MySQL快速創建800w條測驗資料表&深度分頁
汴水流,泗水流,流到瓜州古渡頭,
吳山點點愁,
思悠悠,恨悠悠,恨到歸時方始休,
月明人倚樓,
一、資料插入思路
如果一條一條插入普通表的話,效率太低下,但記憶體表插入速度是很快的,可以先建立一張記憶體表,插入資料后,在匯入到普通表中,
1、創建記憶體表


1 CREATE TABLE `vote_record_memory` (
2
3 `id` INT (11) NOT NULL AUTO_INCREMENT,
4
5 `user_id` VARCHAR (20) NOT NULL,
6
7 `vote_id` INT (11) NOT NULL,
8
9 `group_id` INT (11) NOT NULL,
10
11 `create_time` datetime NOT NULL,
12
13 PRIMARY KEY (`id`),
14
15 KEY `index_id` (`user_id`) USING HASH
16
17 ) ENGINE = MEMORY AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8
View Code
2、創建普通表
普通表引數設定和記憶體表相同,否則從記憶體表往普通標匯入資料會報錯,
1 CREATE TABLE `vote_record` (
2
3 `id` INT (11) NOT NULL AUTO_INCREMENT,
4
5 `user_id` VARCHAR (20) NOT NULL,
6
7 `vote_id` INT (11) NOT NULL,
8
9 `group_id` INT (11) NOT NULL,
10
11 `create_time` datetime NOT NULL,
12
13 PRIMARY KEY (`id`),
14
15 KEY `index_user_id` (`user_id`) USING HASH
16
17 ) ENGINE = INNODB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8
View Code
3、創建存盤函式
產生偽隨機碼user_id 要用到存盤函式,
1 CREATE FUNCTION `rand_string`(n INT) RETURNS varchar(255) CHARSET latin1
2
3 BEGIN
4
5 DECLARE chars_str varchar(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789';
6
7 DECLARE return_str varchar(255) DEFAULT '' ;
8
9 DECLARE i INT DEFAULT 0;
10
11 WHILE i < n DO
12
13 SET return_str = concat(return_str,substring(chars_str , FLOOR(1 + RAND()*62 ),1));
14
15 SET i = i +1;
16
17 END WHILE;
18
19 RETURN return_str;
20
21 END
View Code
4、創建存盤程序
存盤程序是保存起來的可以接受和回傳用戶提供的引數的Transact-SQL 陳述句的集合,可以創建一個程序供永久使用,
1 CREATE PROCEDURE `add_vote_memory`(IN n int)
2
3 BEGIN
4
5 DECLARE i INT DEFAULT 1;
6
7 WHILE (i <= n ) DO
8
9 INSERT into vote_record_memory (user_id,vote_id,group_id,create_time ) VALUEs (rand_string(20),FLOOR(RAND() * 1000),FLOOR(RAND() * 100) ,now() );
10
11 set i=i+1;
12
13 END WHILE;
14
15 END
View Code
5、呼叫存盤程序
call 就是呼叫存盤程序或者函式,這里呼叫存盤程序1000000次
CALL add_vote_memory(1000000)
6、匯入資料
將記憶體表中的資料匯入普通表,
INSERT into vote_record SELECT * from vote_record_memory
7、記憶體不足
如果報錯記憶體滿了,報錯資訊如下:
1 CALL add_vote_memory(1000000)
2 > 1114 - The table 'vote_record_memory' is full
3 > 時間: 74.61s
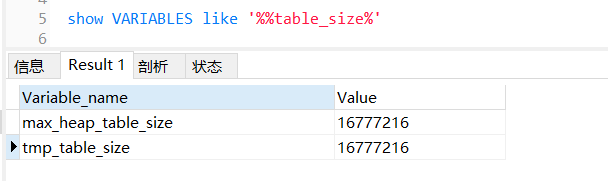
則可以使用命令查看記憶體表和臨時表允許寫入的最大值:
show variables like '%%table_size%'
MySQL默認16M:
修改默認記憶體配置:
set session tmp_table_size=1024*1024*1024;
set session max_heap_table_size=1024*1024*1024;
配置修改后,再執行上述呼叫存盤程序和資料匯入步驟,
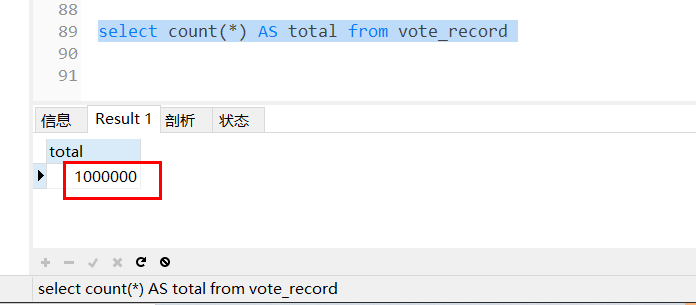
8、查看結果
查看記錄,是否有插入100W條資料,
select count(*) AS total from vote_record
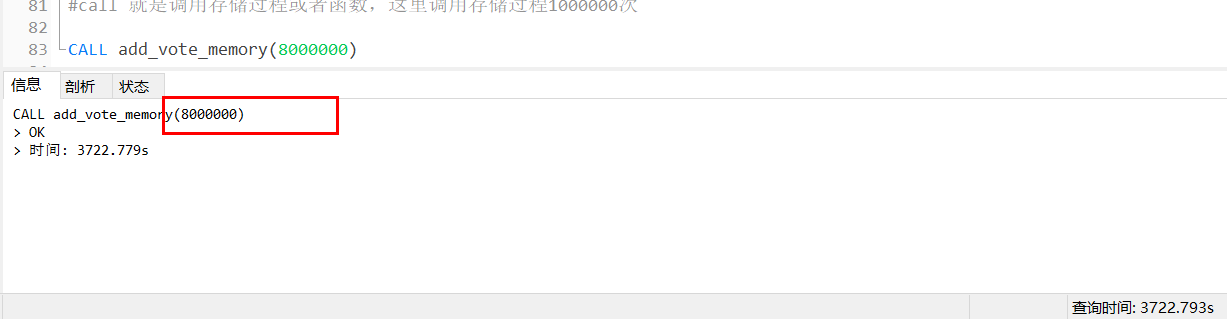
9、插入800W條資料
測驗插入800W條資料,call 呼叫存盤程序800W次,
查看結果:
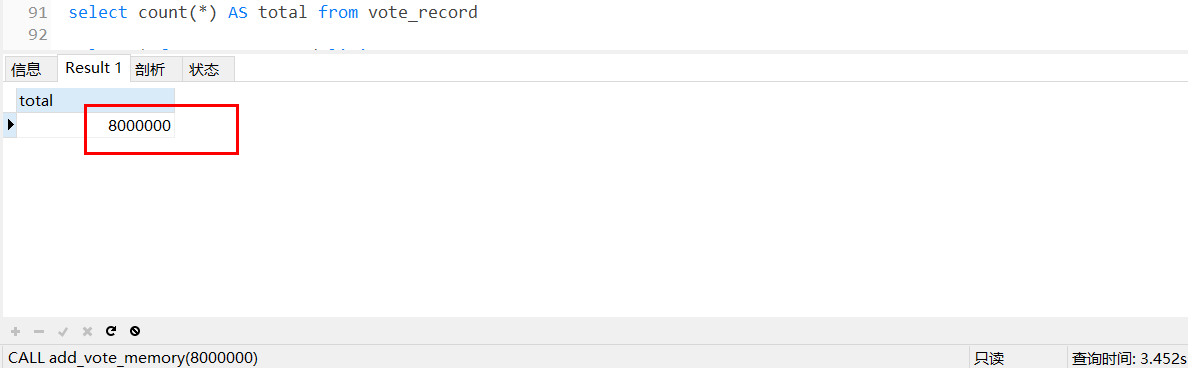
800W條測驗資料插入OK,想插入多少條測驗資料就呼叫n次存盤程序,CALL add_vote_memory(n),
二、MySQL深度分頁
所謂的深度分頁問題,涉及到mysql分頁的原理,通常情況下,mysql的分頁是這樣寫的:
select id, user_id, vote_id, group_id from vote_record limit 200, 10
SQL意思就是從vote_reccord 表里查200到210這10條資料即【201,210】,mysql會把前210條資料都查出來,拋棄前200條,回傳10條,當分頁所以深度不大的時候當然沒問題,隨著分頁的深入,sql可能會變成這樣:
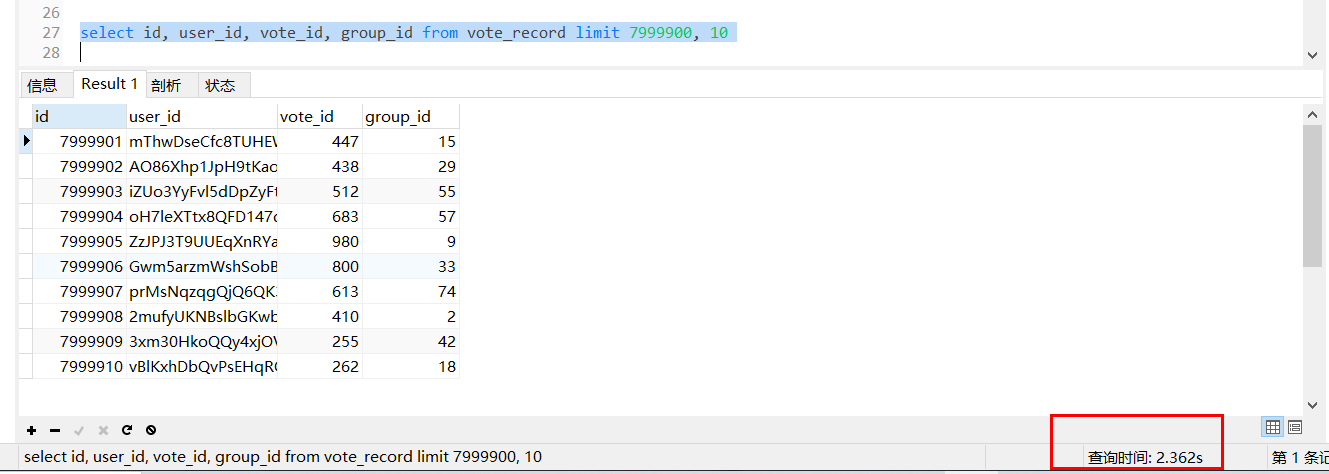
select id, user_id, vote_id, group_id from vote_record limit 7999900, 10
這個時候,mysql會查出來7999920條資料,拋棄前7999900條,如此大的資料量,速度一定快不起來,
那如何解決呢?一般情況下,最簡單的方式是增加一個條件,利用表的覆寫索引來加速分頁查詢:
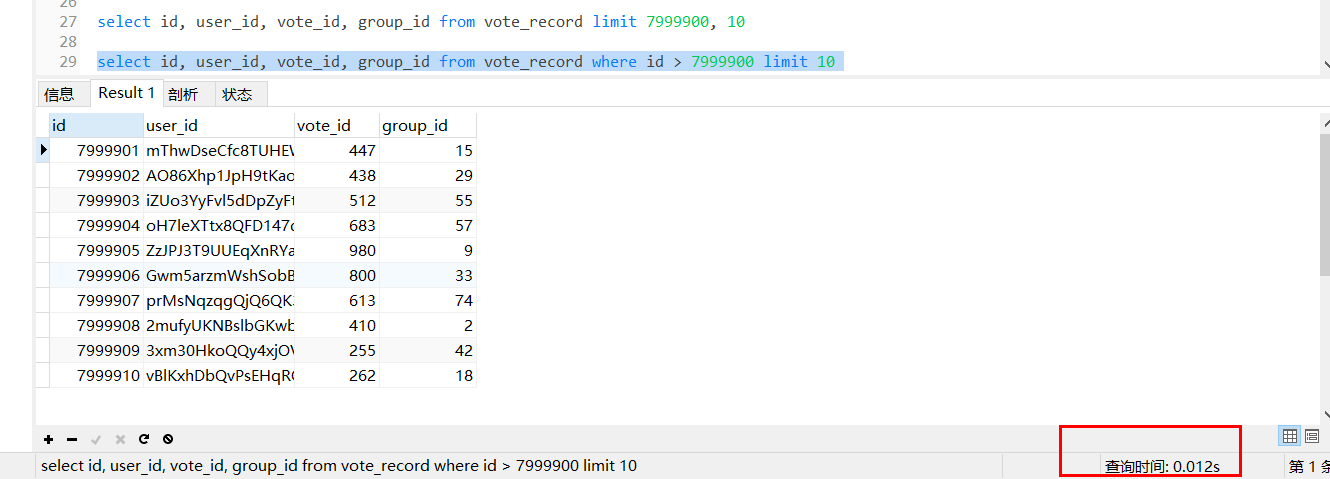
select id, user_id, vote_id, group_id from vote_record where id > 7999900 limit 10
我們都知道,利用了索引查詢的陳述句中如果只包含了那個索引列(覆寫索引),那么這種情況會查詢很快,
因為利用索引查找有優化演算法,且資料就在查詢索引上面,不用再去找相關的資料地址了,這樣節省了很多時間,上述vote_record 表的id欄位是主鍵,自然就包含了默認的主鍵索引,這樣,mysql會走主鍵索引,直接連接到7999900處,然后查出來10條資料,但是這個方式需要介面的呼叫方配合改造,把上次查詢出來的最大id以引數的方式傳給介面提供方,會有一定溝通成本,
1、測驗深度分頁
優化前,查詢耗時2.362s,隨著資料的增大耗時會更多,limit陳述句的查詢時間與起始記錄的位置成正比,
優化后,耗時0.012s,性能提升了196.8倍,
汴水流,泗水流,流到瓜州古渡頭,
吳山點點愁,
思悠悠,恨悠悠,恨到歸時方始休,
月明人倚樓,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/393873.html
標籤:MySQL
上一篇:Kafka Eagle分布式模式
下一篇:MYSQL基礎學習筆記