背景
平臺目前大多數任務都是Spark任務,用戶在提交Spark作業的時候都要進行的一步動作就是配置spark executor 個數、每個executor 的core 個數以及 executor 的記憶體大小等,這項配置目前基本靠用戶個人經驗,在這個程序中,有的用戶就會設定非常不合理,比如配置的記憶體非常大,實際上任務運行時所占用的記憶體極少. 基于此,希望能有工具來針對任務進行分析,幫助用戶來監控和調優任務,并給出一些建議,使任務更加有效率,同時減少亂配資源影響其他用戶任務運行的情況,
Dr. Elephant介紹
通過調研,發現一個開源專案 Dr. Elephant 基本與想要達成目標一致,
DR.Elephant 介紹:
Dr. Elephant is a job and flow-level performance monitoring and tuning tool for Apache Hadoop and Apache Spark
Dr功能介紹:
https://github.com/linkedin/dr-elephant/wiki/User-Guide
接下來就是需要了解下Dr的架構, 因為我們有些定制化的需求,所以需要了解下架構,以及閱讀原始碼進行相關改造適配,
Dr. Elephant 的系統架構如下圖,主要包括三個部分:
資料采集:資料源為 Job History
診斷和建議:內置診斷系統
存盤和展示:MySQL 和 WebUI
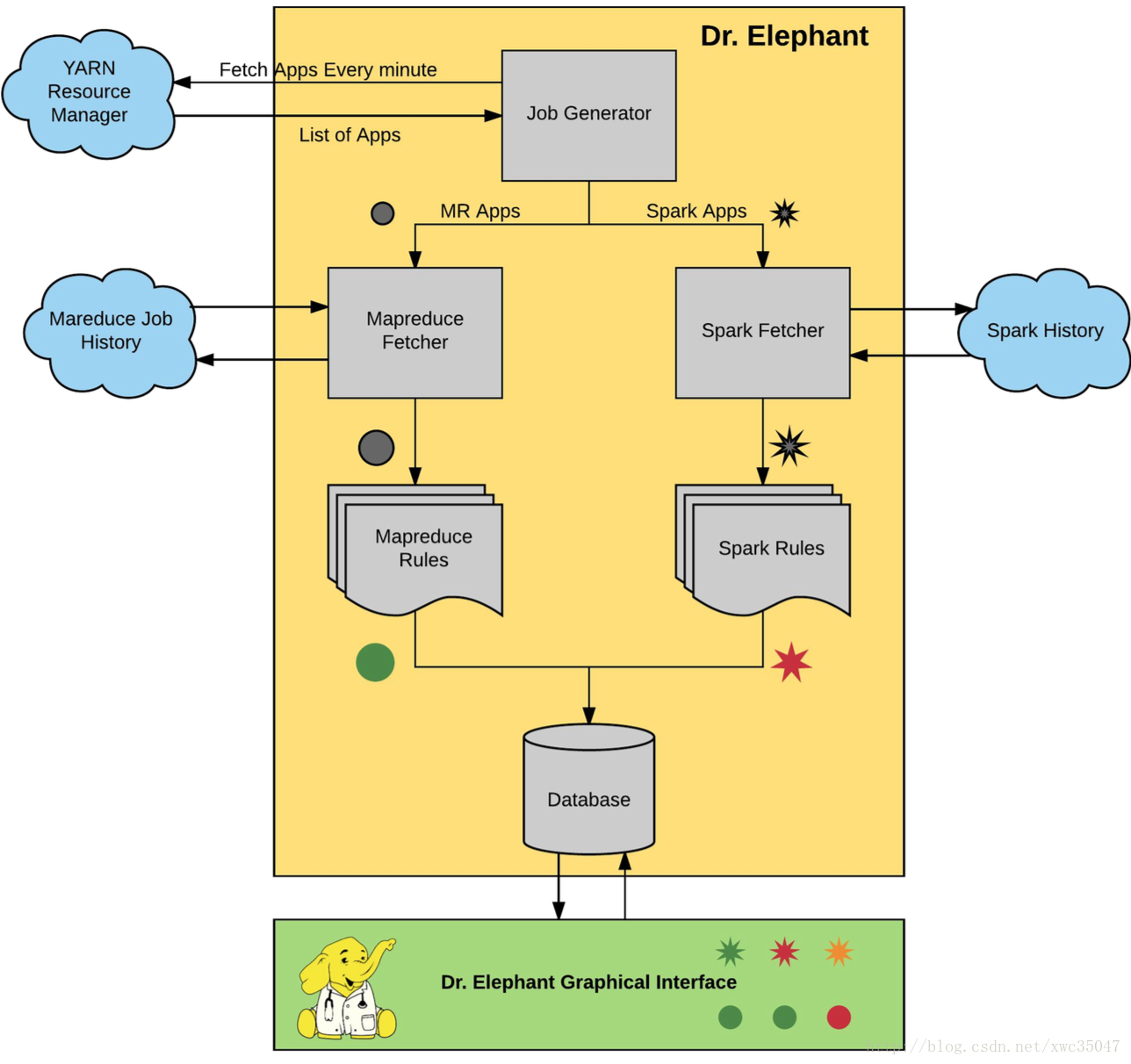
Dr.Elephant定期從Hadoop平臺的YARN資源管理中心獲取近期所有的任務,這些任務既包含成功的任務,也包含那些失敗的任務,每個任務的元資料,例如任務計數器、配置資訊以及運行資訊都可以從Hadoop平臺的歷史任務服務端獲取到,一旦獲取到了任務的元資料,Dr.Elephant就基于這些元資料運行啟發式演算法,然后會產生一份該啟發式演算法對該任務性能的診斷報告,根據每個任務的執行情況,這份報告會為該任務標記一個待優化的嚴重性級別,嚴重性級別一共分為五級,報告會對該任務產生一個級別的定位,并通過級別來表明該任務中存在的性能問題的嚴重程度,
啟發式演算法具體要做的事情就是:
- 獲取資料
- 量化計算打分
- 將分值與不同診斷等級閾值進行比較
- 給出診斷等級
原始碼決議與改造
首先我們要知道Dr整體的運行流程是怎么樣的?
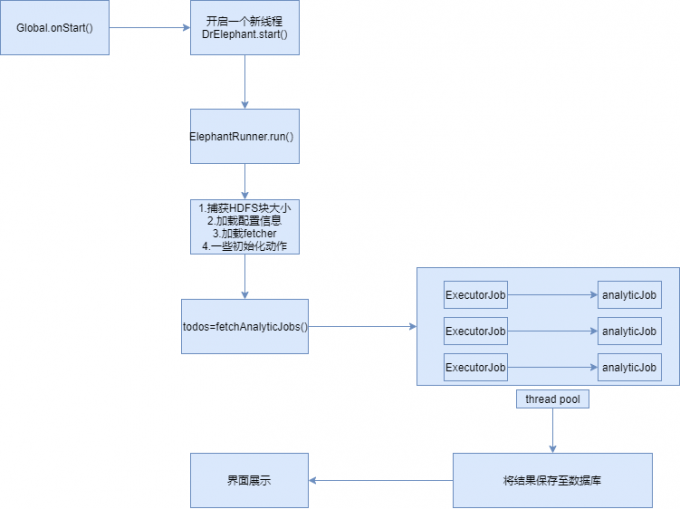
因為我們只需要關注Spark任務,下面主要介紹下Spark指標如何采集?
上面我們已經知道Dr執行的大致流程, 我們只采集spark任務, 所以不用太多額外的代碼和抽象.
只需要關鍵的幾個步驟改造即可:
1.首先還是通過yarn api 獲取執行的job, 我們只需要對ExecutorJob直接使用org.apache.spark.deploy.history.SparkFSFetcher#fetchData方法, 獲取eventlog, 并對eventlog進行重放決議
-
將決議后的資料,獲取相關需要的資訊,直接寫入mysql庫
-
因為涉及連接hdfs,yarn 等服務,將hdfs-site.xml,core-site.xml等檔案放置配置目錄下
-
最終將程式改造成一個main方法直接運行的常駐行程運行
采集后的主要資訊:
- 采集stage相關指標資訊
- 采集app任務配置、executor個數、核數等,執行開始時間、結束時間、耗時等
改造后整體流程如下:
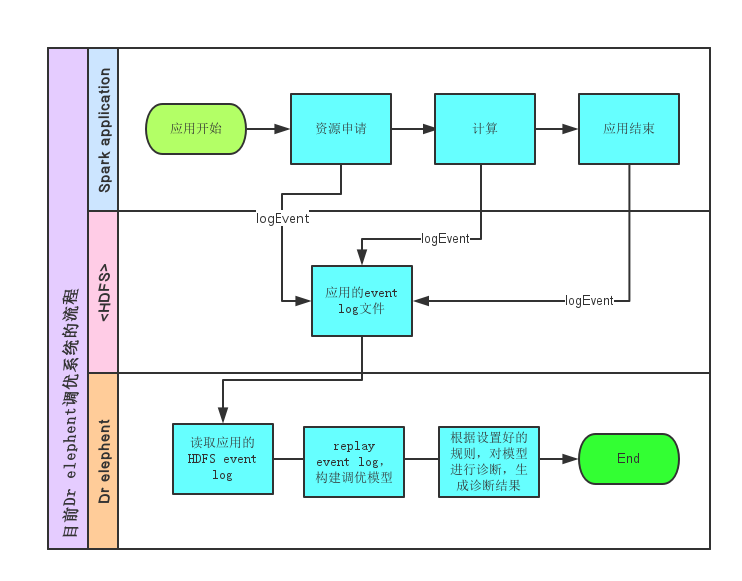
規則平臺進行配置, 有了采集資料, 根據規則對相關指標定級, 并以不同顏色區分展示,并給出相關診斷意見.
總結
本文主要根據平臺用戶平常提交的spark任務思考,調研引入Dr. Elephant, 通過閱讀Dr 相關原始碼, 明白Dr 執行整體流程并對代碼進行改造,適配我們的需求.最終轉變為平臺產品來對用戶的Spark任務進行診斷并給出相關調優建議.
參考
https://engineering.linkedin.com/blog/2016/04/dr-elephant-open-source-self-serve-performance-tuning-hadoop-spark
https://github.com/linkedin/dr-elephant
https://blog.csdn.net/qq475781638/article/details/90247623
本文作者: chaplinthink, 關注領域:大資料、基礎架構、系統設計, 一個熱愛學習、分享的大資料工程師轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/399545.html
標籤:其他