經過Lutz Lehmann的建議,我發現這是一個隨機權重和偏差的問題。我用np.ramdom.seed(2021)指定了隨機種子數,錯誤沒有收斂。但是如果我使用 np.ramdom.seed(10) 作為隨機種子數,第 600 個 epoch 誤差會收斂到一個相對較小的數量。
Galletti_Lance的建議是正確的,應該用周期性的激活函式代替。我擴大了sin函式的區間,學習誤差沒有收斂,果然是過擬合了。
input_data = np.arange(0, np.pi * 4, 0.1) # input
correct_data = np.sin(input_data) # correct answer
input_data = (input_data - np.pi*2) / np.pi
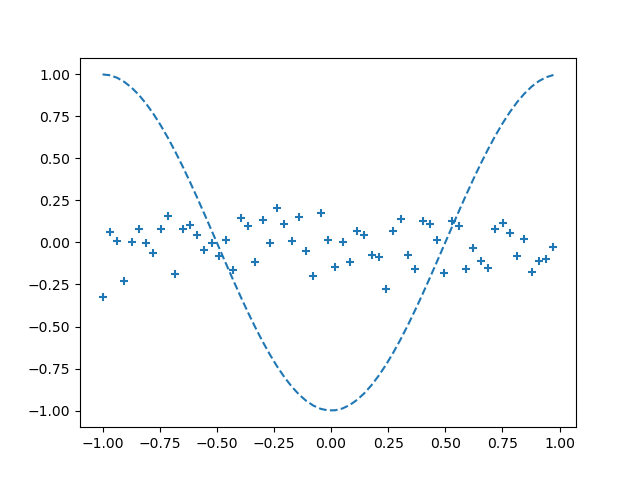
np.random.seed(2021) 學習cos函式,第20000個epoch如下:
Epoch:0/20001 Error:0.2904405534384431
Epoch:200/20001 Error:0.2752981376571506
Epoch:400/20001 Error:0.27356300803051226
Epoch:600/20001 Error:0.27409878767315193
Epoch:800/20001 Error:0.2638216736165815
Epoch:1000/20001 Error:0.27196157366033213
Epoch:1200/20001 Error:0.2743520487664953
Epoch:1400/20001 Error:0.2589745966244678
Epoch:1600/20001 Error:0.2705289192984957
Epoch:1800/20001 Error:0.2689693217636388
....
Epoch:20000/20001 Error:0.2678723095120438
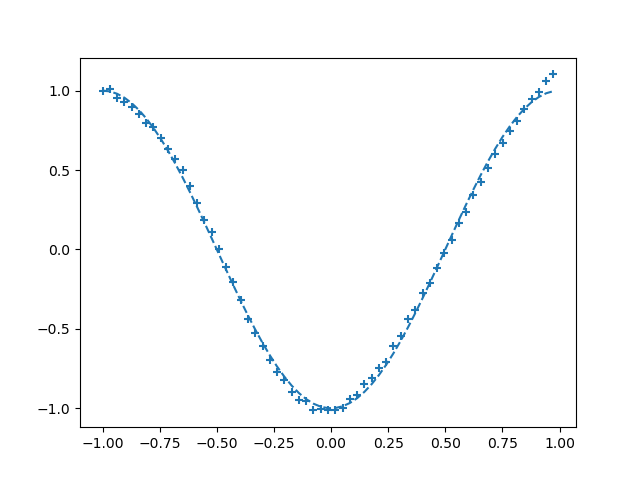
 但是如果我使用 np.ramdom.seed(10) 作為隨機種子數,第 600 個 epoch 誤差會收斂到一個相對較小的數量。
但是如果我使用 np.ramdom.seed(10) 作為隨機種子數,第 600 個 epoch 誤差會收斂到一個相對較小的數量。
Epoch:0/20001 Error:0.283958515549615
Epoch:200/20001 Error:0.260819823215878
Epoch:400/20001 Error:0.23267630899157743
Epoch:600/20001 Error:0.0022589485429890047
Epoch:800/20001 Error:0.0007425256677052262
Epoch:1000/20001 Error:0.0003946220094805989
....
Epoch:2800/20001 Error:0.00011495288247859594
Epoch:3000/20001 Error:9.989662843897715e-05
....
Epoch:20000/20001 Error:4.6146397913360866e-05
np.random.seed(10) 學習cos函式,第600個epoch如下:
I use neural network back propagation regression to learn the cos function. When I learn the sin function, it is normal. If it is changed to cos, it is abnormal. What is the problem?
correct_data = np.cos(input_data)
Related settings:
1.The activation function of the middle layer: sigmoid function
2.Excitation function of the output layer: identity function
3.Loss function: sum of squares error
4.Optimization algorithm: stochastic gradient descent method
5.Batch size: 1
My code is as follows:
import numpy as np
import matplotlib.pyplot as plt
# - Prepare to input and correct answer data -
input_data = np.arange(0, np.pi * 2, 0.1) # input
correct_data = np.cos(input_data) # correct answer
input_data = (input_data - np.pi) / np.pi # Converge the input to the range of -1.0-1.0
n_data = len(correct_data) # number of data
# - Each setting value -
n_in = 1 # The number of neurons in the input layer
n_mid = 3 # The number of neurons in the middle layer
n_out = 1 # The number of neurons in the output layer
wb_width = 0.01 # The spread of weights and biases
eta = 0.1 # learning coefficient
epoch = 2001
interval = 200 # Display progress interval practice
# -- middle layer --
class MiddleLayer:
def __init__(self, n_upper, n): # Initialize settings
self.w = wb_width * np.random.randn(n_upper, n) # weight (matrix)
self.b = wb_width * np.random.randn(n) # offset (vector)
def forward(self, x): # forward propagation
self.x = x
u = np.dot(x, self.w) self.b
self.y = 1 / (1 np.exp(-u)) # Sigmoid function
def backward(self, grad_y): # Backpropagation
delta = grad_y * (1 - self.y) * self.y # Differentiation of Sigmoid function
self.grad_w = np.dot(self.x.T, delta)
self.grad_b = np.sum(delta, axis=0)
self.grad_x = np.dot(delta, self.w.T)
def update(self, eta): # update of weight and bias
self.w -= eta * self.grad_w
self.b -= eta * self.grad_b
# - Output layer -
class OutputLayer:
def __init__(self, n_upper, n): # Initialize settings
self.w = wb_width * np.random.randn(n_upper, n) # weight (matrix)
self.b = wb_width * np.random.randn(n) # offset (vector)
def forward(self, x): # forward propagation
self.x = x
u = np.dot(x, self.w) self.b
self.y = u # Identity function
def backward(self, t): # Backpropagation
delta = self.y - t
self.grad_w = np.dot(self.x.T, delta)
self.grad_b = np.sum(delta, axis=0)
self.grad_x = np.dot(delta, self.w.T)
def update(self, eta): # update of weight and bias
self.w -= eta * self.grad_w
self.b -= eta * self.grad_b
# - Initialization of each network layer -
middle_layer = MiddleLayer(n_in, n_mid)
output_layer = OutputLayer(n_mid, n_out)
# -- learn --
for i in range(epoch):
# Randomly scramble the index value
index_random = np.arange(n_data)
np.random.shuffle(index_random)
# Used for the display of results
total_error = 0
plot_x = []
plot_y = []
for idx in index_random:
x = input_data[idx:idx 1] # input
t = correct_data[idx:idx 1] # correct answer
# Forward spread
middle_layer.forward(x.reshape(1, 1)) # Convert the input to a matrix
output_layer.forward(middle_layer.y)
# Backpropagation
output_layer.backward(t.reshape(1, 1)) # Convert the correct answer to a matrix
middle_layer.backward(output_layer.grad_x)
# Update of weights and biases
middle_layer.update(eta)
output_layer.update(eta)
if i % interval == 0:
y = output_layer.y.reshape(-1) # Restore the matrix to a vector
# Error calculation
total_error = 1.0 / 2.0 * np.sum(np.square(y - t)) # Square sum error
# Output record
plot_x.append(x)
plot_y.append(y)
if i % interval == 0:
# Display the number of epochs and errors
print("Epoch:" str(i) "/" str(epoch), "Error:" str(total_error / n_data))
# Display the output with a graph
plt.plot(input_data, correct_data, linestyle="dashed")
plt.scatter(plot_x, plot_y, marker=" ")
plt.show()
uj5u.com熱心網友回復:
如果增加 epoch 的數量有效,則模型需要更多的訓練。
但是您可能過度擬合了...請注意,余弦函式是一個周期函式,但您僅使用單調函式(sigmoid 和恒等式)來近似它。
因此,雖然在您的資料的有界區間內,它可能會起作用:
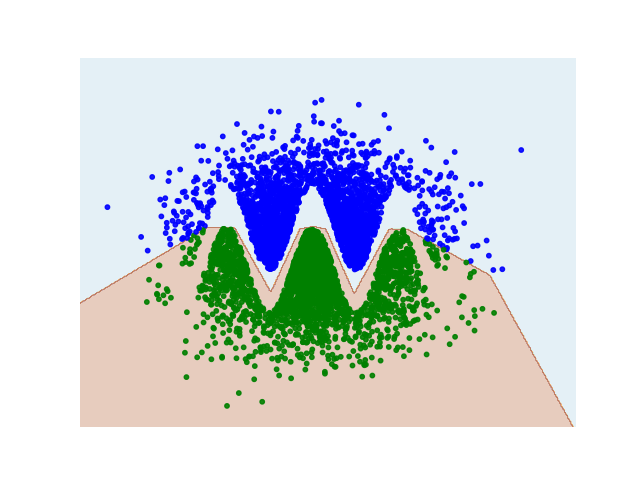
它不能很好地概括:
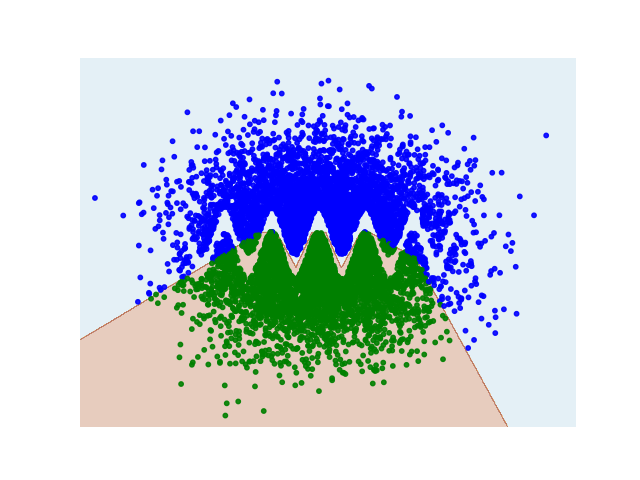
上圖的代碼:
import math as m
import numpy as np
import matplotlib.pyplot as plt
import sklearn.datasets as datasets
from tensorflow import keras
from tensorflow.keras import layers
t, _ = datasets.make_blobs(n_samples=7500, centers=[[0, 0]], cluster_std=1, random_state=0)
X = np.array(list(filter(lambda x : m.cos(4*x[0]) - x[1] < -.5 or m.cos(4*x[0]) - x[1] > .5, t)))
Y = np.array([1 if m.cos(4*x[0]) - x[1] >= 0 else LABEL for x in X])
model = keras.models.Sequential()
model.add(layers.Dense(8, input_dim=2, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(loss="binary_crossentropy")
model.fit(X, Y, batch_size=500, epochs=3000)
# create a mesh to plot in
h = .02 # step size in the mesh
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() 1
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
meshData = np.c_[xx.ravel(), yy.ravel()]
fig, ax = plt.subplots()
Z = model.predict(meshData)
Z = Z.reshape(xx.shape)
ax.contourf(xx, yy, Z, alpha=.3, cmap=plt.cm.Paired)
ax.axis('off')
# Plot also the training points
T = model.predict(X)
T = T.reshape(X[:,0].shape)
ax.scatter(X[:, 0], X[:, 1], color=colors[T].tolist(), s=10, alpha=0.9)
plt.show()
# add duplicate plotting code here to generate second plot
# predicting on data generated from a blob
# with a larger standard deviation
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/391877.html
標籤:python numpy neural-network
上一篇:更改跟蹤行為Numpy
下一篇:在Pandas中堆疊列