【開發】SQL優化思路(以oracle為例)
powered by wanglifeng https://www.cnblogs.com/wanglifeng717
單表查詢的優化思路
單表查詢是最簡單也是最重要的模塊,它是多表等查詢的基礎,
避免對資料重復掃描
能一次掃描拿到的資料,不要重復掃描,查一次庫能解決的問題,最好不要多次查,資料的讀取非常消耗資源,減少對資料塊的掃描,
例如:
1.SELECT COUNT (*)
FROM employees
WHERE salary < 2000;
2.SELECT COUNT (*)
FROM employees
WHERE salary BETWEEN 2000 AND 4000;
3.SELECT COUNT (*)
FROM employees
WHERE salary>4000;
統計任務經常用的陳述句,其實每個陳述句基本都把全表或索引掃了一遍,既然要全掃,就把味訓會,能一次搞定的就一次搞定,
改寫成
SELECT COUNT (CASE WHEN salary < 2000 THEN 1 ELSE null END) count1,COUNT (CASE WHEN salary BETWEEN 2001 AND 4000 THEN 1 ELSE null END) count2,COUNT (CASE WHEN salary > 4000 THEN 1 ELSE null END) count3 FROM employees;
嚴格來說,我們不推薦寫過度復雜“炫技”的SQL,不要生搬硬套示例,只是為了讓大家有個“節省持家”的意識,
例如如下經典寫法,通過object_id欄位上的索引全掃一遍,拿到了多種類別資訊,不要分三次查詢,
select max(object_id),min(object_id),sum(object_id),avg(object_id),count(object_id) from t where object_id is not null;
從大表中獲取少量資料
從大選小,索引是你的不二選擇,
例如:select t.name,t.status from t where t.pay_order_id = 101803309910017574;
索引利用B+樹的原理可以快速找到某條資料,所以如果你想在大表中找到某條資料,索引是你必須要使用的技術,如上例所示,通過在pay_order_id上索引快速鎖定這條資料的rowid,通過回表找到其他欄位 t.name,t.status,這條陳述句就可以迅速執行,即使是千萬級別表,原因還是全表掃描讀的塊非常多,而索引鎖定資料快,讀的塊非常少,所以時間很快,
如果表記錄數很少,使用索引效率反而低,例如,只有幾十條記錄,所有資料在一個
block 內,則全表掃描只需 1 個 block 的 io,而索引讀由于回表等可能需要幾個 block,
從大表中獲取部分資料
例如:select t.name,t.status from t where t.pay_order_id < 101803309910017574;
上例所示,執行計劃可能是全表掃描,也可能走索引,
主要決定因素之一是oracle的代價計算(cost),如果資料量比較大,走索引讀,每條資料都伴隨著一次回表操作,而全表掃描可以一次讀多個塊進記憶體,兩種方式相比之下,哪條路徑的代價低,oracle就會選擇哪條,
所以,全表掃描的速度不一定慢,如果上述的SQL沒有滿足你的性能需求,且需求不能變,導致SQL已經不能修改時,我們可以考慮能否消除索引的回表操作,無論表多大,結果集多大,一旦所要的資料在索引塊中都能找到,就不需要回表,因為索引全掃的塊肯定比全表掃的塊少的多的多,oracle肯定走索引全掃,
例如:
create index t_union_uuid_order_id on t(pay_order_id,uuid);
select uuid,pay_order_id from t where t.pay_order_id<101803300910017574;
如上例所示,所要欄位資料在組合索引塊中都能找到,所以沒有回表操作,而索引塊的數量遠遠小于全表資料的塊數量,即使索引全掃,性能也非常好,
絕大多數情況下,這條select t.name,t.status from t where t.pay_order_id < 101809910017574陳述句我們可以控制下結果集,讓索引即使回表,代價也遠低于全表掃描,
組合索引不推薦三個及以上的欄位建立組合索引,如果需要的欄位非常多,不方便建立組合索引,建議控制結果集,少量快速多次,索引或兩欄位組合索引,多手段結合使用,具體使用要具體問題具體分析,宗旨就是控制結果集,使得走索引的代價低于全表掃描,然后利用索引快速,讀塊少的優點提高效率,這樣分批幾次拿資料,可能速度比一次全拿還快,事實是結果集控制的好,往往全表掃描的效率都能滿足需求,更何況是索引掃描,
從大表中獲取大量資料
這種場景首先要反問的就是這個需求是否存在問題,是否真的適合用關系型資料庫?如果確實有這種需求,大表的資料量往往是驚人的,只能分頁去拿,而ORACLE的三層select分頁會越分越慢,
SELECT *
FROM (SELECT TA.*, ROWNUM ROW_NUM
FROM (select UUID, pay_order_id
from t
order by pay_order_id) TA
WHERE ROWNUM <= 100)
WHERE ROW_NUM > 0;
主要矛盾就是內層的WHERE ROWNUM <= 100,隨著頁數增加,結果集越來越大,2.order by的排序非常耗費性能,尤其大結果集的排序,3. 外層的WHERE ROW_NUM > 0隨著頁數越來越大,需要過濾的結果集也越來越大,
推薦方式:
SELECT t.*
FROM (select uuid, pay_order_id
from t
where t.pay_order_id is not null【*注】如果沒有非空約束必須顯示標明,否則索引失效
and t.pay_order_id >= '101809020001428452'
order by t.pay_order_id) t
WHERE ROWNUM <= 100;
pay_order_id 欄位的需求是只增不減,為了不重不漏必須排序,索引是有序的,我們想用索引抵消掉排序,所以要查看執行計劃,必須要走到索引,WHERE ROWNUM <= 100在oracle優化中會被推到內層陳述句中,所以實際結果集是t.pay_order_id >= '101809020001428452'之后的100條資料,所以結果集控制住了,索引代價肯定低于全表掃描,肯定走索引,索引又抵消了排序,同時 WHERE ROWNUM <= 100;每頁都是100,rownum的性能損耗也控制住了,
這樣額外的代價是,程式每次要記住最后一條pay_order_id,下次分頁的時候將其帶入,
推廣到其他應用則可以選擇表中的create_time欄位代替pay_order_id,
多表查詢的優化思路
多表連接把握住連接方式
多表查詢和單表查詢,唯一不同的就是把握住連接方式,只要連接方式把握住,多表查詢其實就是多次單表查詢,
三種連接方式:
nested loops join拿驅動表的結果集,去連接另外一個表,類似于兩重嵌套回圈(典型使用:小表驅動大表),
hash join 拿驅動表的結果集去做hash表,PGA區,結果集大了,會到磁盤里,
merge join 無驅動表的概念,較少用到,對于連接鍵有序,
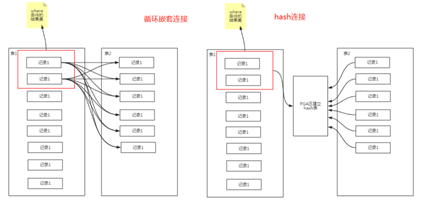
powered by wanglifeng https://www.cnblogs.com/wanglifeng717
從原理圖可以看出,回圈嵌套連接和hash連接中驅動表非常關鍵,準確說驅動表的結果集非常關鍵,回圈嵌套連接的結果集大了,雙層回圈非常低效,哈希連接結果集大了可能導致排序開銷變大,PGA區放不下等問題,
驅動表是oracle自動選擇的,默認是加了過濾條件后,結果集小的那個表,如果查看執行計劃,驅動表不如你所愿,你需要檢查結果集是否相比另一個表結果集來說,明顯是小結果集,或者自動收集資訊不準確,需要更新,
如果是多表連接查詢少量資料,推薦走回圈嵌套連接,
create index n_index_order_id on n(order_id);
create index t_index_query_id on t(query_id);
select t.id ,t.name,n.address from n, t where t.pay_order_id=n.order_id and t.query_id='261801163544557068';
在驅動表的過濾條件上建立索引,快速鎖定需要的少量資料行,在被驅動表的連接欄位上建立索引,方便連接條件迅速匹配,這樣的配合,就算兩個表都是千萬級別的表,只要索引不失效,速度都非常快,
如果是多表連接要查詢出一部分資料,推薦走哈希連接
首先過濾條件過濾出小結果集,小結果集是個相對的概念,有時1000條算小結果集,有時10條也算大結果集,這里的小結果集一般在百條量級,
哈希連接的特點就是,無論驅動表的結果集在一定范圍內如何變化,理論上,一次查詢的時間近似等于掃一遍被驅動表的時間,性能表現相當高效和穩定,
控制驅動表的結果集,在被驅動表的連接欄位上建立索引,忽略回表等細節,確認走到索引,這樣一次查詢的時間近似等于被驅動表的索引全掃時間,而我們知道,索引塊相對全表塊是非常少的,索引全掃非常高效,
走哪種連接方式,是oracle自動選擇的,oracle選擇的規則就是基于上述原理,所以我們決定不了走哪種執行計劃,但是我們能讓oracle”不得不走”哪種執行計劃,
控制住結果集
控制結果集,不僅體現在單表查詢的索引選擇問題,還有體現在多表查詢的連接方式和效率上,
除此之外還存在很多誤區,結果集的概念并不是簡單的資料量,而是一種意識,有控制結果集的意識,而不是教條主義的定義多少數量算大結果集,
結果集經典示例:
把in換成exists就完事了,性能就優化了,這是常犯的誤區,
in是判斷一個值是否在某個列中,而exists是判斷一個值是否存在
Select * from tab where id in ( select id from tabel );
In 是先產生子查詢結果集,然后主查詢區結果集中尋找符合要求的欄位串列,符合要求的輸出,
Exists不回傳串列值,而是true或者false,運行方式為,先運行主查詢一次,在去子查詢中查詢與之對應的結果,如果子查詢回傳true則輸出,反之不輸出,在根據主查詢的每一行去子查詢中查詢,
從原理可以看出,如果in的子查詢結果集很大,外層的結果集也很大,相當于兩個大結果集在連接運算,很耗性能,
Exists的運算比in優化了,但是就是搜索內層子查詢的時候優化了,但是關鍵點是要把握住內外層的結果集,如果結果集很大,exists同樣很慢,結果集控制的好,in操作也能符合要求,
總結:不管你多有把握,請一定要看下執行計劃,一定要看下執行計劃,一定要看下執行計劃,,,,
本文來自博客園,作者:wanglifeng,轉載請注明原文鏈接:https://www.cnblogs.com/wanglifeng717/p/15847101.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/421666.html
標籤:Oracle
上一篇:MySQL 索引排序
下一篇:MySQL 索引排序