我正在撰寫一個程式來抓取 PDF 檔案夾,從每個包含相同資料欄位的表中提取一個表。其中一份 PDF 中表格的示例螢屏截圖:
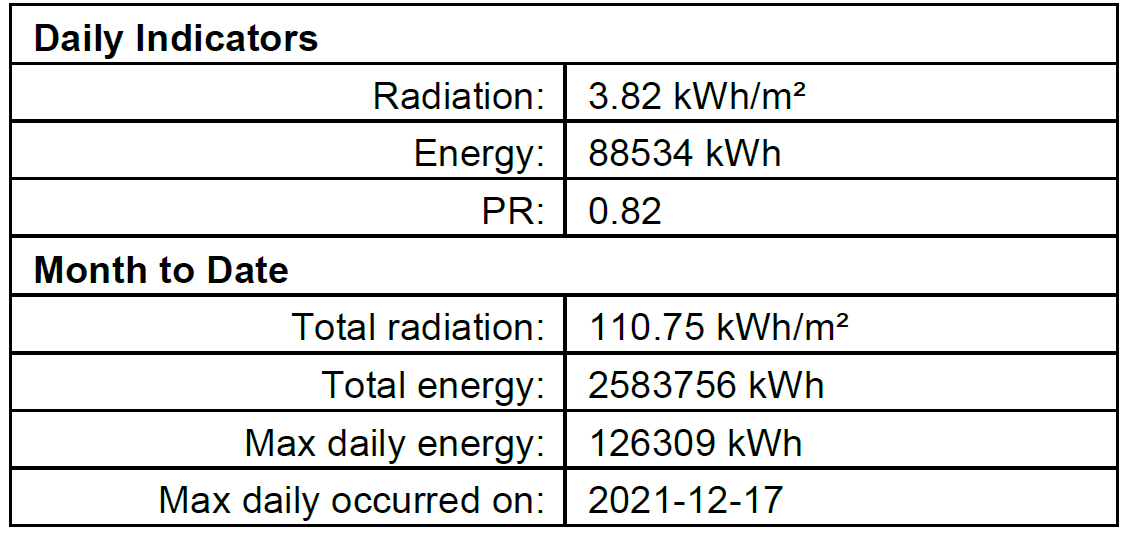
該程式的目標是生成一個電子表格,其中包含來自每個 PDF 的所有資料,并在一行中顯示 PDF 的日期,并將公共欄位作為列標題。第一列中的日期應該是 PDF 檔案名中的日期。它應該是這樣的:
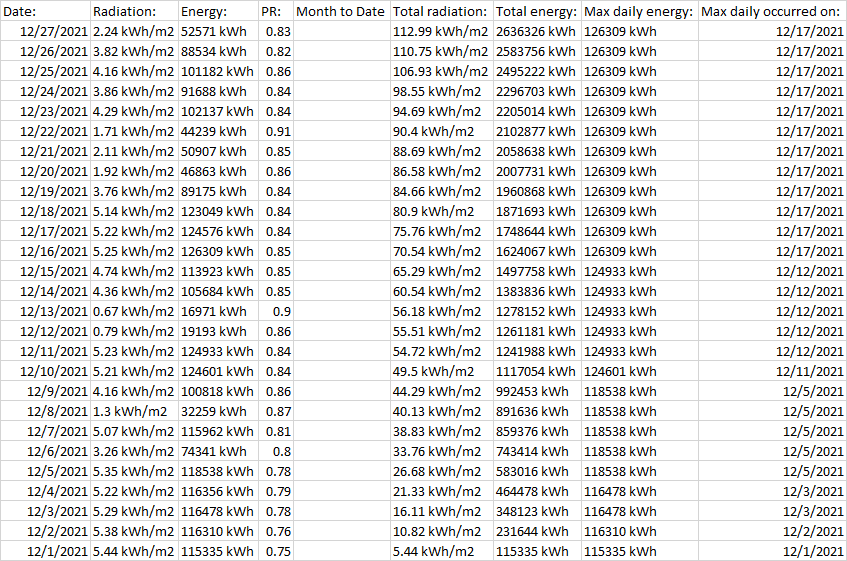
當我將資料提取到資料框中并為“欄位”和報告日期添加列標題時,它看起來像這樣:
Field 2021-12-04
0 Radiation: 5.22 kWh/m2
1 Energy: 116356 kWh
2 PR: 0.79
3 Month to Date NaN
4 Total radiation: 21.33 kWh/m2
5 Total energy: 464478 kWh
6 Max daily energy: 116478 kWh
7 Max daily occurred on: 2021-12-03
然后我將索引設定為第一列,因為這些是我將基于的公共欄位。當我這樣做時,日期列標題似乎與欄位標題處于不同的級別?我不確定這里會發生什么:
2021-12-20
Field
Radiation: 3.76 kWh/m2
Energy: 89175 kWh
PR: 0.84
Month to Date NaN
Total radiation: 84.66 kWh/m2
Total energy: 1960868 kWh
Max daily energy: 126309 kWh
Max daily occurred on: 2021-12-17
然后我轉置,結果看起來不錯:
Field Radiation: Energy: ... Max daily energy: Max daily occurred on:
2021-12-13 0.79 kWh/m2 19193 kWh ... 124933 kWh 2021-12-12
然后我進行連接,結果看起來不錯,但由于某種原因,帶有日期的第一列丟失了。有什么建議?
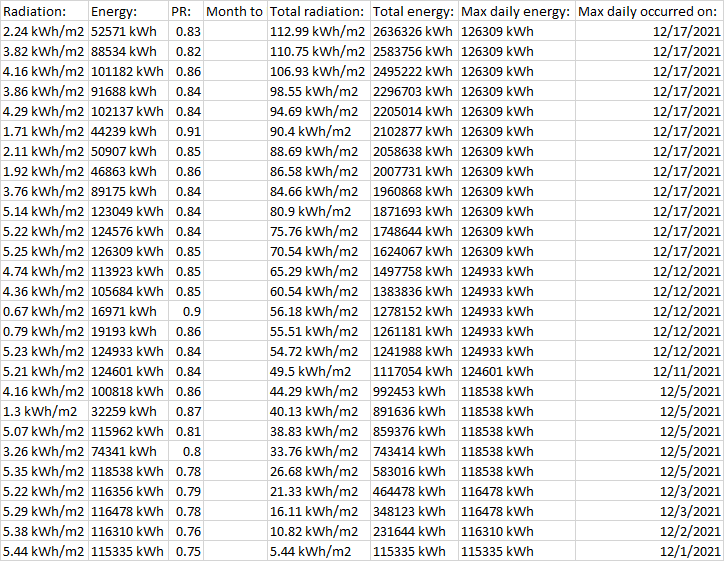
import tabula as tb
import os
import glob
import pandas as pd
import datetime
import re
begin_time = datetime.datetime.now()
User_Profile = os.environ['USERPROFILE']
Canadian_Combined = User_Profile '\Combined.csv'
CanadianReportsPDF = User_Profile '\Canadian Reports (PDF)'
CanadianDailySummaryTable = (72,144,230,465)
CanadianDailyDF = pd.DataFrame()
def CanadianScrape():
global CanadianDailyDF
for pdf in glob.glob(CanadianReportsPDF '/*Daily*'):
# try:
dfs = tb.read_pdf(os.path.abspath(pdf), area=CanadianDailySummaryTable, lattice=True, pages=1)
df = dfs[0]
date = re.search("([0-9]{4}\-[0-9]{2}\-[0-9]{2})", pdf)
df.columns = ["Field",date.group(0)]
df.set_index("Field",inplace=True)
# print(df.columns)
print(df)
df_t = df.transpose()
# print(df_t)
CanadianDailyDF = pd.concat([df_t,CanadianDailyDF], ignore_index=False)
# print(CanadianDailyDF)
# except:
# continue
# print(CanadianDailyDF)
CanadianDailyDF.to_csv(Canadian_Combined, index=False)
CanadianScrape()
print(datetime.datetime.now() - begin_time)
編輯**在轉置后添加了一個 insert() 行,以根據 Ezer K 建議重新添加到日期列中,這似乎已經解決了。
df.columns = ["Field",date.group(0)]
df.set_index("Field",inplace=True)
df_t = df.transpose()
df_t.insert(0, "Date:", date.group(0))
uj5u.com熱心網友回復:
很難確切地說,因為您的示例很難重現,但似乎您正在更改列名稱而不是添加欄位。嘗試在您的函式中切換這些行:
df.columns = ["Field",date.group(0)]
df.set_index("Field",inplace=True)
df_t = df.transpose()
用這些:
df_t = df.transpose()
df_t.insert(0, "Date:", date.group(0))
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/400750.html
上一篇:如何將列值從FirstnameLastname轉換為F.Lastname
下一篇:從函式創建資料框