| 值1 | 值2 |
|---|---|
| 1 | 1 |
| 0 | 1 |
| 0 | 1 |
| 0 | 1 |
| 2 | 2 |
| 0 | 2 |
| 0 | 2 |
| 3 | 3 |
| 4 | 4 |
| 0 | 4 |
我在資料框中有一列“value1”,我想重復相同的值,直到下一個數字 > 0。結果我想要的是列“value2”。這是大量資料,因此回圈代碼會很棒。
感謝社區!!
uj5u.com熱心網友回復:
我們可以使用cumsum條件:
library(dplyr)
df %>%
mutate(value2 = cumsum(value1>0))
value1 value2
1 1 1
2 0 1
3 0 1
4 0 1
5 2 2
6 0 2
7 0 2
8 3 3
9 4 4
10 0 4
資料:
df <- structure(list(value1 = c(1L, 0L, 0L, 0L, 2L, 0L, 0L, 3L, 4L,
0L)), class = "data.frame", row.names = c(NA, -10L))
uj5u.com熱心網友回復:
使用 data.table 并與 base 和 dplyr 進行比較
資料表方法
這是一個基于 data.table 的答案版本,它比 base 和 dplyr 版本都快。
set.seed(65L)
df <- data.table(v1 = sample(0:4, 1000, replace = TRUE), v2 = 0)
df[, v2 := cumsum(v1 > 0)]
head(df, 12)
v1 v2
1: 2 1
2: 1 2
3: 3 3
4: 0 3
5: 0 3
6: 4 4
7: 2 5
8: 4 6
9: 4 7
10: 0 7
11: 4 8
12: 2 9
三法比較:等價
set.seed(65L)
df <- data.frame(v1 = sample(0:4, 1000, replace = TRUE), v2 = 0)
df2 <- df
dt <- as.data.table(df)
# data.table
dt[, v2 := cumsum(v1 > 0)]
# base R
if (df$v1[1L] > 0) {df$v2[1L] <- 1}
for (i in 2:length(df$v1)) {
df$v2[i] <- df$v2[i - 1] if (df$v1[i] > 0) {1} else {0}
}
# dplyr
if (df2$v1[1L] > 0) {df2$v2[1L] <- 1}
df2 <- df2 %>% mutate(v2 = cumsum(v1>0))
all.equal(dt, df, check.attributes = FALSE)
[1] TRUE
all.equal(dt, df2, check.attributes = FALSE)
[1] TRUE
all.equal(df, df2, check.attributes = FALSE)
[1] TRUE
三法對比:速度
library(microbenchmark)
microbenchmark(DT = dt[, v2 := cumsum(v1 > 0)],
Base = {if (df$v1[1L] > 0) {df$v2[1L] <- 1};for (i in 2:length(df$v1)) {df$v2[i] <- df$v2[i - 1] if (df$v1[i] > 0) {1} else {0}}},
DP = {if (df2$v1[1L] > 0) {df2$v2[1L] <- 1};df2 <- df2 %>% mutate(v2 = cumsum(v1>0))},
setup = 'set.seed(65L);df <- data.table(v1 = sample(0:4, 1000, replace = TRUE), v2 = 0); df2 <- df; dt <- as.data.table(df)',
control = list(order = 'block'), times = 1000L)
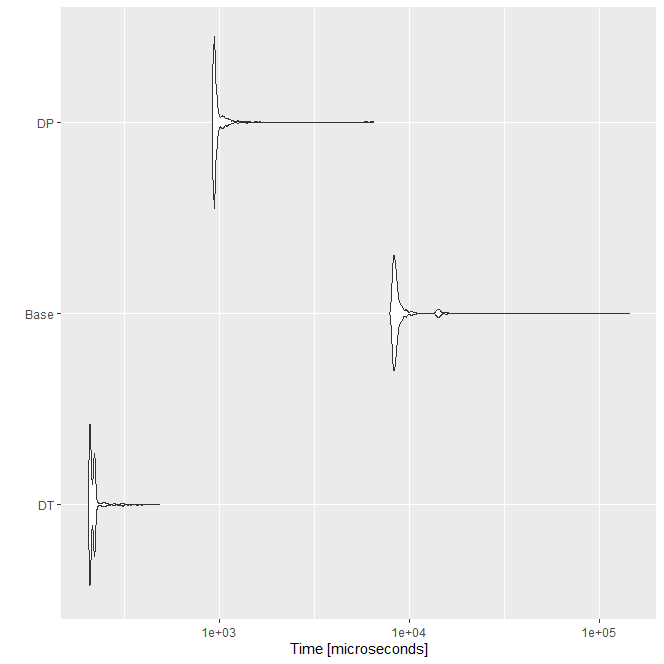
Unit: microseconds
expr min lq mean median uq max neval cld
DT 204.1 210.20 216.6067 212.0 216.80 382.9 1000 a
Base 7956.1 8322.85 8936.3439 8457.6 8702.25 22219.4 1000 c
DP 916.0 930.50 994.4782 939.8 977.60 6157.4 1000 b
因此,該dplyr方法比 base 回圈快約 9 倍,并且該data.table方法dplyr比 base快約 4.5 倍和 40 倍以上!
uj5u.com熱心網友回復:
對于這些情況,我通常用NA值替換 0 ,并用于tidyr::fill()向前復制最后一個非缺失(即非零)值。
下面是一個例子:
df <- data.frame(
value1 = c(1, 0, 0, 0, 2, 0, 0, 3, 4, 0)
)
library(dplyr)
df %>%
mutate(
value2 = ifelse(value1 == 0, NA_real_, value1)
) %>%
tidyr::fill(value2, .direction = "down")
結果:
value1 value2
1 1 1
2 0 1
3 0 1
4 0 1
5 2 2
6 0 2
7 0 2
8 3 3
9 4 4
10 0 4
即使值增加大于/小于 1,這也有效,例如,情況并非如此cumsum()。
uj5u.com熱心網友回復:
不需要使用回圈。使用baseR 的一種選擇是:
df <- data.frame(value1 = c(1,0,0,0,2,0,0,3,4,0))
df$value2 <- cumsum(ifelse(df$value1 > 0, 1, 0))
其中產生:
> df
value1 value2
1 1 1
2 0 1
3 0 1
4 0 1
5 2 2
6 0 2
7 0 2
8 3 3
9 4 4
10 0 4
uj5u.com熱心網友回復:
使用基礎 R
可能有更優雅的方法來做到這一點,但假設列“value2”已經在資料框中,您可以執行以下操作。這個答案僅依賴于基數 R,并且 v1 是增加還是減少也無關緊要,只是它不為零。我將創建一個資料框作為示例。
set.seed(65L)
df <- data.frame(v1 = sample(0:4, 1000, replace = TRUE), v2 = 0)
head(df, 12)
v1 v2
1 2 0
2 1 0
3 3 0
4 0 0
5 0 0
6 4 0
7 2 0
8 4 0
9 4 0
10 0 0
11 4 0
12 2 0
# Handle the first row seperately to get rid of i - 1 headaches
if (df$v1[1L] > 0) {df$v2[1L] <- 1}
# Now the loop. Safer to do seq_len(length(df$v1) - 1) 1 but that's more confusing
for (i in 2:length(df$v1)) {
df$v2[i] <- df$v2[i - 1] if (df$v1[i] > 0) {1} else {0}
}
head(df, 12)
v1 v2
1 2 1
2 1 2
3 3 3
4 0 3
5 0 3
6 4 4
7 2 5
8 4 6
9 4 7
10 0 7
11 4 8
12 2 9
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/397048.html
標籤:r
上一篇:從嵌套串列中提取資料框