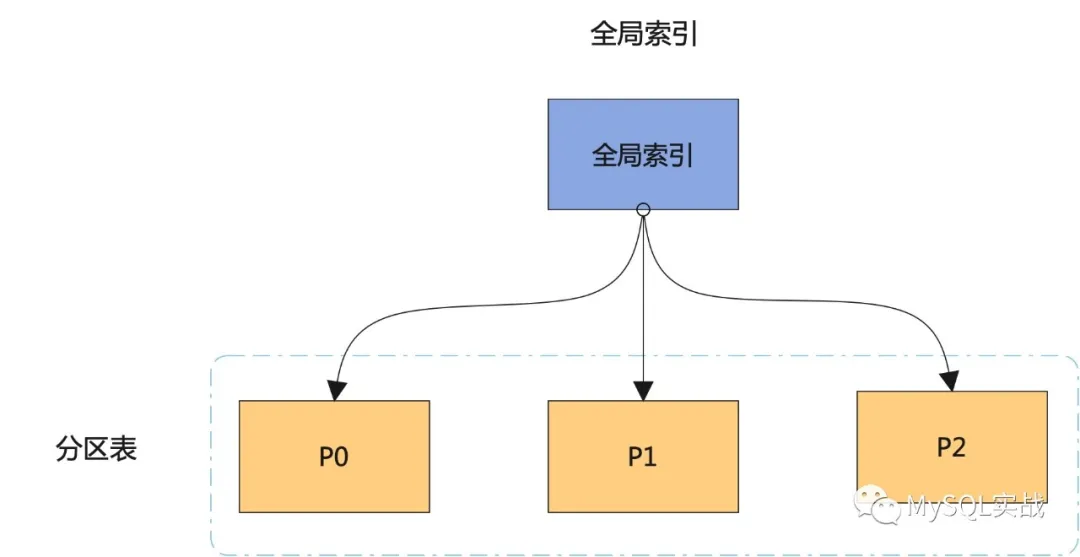
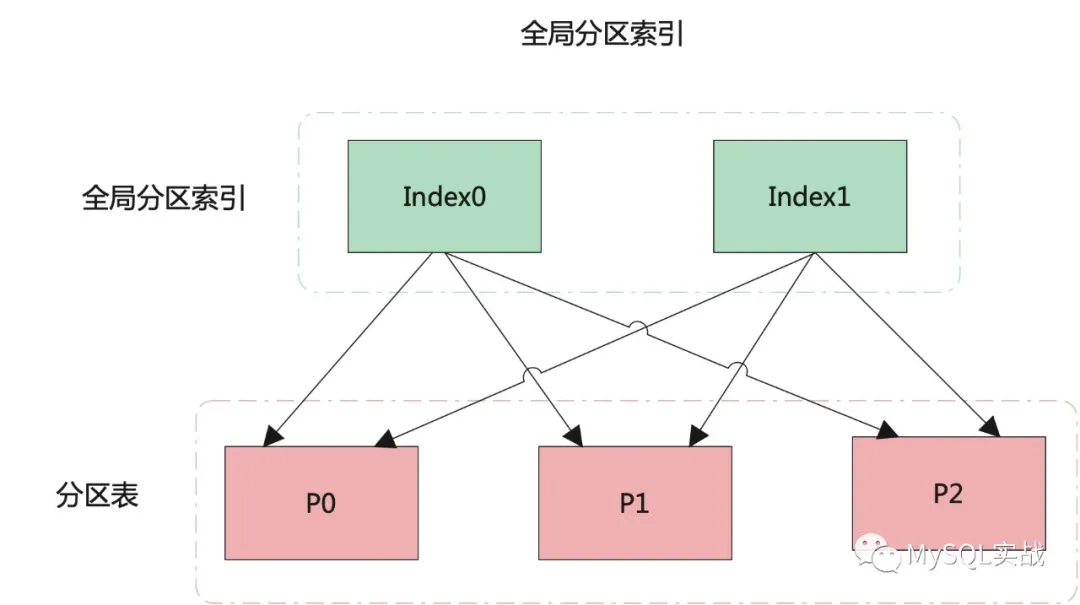
結合原理圖,我們來看看兩種索引之間的區別:
-
本地磁區索引同時也是磁區索引,磁區索引和表磁區之間是一一對應的,
而全域索引,既可以是磁區的,也可以是不磁區的,
如果是全域磁區索引,一個磁區索引可對應多個表磁區,同樣,一個表磁區也可對應多個磁區索引,
-
對本地磁區索引的管理操作只會影響到單個磁區,不會影響到其它磁區,
而對全域磁區索引的管理操作會造成整個索引的失效,當然,這一點可通過 UPDATE INDEXES 子句加以規避,
-
本地磁區索引只能保證磁區內的唯一性,無法保證表級別的唯一性,但全域磁區可以,
-
在 Oracle 中,無論是索引組織表還是堆表,如果要創建本地唯一索引,同樣也要求磁區鍵必須是唯一鍵的一部分,
SQL> create unique index uk_opr_no_local on opr_oracle(opr_no) local;
create unique index uk_opr_no_local on opr_oracle(opr_no) local
*
ERROR at line 1:
ORA-14039: partitioning columns must form a subset of key columns of a UNIQUE
index
總結
1. MySQL 磁區表關于“磁區鍵必須是唯一鍵(主鍵和唯一索引)的一部分”的限制,本質上是索引組織表的限制,
2. MySQL 磁區表只實作了本地磁區索引,沒有實作全域索引,所以無法保證非磁區列的全域唯一,
如果要保證非磁區列的全域唯一,只能依賴業務實作了,
3. 不推薦使用 MyISAM 磁區表,當然,任何場景都不推薦使用 MyISAM 表,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/388981.html
標籤:其他