背景
由于公司業務場景的需要,我們需要開發HBase平臺,主要需要以下功能:
- 建表管理
- 授權管理
- SDK實作
- 與公司內部系統打通
我們使用的HBase 版本:
HBase 1.2.0-cdh5.16.2
Hadoop: 2.6.0-cdh5.16.2
目前主要應用場景:
- 實時計算如商品、商家等維度表
- 去重邏輯
- 中間件服務等監控資料
- 用戶畫像
平臺建設
建表管理
1.指定命名空間
HBase系統默認定義了兩個預設的namespace:
- hbase:系統內建表,包括namespace和meta表
- default:用戶建表時未指定namespace的表都創建在此
我們需要根據業務組進行定義命名空間,方便維護管理
2.支持多集群,不同業務組根據需要選擇相應集群
3.指定表名
4.指定列族
因為列族在創建表的時候是確定的,列名以列族作為前綴,按需可動態加入,如: cf:name, cf:age
cf 就是列族, name, age 就是列名
5.設定生存時間TTL
一旦達到過期時間,HBase將自動洗掉行
6.支持預磁區
HBase默認建表時有一個region,這個region的rowkey是沒有邊界的,即沒有startkey和endkey,在資料寫入時,所有資料都會寫入這個默認的region,隨著資料量的不斷增加,此region已經不能承受不斷增長的資料量,會進行split,分成2個region,在此程序中,會產生兩個問題:
- 資料往一個region上寫,會有寫熱點問題,
- region split會消耗寶貴的集群I/O資源,
基于此可以控制在建表的時候,創建多個空region,并確定每個region的起始和終止rowkey,這樣只要我們的rowkey設計能均勻的命中各個region,就不會存在寫熱點問題,自然split的幾率也會大大降低,當然隨著資料量的不斷增長,該split的還是要進行split,像這樣預先創建hbase表磁區的方式,稱之為預磁區.
預磁區的實作,參考HBase的shell腳本實作.
相關代碼:
Configuration configuration = conn.getConfiguration();
RegionSplitter.SplitAlgorithm hexStringSplit = RegionSplitter.newSplitAlgoInstance(configuration, splitaLgo);
splits = hexStringSplit.split(numRegions);
指定分割演算法以及預磁區的數目
分割演算法主要三種:
- HexStringSplit: rowkey是十六進制的字串作為前綴的
- DecimalStringSplit: rowkey是10進制數字字串作為前綴的
- UniformSplit: rowkey前綴完全隨機
其他配置:
HColumnDescriptor hColumnDescriptor = new HColumnDescriptor(cf);
//指定版本,設定成一個即可
hColumnDescriptor.setMaxVersions(1);
//指定列族過期時間,界面配置最小單位天,HBase TTL時間單位為秒
Long ttl = TimeUnit.DAYS.toSeconds(expireDays);
hColumnDescriptor.setTimeToLive(ttl.intValue());
//啟用壓縮演算法
hColumnDescriptor.setCompressionType(Compression.Algorithm.SNAPPY);
//進行compaction的時候使用壓縮演算法
hColumnDescriptor.setCompactionCompressionType(Compression.Algorithm.SNAPPY);
//讓資料塊快取在LRU快取里面有更高的優先級
hColumnDescriptor.setInMemory(true);
//bloom過濾器,過濾加速
hColumnDescriptor.setBloomFilterType(BloomType.ROW);
descriptor.addFamily(hColumnDescriptor);
最終呼叫 admin.createTable進行建表
建表的時候,注意要檢測命名空間存在,不存在進行創建命名空間,還有建表的時候自動給相應的業務組進行授權,
表結構查看、資料預覽、表洗掉等功能通過HBase java API 就可以實作, 這里不介紹了.
授權管理
先說HBase如何實作鑒權?
我們采用HBase ACL 鑒權機制,具體配置如下:
<property>
<name>hbase.superuser</name>
<value>admin</value>
</property>
<property>
<name>hbase.coprocessor.region.classes</name>
<value>org.apache.hadoop.hbase.security.access.AccessController</value>
</property>
<property>
<name>hbase.coprocessor.master.classes</name>
<value>org.apache.hadoop.hbase.security.access.AccessController</value>
</property>
<property>
<name>hbase.security.authorization</name>
<value>true</value>
</property>
給其他業務組授權都采用超級賬戶進行
下面是權限對照表:
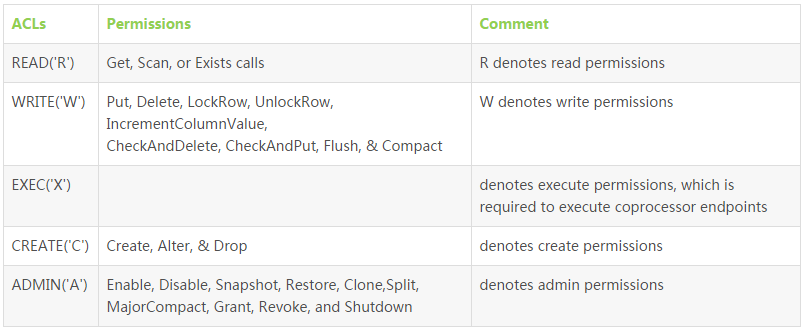
授權流程:

用戶如何進行HBase操作以及平臺如何進行認證和鑒權?
我們開發了一個很簡單的SDK
SDK 實作
SDK 主要的功能就是進行認證和授權、以及獲取相關集群的連接資訊的操作,
整體流程:
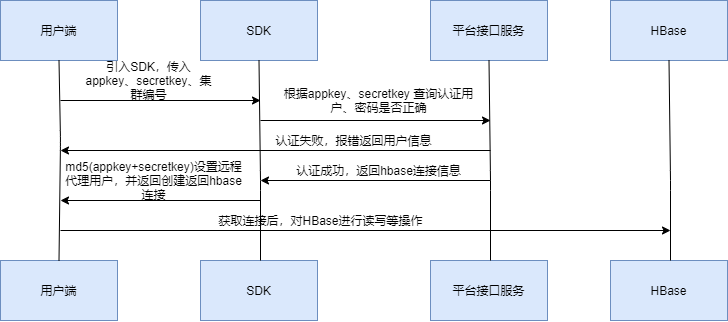
與公司內部系統打通
主要作業就是開發平臺使用HBase任務如何打通認證鑒權等,因為都是基于業務組提交任務,所以很容易實作滿足需求
針對外部服務在容器內使用HBase, 在主機名沒有做DNS 正反向決議之前,需要在容器內配置hosts,
集群資料遷移
主要場景是我們需要將老集群的資料遷移到新集群,要實作跨集群遷移,
老集群版本: HBase: 1.2.0-cdh5.12.0 Hadoop: 2.6.0-cdh5.12.0
新集群版本: HBase: 1.2.0-cdh5.16.2 Hadoop: 2.6.0-cdh5.16.2
使用Distcp方案來進行,一般選擇業務低峰期去做, ,需要保證HBase集群中的表是靜態資料,需要停止業務表的寫入
具體步驟
(1) 在新集群中HDFS 用戶下執行distcp命令
在新集群的NameNode節點執行命令
hadoop distcp -Dmapreduce.job.queue.name=default -pug -update -skipcrccheck -m 100 hdfs://ip:8020/hbase/data/aaa/user_test /hbase/data/aaa/user_test
(2) 執行HBase命令來修復HBase表的元資料,如表名、表結構等內容,會重新注冊到新集群的Zookeeper中,
sudo -u admin hbase hbck -fixMeta "aaa:user_test"
sudo -u admin hbase hbck -fixAssignments "aaa:user_test"
(3)驗證資料:
scan 'aaa:user_test' ,{LIMIT=>10}
(4) 舊集群表洗掉:
#!/bin/bash
exec sudo -u admin hbase shell <<EOF
disable 'aaa:user_test'
drop 'aaa:user_test'
EOF
為了遷移方便,可以將上述命令封裝成一個Shell腳本,如:
#! /bin/bash
for i in `cat /home/hadoop/hbase/tbl`
do
echo $i
hadoop distcp -Dmapreduce.job.queue.name=queue_0001_01 -update -skipcrccheck -m 100 hdfs://old_hbase:9000/hbase/data/$i /hbase/data/$i
done
hbase hbck -repairHoles
總結
本文主要對HBase平臺建設的實踐總結,主要包括創建HBase表相關屬性配置的實作,以及認證鑒權的多租戶設計思路介紹,同時對HBase跨集群表元資訊及資料遷移實踐進行總結.
本文作者: chaplinthink, 關注領域:大資料、基礎架構、系統設計, 一個熱愛學習、分享的大資料工程師轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/394983.html
標籤:大數據