我有一個如下所示的資料框
df = pd.DataFrame(
{'sub_code' : [np.nan, 'CSE01', np.nan,
'CSE02', 'CSE03', 'CSE02',
'CSE03', 'CSE02'],
'stud_level' : [101, 101, 101, 101,
101, 101, 101, 101],
'grade' : ['STA','STA','PSA','STA','STA','SSA','PSA','QSA']})
我想做以下
sub_codea)通過參考列在列中填寫 NA grade。
b) 例如:等級在( )中STA有對應sub_code的非 NA 值row 1,3 and 4row 0 has NA value
c) 從列中復制第一個非 NA ( CSE01) 值grade并將其放入sub_code列 ( row 0)
我嘗試了以下
m = df['sub_code'].isna()
df.loc[m, 'sub_code'] = np.where(df.loc[m, 'grade'].ne(np.nan), df['sub_code'], 'not filled')
我希望我的輸出如下
uj5u.com熱心網友回復:
df['sub_code'] =df.groupby(['grade'])['sub_code'].bfill().ffill()
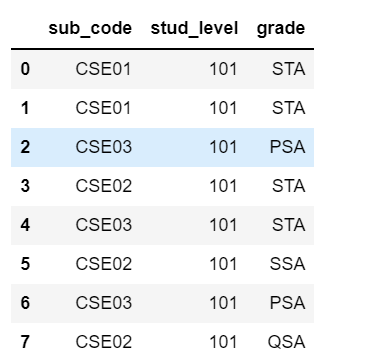
sub_code stud_level grade
0 CSE01 101 STA
1 CSE01 101 STA
2 CSE03 101 PSA
3 CSE02 101 STA
4 CSE03 101 STA
5 CSE02 101 SSA
6 CSE03 101 PSA
7 CSE02 101 QSA
uj5u.com熱心網友回復:
groupby“等級”并用于first獲取每個等級中的第一個非 NaN 子代碼。然后使用np.where在“sub_code”中填充 NaN 值:
mapper = df.groupby('grade')['sub_code'].first()
df['sub_code'] = np.where(df['sub_code'].isna(), df['grade'].map(mapper), df['sub_code'])
或者代替第二行,您還可以使用fillna:
df['sub_code'] = df.set_index('grade')['sub_code'].fillna(mapper)
輸出:
sub_code stud_level grade
0 CSE01 101 STA
1 CSE01 101 STA
2 CSE03 101 PSA
3 CSE02 101 STA
4 CSE03 101 STA
5 CSE02 101 SSA
6 CSE03 101 PSA
7 CSE02 101 QSA
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/418596.html
標籤:
上一篇:熊貓資料框Json展平所有行