背景
HDFS 是 Hadoop 生態的默認存盤系統,很多資料分析和管理工具都是基于它的 API 設計和實作的,但 HDFS 是為傳統機房設計的,在云上維護 HDFS 一點也不輕松,需要投入不少人力進行監控、調優、擴容、故障恢復等一系列事情,而且還費用高昂,成本可能是物件存盤是十倍以上,
在存盤與計算分離大趨勢下,很多人嘗試用物件存盤來構建資料湖方案,物件存盤也提供了用于 Hadoop 生態的 connector,但因為物件存盤自身的局限性,功能和性能都非常有限,在資料增長到一定規模后這些問題更加突出,
JuiceFS 正是為了解決這些問題而設計的,在保留物件存盤的云原生特點的同時,更好地兼容 HDFS 的語意和功能,顯著提升整體性能,本文以阿里云 OSS 為例,給大家介紹一下 JuiceFS 是如何全面提升物件存盤在云上大資料場景中的表現的,
元資料性能
為了完整兼容 HDFS 并提供極致的元資料性能,JuiceFS 使用全記憶體的方式來管理元資料,將 OSS 作為資料存盤使用,所有的元資料操作都不需要訪問 OSS 以保證極致的性能和一致性,絕大部分元資料操作的回應時間都在 1ms 以內,而 OSS 通常要幾十到一百毫秒以上,下面是使用 NNBench 進行元資料壓測的結果:
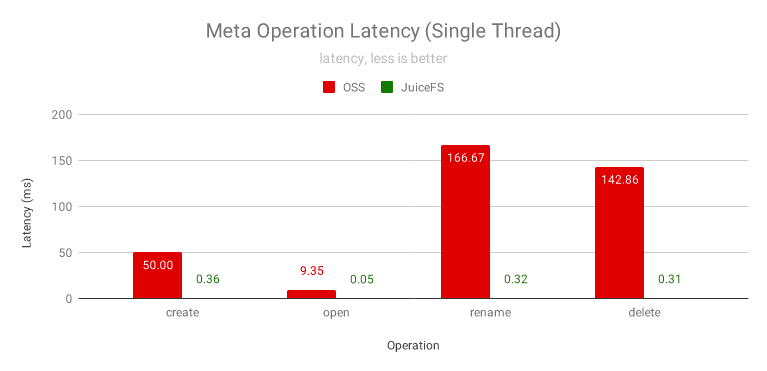
上圖中的 rename 操作還只是針對單個檔案的,因為它要拷貝資料所以很慢,在大資料實際的任務中通常是對目錄做重命名,OSS 是 O(N) 復雜度,會隨著目錄里檔案數量的增多顯著變慢,而 JuiceFS 的 rename 的復雜度是 O(1) 的, 只是服務器端的一個原子操作,不管目錄多大都可以一直這么快,
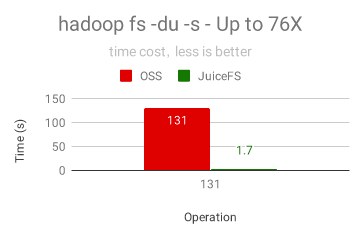
類似的還有 du 操作,它是要看一個目錄里所有檔案的總大小,在管理容量或者了解資料規模時非常有用, 下圖是對一個 100GB 資料(包含3949個子目錄和檔案)的目錄做 du 的時間對比,JuiceFS 比 OSS 快 76倍!這是因為 JuiceFS 的 du 是基于服務器端記憶體中實時統計好的大小即時回傳的,而 OSS 需要通過客戶端遍歷目錄下的所有檔案再累加求和,如果目錄下的檔案更多的話,性能差距會更大,
順序讀寫性能
大資料場景有很多原始資料是以文本格式存盤的,資料以追加方式寫入,讀取以順序讀為主(或者是順序讀其中一個分塊),在訪問這類檔案時,吞吐能力是一個關鍵指標,為了能夠更好地支持這樣的場景,JuiceFS 會先將它們切割成 64MB 的邏輯 Chunk,再分割成 4MB(可配置)的資料塊寫入物件存盤,這樣可以并發讀寫多個資料塊以提升吞吐量,OSS 也支持分塊上傳,但有分塊大小和分塊數量的限制,而 JuiceFS 沒有這些限制,單個檔案可達 256PB,
同時,這類文本格式的檔案還非常容易被壓縮,JuiceFS 內置的 LZ4 或者 ZStandard 壓縮演算法可以在并行讀寫的同時進行壓縮/解壓縮,不但可以降低存盤成本,還能減少網路流量,進一步提升順序讀寫的性能,對于已經被壓縮過的資料,這兩個演算法也能自動識別,避免重復的壓縮,
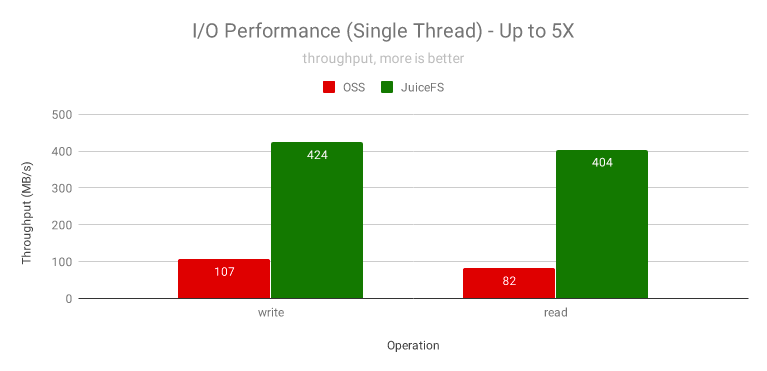
再結合 JuiceFS 的智能預讀和回寫演算法,很容易充分利用網路帶寬和多核 CPU 的能力,將文本檔案的處理性能推向極致,下圖是單執行緒順序 I/O 性能測驗結果,顯示了 JuiceFS 對大檔案(使用不能被壓縮的隨機資料)的讀寫提速是非常顯著的,
隨機讀性能
對于分析型數倉,通常會將原始資料經過清洗后使用更為高效的列存格式(Parquet 或者 ORC)來存盤,一方面大幅節省存盤空間,還能顯著提升分析的速度,這些列存格式的資料,在訪問模式上跟文本格式很不一樣,以隨機讀居多,對存盤系統的綜合性能有更高的要求,
JuiceFS 針對這些列存格式檔案的訪問特點做了很多優化,將資料分塊快取到計算節點的 SSD 盤上是其中最核心的一點,為了保證快取資料的正確性,JuiceFS 對所有寫入的資料都使用唯一的 ID 來標識 OSS 中的資料塊,并且永不修改,這樣快取的資料就不需要失效,只在空間不足時按照 LRU 演算法清理即可,Parquet 和 ORC 檔案通常只有區域列是熱點,快取整個檔案或者一個 64MB 的 Chunk 會浪費空間,JuiceFS 采取的是以 1MB 分塊(可配置)為單位的快取機制,
計算集群中通常只會有一個快取副本,通過一致性哈希演算法來決定快取的位置,并利用調度框架的本地優化機制來將計算任務調度到有資料快取的節點,達到跟 HDFS 的資料本地化一樣甚至更好的效果,因為 HDFS 的三個副本通常是隨機調度的,作業系統頁快取的利用率會比較低,JuiceFS 的資料快取會盡量調度到同一個節點,系統頁快取的利用率會更高,
當調度系統不能做本地化調度時,比如 SparkSQL 在讀小檔案時,會隨機地把多個小檔案合并到同一個任務中,就喪失了本地化特性,即使使用 HDFS 也是如此,JuiceFS 的分布式快取很好地解決了這個問題,當計算任務未能調度到快取所在節點時,JuiceFS 客戶端會通過內部的 P2P 機制來訪問快取的資料,大幅提高快取命中率和性能,
我們選取查詢時間比較有代表性的 q2 來測驗不同分塊大小和快取設定情況的加速效果:
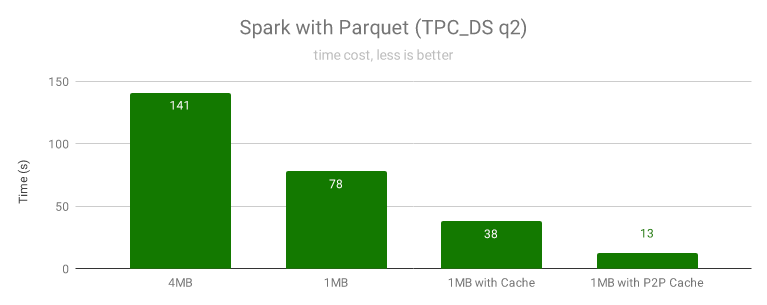
當沒有啟用快取時,使用 1MB 的分塊比 4MB 的分塊性能更好,因為 4MB 的分塊會產生更多的讀放大,導致隨機讀變慢,也會浪費很多網路帶寬導致網路擁堵,
啟用快取后,Spark 可以直接從快取的資料塊上做隨機讀,大大的提高了隨機讀性能,因為 SparkSQL 會將小檔案隨機合并到一個任務中,導致大部分檔案沒辦法調度到有快取的那個節點,快取命中率很低,部分未命中快取的讀請求只能讀物件存盤,嚴重拖慢了整個任務,
在啟用了分布式快取后,不管計算任務調度到哪,JuiceFS 客戶端都能夠通過固定的節點讀到快取的速度,快取命中率非常高,速度也非常快(通常第二次查詢就能獲得顯著加速效果),
JuiceFS 還支持隨機寫,但大資料場景不需要這個能力,OSS 也不支持,就不做對比了,
綜合性能
TPC-DS 是大資料分析場景的典型測驗集,我們用它來測驗一下 JuiceFS 對 OSS 的性能提升效果,包括不同資料格式和不同分析引擎,
測驗環境
我們在阿里云上使用 CDH 5.16 (估計是使用最為廣泛的版本)搭建了一個集群,詳細配置和軟體版本如下:
Apache Spark 2.4.0.cloudera2
Apache Impala 2.12
Presto 0.234
OSS-Java-SDK 3.4.1
JuiceFS Hadoop SDK 0.6-beta
Master: 4 CPU 32G 記憶體,1臺
Slave: 4 CPU 16G 記憶體,200G 高效云盤 x 2,3臺
Spark 引數:
master yarn
driver-memory 3g
executor-memory 9g
executor-cores 3
num-executors 3
spark.locality.wait 100
spark.dynamicAllocation.enabled false
測驗資料集使用 100GB 的 TPC-DS 資料集,多種存盤格式和引數,完整跑完 99 條測驗陳述句需要太多時間,我們選取了前面 10 條陳述句作為代表,已經包括各種型別的查詢,
寫入性能
通過讀寫同一張表來測驗寫入性能,使用的 SQL 陳述句是:
INSERT OVERWRITE store_sales SELECT * FROM store_sales;
我們對比了未磁區的文本格式和按日期磁區的 Parquet 格式,JuiceFS 都有顯著性能提升,尤其是磁區的 Parquet 格式,通過分析發現,OSS 花了很多時間在 Rename 上,它需要拷貝資料,還不能并發,而 Rename 在 JuiceFS 里是一個原子操作,瞬間完成,
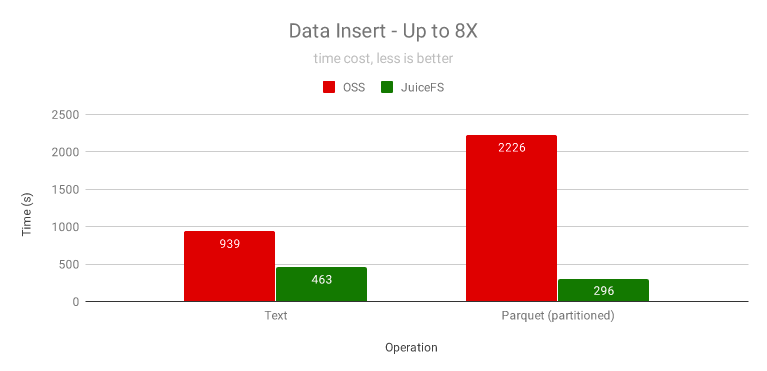
SparkSQL 查詢性能
Apache Spark 的使用非常廣泛,我們使用 SparkSQL 來測驗文本、Parquet 和 ORC 這 3 種檔案格式下 JuiceFS 的提速效果,其中文本格式是未磁區的,Parquet 和 ORC 格式是按照日期磁區的,
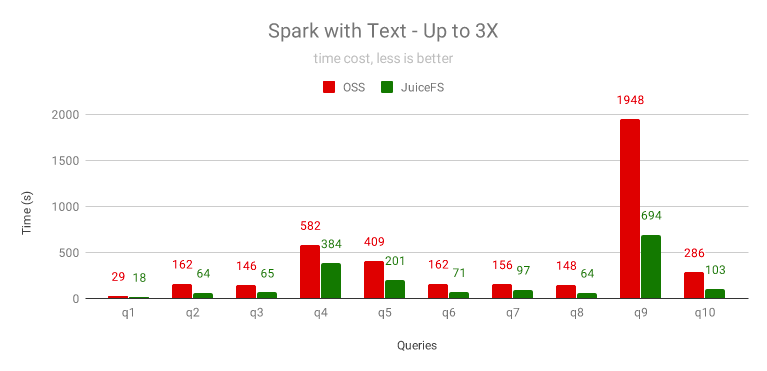
對于未磁區的文本格式,需要掃描全部文本資料,主要瓶頸在 CPU,JuiceFS 的提速效果有限,最高能提升 3 倍,需要注意的是,如果使用 HTTPS 訪問 OSS,Java 的 TLS 庫比 JuiceFS 使用的 Go 的 TLS 庫慢很多,同時 JuiceFS 對資料做了壓縮,網路流量也會小很多,因此在兩者都啟用 HTTPS 來訪問 OSS 時,JuiceFS 效果更好,
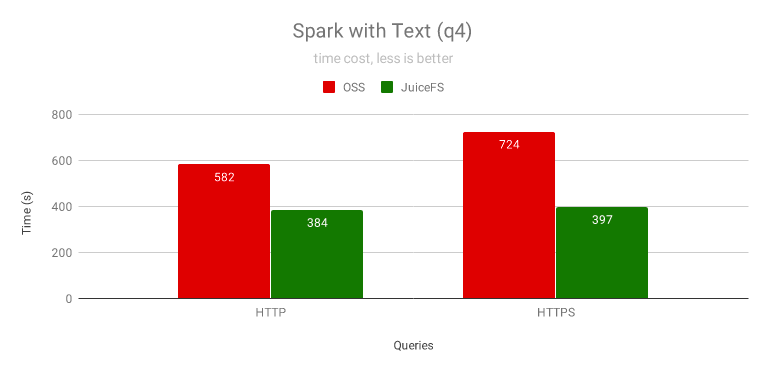
上圖說明了在使用 HTTPS 的情況下,JuiceFS 的性能幾乎沒有變化,而 OSS 卻下降很多,
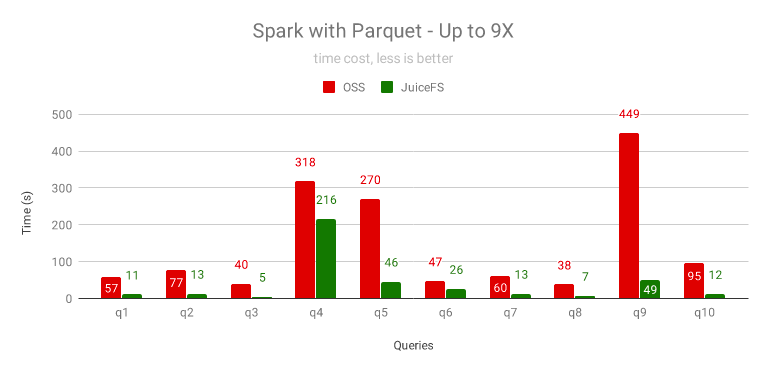
對于互動式查詢,經常要對熱點資料做反復查詢的,上圖是同一個查詢重復 3 次后的結果,JuiceFS 依靠快取的熱點資料大幅提升性能,10 個查詢中的 8 個有幾倍的性能提升,提升幅度最少的 q4 也提升了 30%,
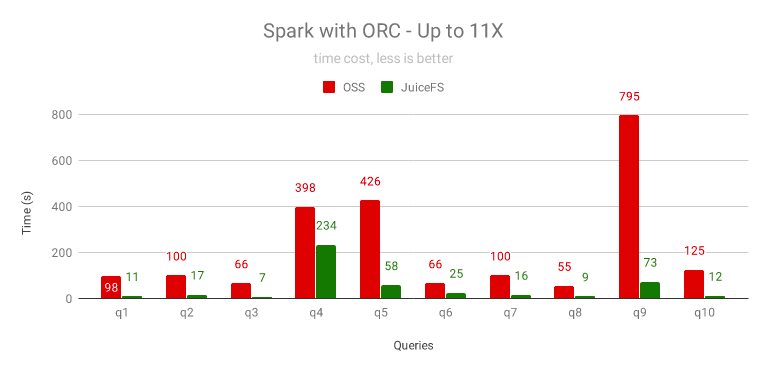
對 ORC 格式的資料集的提速效果跟 Parquet 格式類似,最高提速 11 倍,最少提速 40%,
對所有的資料格式,JuiceFS 都能顯著提升 OSS 的查詢性能,最高超過 10 倍,
Impala 查詢性能
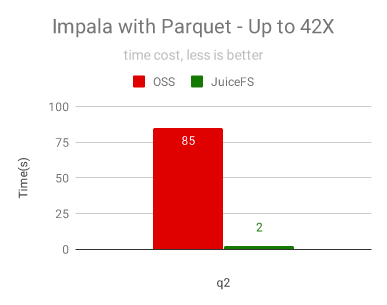
Impala 是性能非常好的互動分析引擎,對 I/O 本地化和 I/O 調度有非常好的優化,不需要使用 JuiceFS 的分布式快取就能夠獲得很好的效果:為 OSS 提速 42倍!
Presto 是與 Impala 類似的查詢引擎,但因為測驗環境下配置的 OSS 不能跟 Presto 作業(原因未知),JuiceFS 沒辦法與 OSS 做比較,
總結
匯總上面的測驗結果,JuiceFS 在所有場景中都能為 OSS 顯著提速,當存盤格式為 Parquet 和 ORC 這類列存格式時提速尤為明顯,寫入提升 8 倍,查詢提升可達 10 倍以上,這顯著的性能提升,不但節省了資料分析人員的寶貴時間,還能大幅減少計算資源的使用,降低成本,
以上只是以阿里云的 OSS 為實體做了性能對比,JuiceFS 的提速能力適用于所有云的物件存盤,包括亞馬遜的 S3、谷歌云的 GCS、騰訊云的 COS 等,也包括各種私有云或者自研的物件存盤,JuiceFS 能顯著提升它們在資料湖場景下的性能,此外,JuiceFS 還提供了更好的 Hadoop 兼容性(比如權限控制、快照等)和完整的 POSIX 訪問能力,是云上資料湖的理想選擇,
如有幫助的話歡迎關注我們專案 Juicedata/JuiceFS 喲! (0?0?)
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/421668.html
標籤:其他
上一篇:MySQL 索引排序
下一篇:sql索引優化思路