問題
JuiceFS 是一個基于物件存盤的分布式檔案系統,在之前跟物件存盤比較的文章中已經介紹了 JuiceFS 能夠保證資料的強一致性和極高的讀寫性能,因此完全可以用來替代 HDFS,但是資料平臺整體遷移通常是一個費時費力的大工程,需要做到遷移超大規模資料的同時盡量不影響上層業務,下面將會介紹如何通過 JuiceFS 的遷移工具來實作平滑遷移 HDFS 中的海量資料到 JuiceFS,
平滑遷移方案
資料平臺除了我們在 HDFS 上實際看到的檔案以外,其實還有一些同樣重要的資訊,也就是所謂的「元資料」,這些元資料存盤在類似 Hive Metastore 這樣的系統里,因此當我們談論資料遷移時不能把這兩種資料拆分開來,必須同時考慮,遷移完資料以后需要同時更新 Hive 表或者磁區的位置(LOCATION)資訊,如果任何一種資料出了問題都會對業務方造成影響,
為了保證資料和元資料的一致性,通常的做法是在遷移完資料以后同步更新元資料中的位置資訊,但當資料規模比較大,并且業務又可能更新資料時,很難保證資料拷貝和更新位置資訊是個原子操作,遷移程序中可能導致資料丟失,影響整體遷移的可靠性,甚至需要以暫停業務為代價來實作,或者在業務中采用雙寫等機制來實作在線遷移,侵入業務邏輯,費時費力,
如果能夠在遷移程序中為資料訪問提供統一的路徑來屏蔽實際的資料位置,實作元資料和真實資料位置的解耦,將會大大降低整體遷移的風險,檔案系統的符號鏈接就可以達到這個效果,JuiceFS 也支持符號鏈接,并且支持跨檔案系統的符號鏈接,借助它可以為多個檔案系統提供統一的訪問入口,形成統一命名空間,
符號鏈接是作業系統中廣泛應用的概念,你可以通過符號鏈接實作在一個目錄樹中管理分散在各個地方的資料,對應的,我們也可以通過 JuiceFS 的符號鏈接特性實作在一個檔案系統中管理多個存盤系統,其實符號鏈接這個功能早在 2013 年 Hadoop 社區就已經想要在 HDFS 上實作(HADOOP-10019),但遺憾的是目前為止還沒完整支持,借助符號鏈接即可在 JuiceFS 上管理包括但不限于 HDFS、物件存盤在內的各種存盤系統,表面上看起來訪問的是 JuiceFS,但實際訪問的是底層真實的存盤,
同時,JuiceFS 的原子重命名(rename)操作也能在資料遷移程序中發揮關鍵作用,JuiceFS 通過符號鏈接來跳轉回原始資料,但當資料完全拷貝過來以后需要覆寫這個符號鏈接,這個時候原子重命名就能保證資料的安全性和可靠性,避免出現資料丟失和損壞,
此外,JuiceFS 還可以通過組態檔和特殊的標志檔案來動態感知到遷移程序,并在新增和洗掉檔案時進行額外的檢查,確保新創建的檔案也會出現在遷移后的目錄中,并且確保要洗掉的檔案也能從新系統中刪掉,對于更復雜的重命名操作,也有類似的機制來保證正確性,
有了剛才介紹的 JuiceFS 的這些特性,就可以實作在資料遷移時分別遷移資料和元資料,同時整個遷移程序對于業務是完全透明的,下面講解具體的遷移操作步驟,
操作步驟
步驟一:將 JuiceFS 作為 HDFS 的訪問入口
在 JuiceFS 上給 HDFS 的所有第一級目錄(或檔案)創建對應的符號鏈接(假定不會再在 HDFS 根目錄創建內容),之后通過 jfs://name/<path> 就能完整訪問 HDFS 里面的內容,兩者是完全等價的,如下圖所示,

步驟二:使用 JuiceFS 來訪問 HDFS 中的資料
這一步有兩種實作方法,第一種是修改 Hive Metastore 中表或者磁區的 LOCATION 為對應的 JuiceFS 路徑,例如之前是 hdfs://ns/user/test.db/table_a,新路徑則為 jfs://name/user/test.db/table_a,第二種方法是將 fs.hdfs.impl 修改為 com.juicefs.MigratingFileSystem,這樣可以維持 LOCATION 不變,
這兩種方法的目的都是為了將所有訪問 HDFS 的入口改成訪問 JuiceFS,因為步驟一已經創建了指向 HDFS 的符號鏈接,所以不會影響現有業務訪問 HDFS,
步驟三:遷移目錄結構
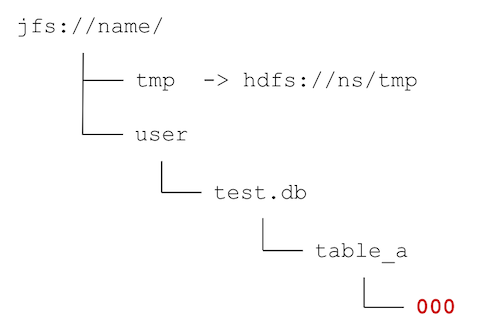
從這一步開始我們會正式進行遷移作業,不過先不著急把資料拷貝過來,我們需要先把目錄結構從 HDFS 中映射過來,你可以選擇你想要遷移的表或目錄,然后通過 JuiceFS 提供的工具快速將 HDFS 上的目錄結構遷移到 JuiceFS 上,以遷移 hdfs://ns/user/test.db/table_a 為例,這個目錄中的所有子目錄將會逐級在 JuiceFS 中創建,因為這一步僅涉及元資料操作,沒有資料拷貝,因此可以以極快的速度將歷史資料的目錄結構從 HDFS 遷移到 JuiceFS 上,同時需要注意的是,所有檔案仍然通過符號鏈接的方式指向 HDFS 中的路徑,如下圖所示,紅色部分即表示在 JuiceFS 上新創建的目錄,

同樣的,完成這一步以后不會影響現有業務訪問 HDFS,但是新寫入的資料將會直接存盤到 JuiceFS 中,
步驟四:遷移資料
這一步將會真正開始拷貝資料,通過 JuiceFS 的遷移工具并發地將上一步遺留的指向 HDFS 中普通檔案的符號鏈接替換為真實的資料,最終遷移目錄中將不再會有符號鏈接,也就表示這個目錄已經遷移完成,如下圖所示,紅色部分已經從符號鏈接變成了普通檔案,
反向遷移
在資料遷移程序中也可以通過反向遷移隨時回滾,來撤銷遷移操作,如果已經修改了元資料中的位置資訊,JuiceFS 遷移工具能確保反向遷移時恢復回原來的狀態,如果已經有新增的資料寫入到 JuiceFS 中,也能把這些新增資料拷貝回原始的存盤系統,
總結
通過前面的操作步驟介紹,可以看到整個遷移程序完全不會影響現有業務繼續訪問 HDFS,從開始到結束對于業務來說都是無感知的,JuiceFS 提供了完善的工具來簡化遷移流程,詳細的操作指南請參考 JuiceFS 官方檔案,
本篇文章以將 HDFS 遷移到 JuiceFS 為例說明了 JuiceFS 的符號鏈接特性,其實你完全可以發揮腦洞,把 JuiceFS 的符號鏈接應用在更多更廣的場景,例如在不同 HDFS 集群之間進行資料遷移、跨云跨區的資料遷移等,正是因為有了強大的符號鏈接特性,通過 JuiceFS 來提供統一的資料訪問層和視圖,才使得很多時候無法平滑操作的事情成為了可能,
推薦閱讀:知乎 x JuiceFS:利用 JuiceFS 給 Flink 容器啟動加速
如有幫助的話歡迎關注我們專案 Juicedata/JuiceFS 喲! (0?0?)
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/388986.html
標籤:其他
上一篇:Mysql資料庫語言學習的路線
下一篇:55 道MySQL基礎題