一、什么是索引
索引是mysql資料庫中的一種資料結構,就是一種資料的組織方式,這種資料結構又稱為key
表中的一行行資料按照索引規定的結構組織成了一種樹型結構,該樹叫B+樹
二、為何要用索引
優化查詢速度
注意:只能加速索引欄位
三、如何正確的看待索引
錯誤的認知
-
專案上線之后,運行了一段是時間,發現專案運行極卡
- 想要加索引,最好提前加上,在開發之初,定位到常用的查詢,為該欄位提前創建索引,
- 在上線之后想加索引,光把問題定位到索引上就需要耗費很長時間,排查成本很高
-
索引越多越好
- 索引使用與加速查詢的,降低寫效率
- 如果某一張表的ibd檔案中創建了很多棵索引樹,意味著很小一個updata陳述句就會導致很多棵索引數都需要發生變化,從而把硬碟io打上去
四、儲備知識
-
索引的根本原理就是把硬碟的io次數降下來
- 為一張表中的一行行記錄創建索引就是為書的一頁頁內容創建目錄
- 有了目錄以后,我們以后的查詢都應該通過目錄去查詢
-
一次磁盤io帶來的影響
7200轉/分鐘
120轉/s
慢在找的程序,讀的程序是快的,(統稱延遲時間)
一次io的延遲時間=平均尋道時間(大概需要5ms)+平均延遲時間(4ms)---》9ms
9ms對于一個人來說是很慢的,但是對于計算機來說是很長的,比如一臺500 -MIPS 的機器每秒可以執行5億條指令,應為指令是靠電的性質,換句話說就是執行一次io的時間可以執行450萬條指令,資料動則十萬百萬乃至千萬條資料,每次9ms的時間顯然是一個災難,
-
磁盤的預讀
- innodb存盤引擎一頁16k,即一次io讀16k,
- 當一次io時,不光把當前磁盤地址的資料,而是把相鄰的資料也都讀取到記憶體快取區內,因為區域預讀性原理告訴我們,當計算機訪問一個地址的資料的時候,與其相鄰的資料也會很快被訪問到,
五、創建索引的兩個步驟
crate index xxx on user(id);
- 提取索引欄位的值當做key,value就是對應本行記錄
- 以key為基礎比較大小,生成樹型結構
創建索引最好是以占空間小,重復度低的欄位創建索引
六、B+樹
innodb存盤引擎默認的索引結構為B+ 樹,而B+樹是由二叉樹、平衡二叉樹、B樹演變而來的,
二叉樹——》平衡二叉樹——》B 樹 ——》B + 樹
基本概念:
leaf node:葉子節點
non-leaf node:根節點、樹枝節點
二叉樹:
二叉樹有一個特點,它的左節點的 key 值小于當前節點的 key 值,而它的右節點 key 值大于當前節點 key 值,
創建二叉樹索引
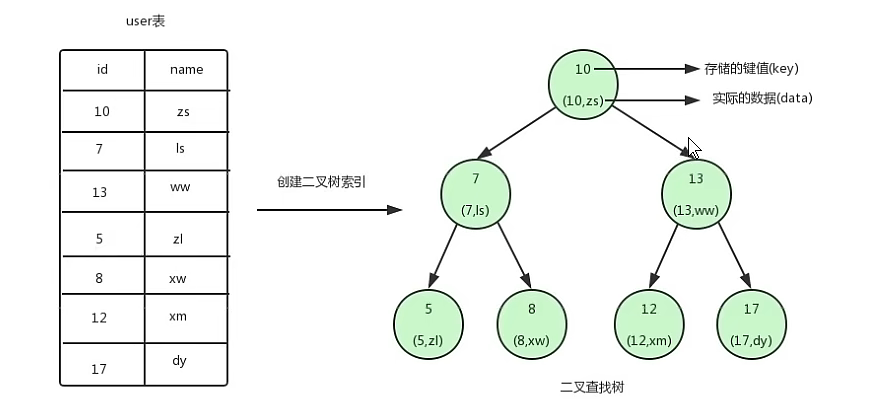
取每一條記錄的id值作為key值,value為本行完整記錄,構建了樹型結構后,查找的速度根樹的高度有關系,
平衡二叉樹:
平衡二叉樹又稱為AVL樹,指的就是左子樹的高度與右子樹的高度相差不超過1,如下圖所示;
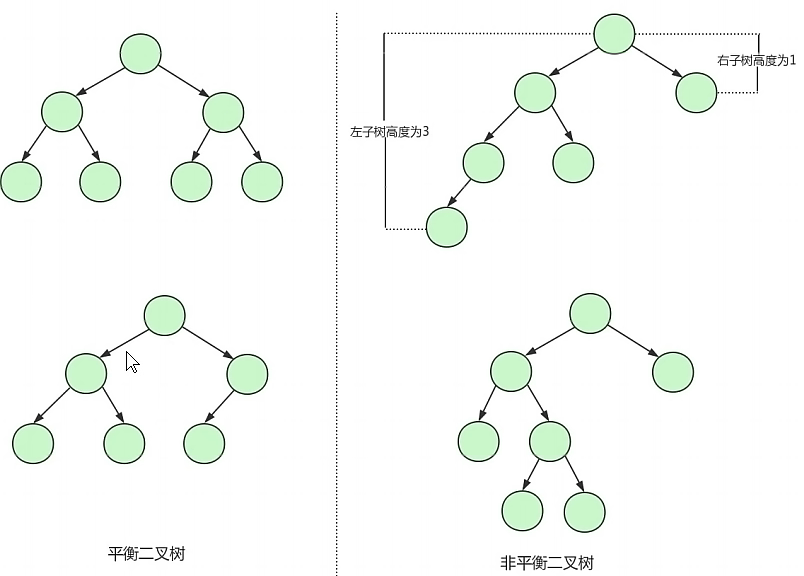
平衡二叉樹相比于二叉樹來說,查找效率更穩定,總體的查找速度也更快,但是并不是基于平衡二叉樹構建索引就可以的,因為每個磁盤塊只放一個節點,每個節點只放一組鍵值對,當資料過大的時候,二叉樹的節點就會非常多,樹的高度也會變高,查找的效率也會變低!
B 樹:
就是構建一個單節點可以存盤多個鍵值對的平衡樹,就是B樹,
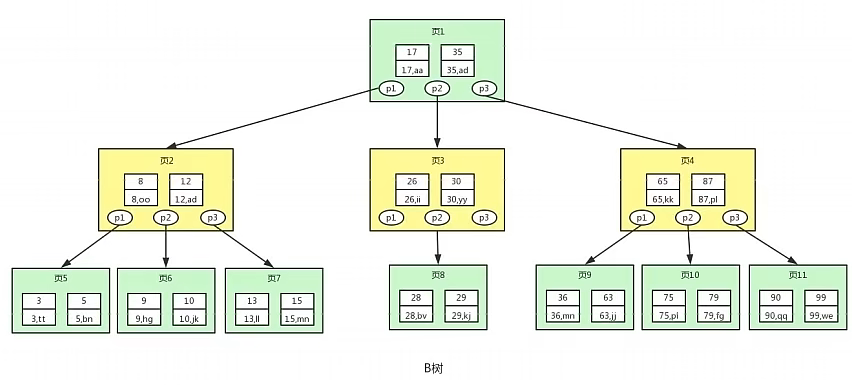
B樹相對于平衡二叉樹,每個節點存盤了更多的鍵值和資料,每個節點有更多的子節點,子節點的個數稱為階,上圖就是一個3階B樹,高度也會很低,這樣B樹的查找磁盤次數也會很少,這樣資料的查找效率就會比平衡二叉樹高,
B+ 樹:
B+ 樹是對B樹的進一步優化,
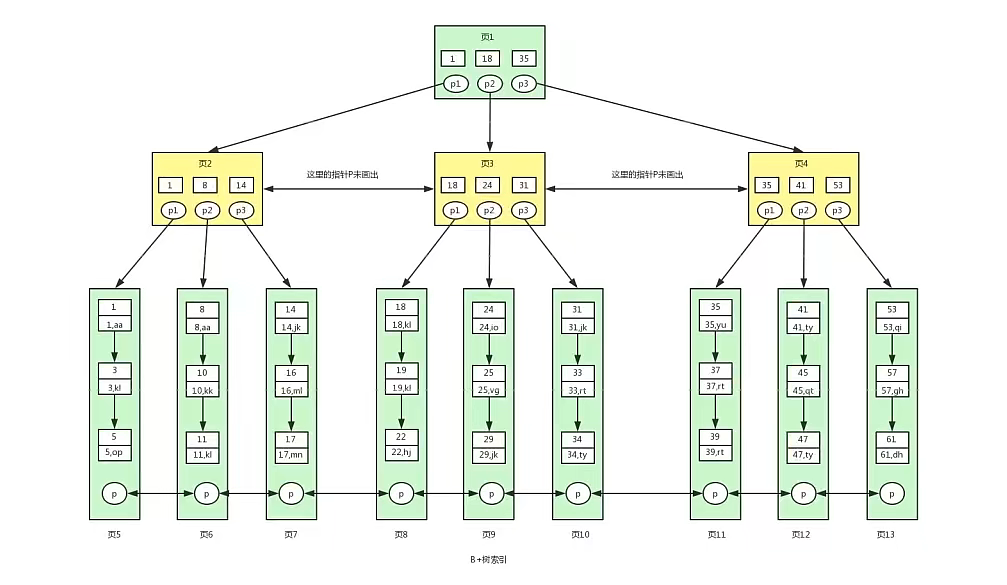
B+ 樹和B 樹有什么不同
-
B+ 樹非葉子節點non-leaf node 上是不存盤資料的,僅存盤鍵,而B 樹的非葉子節點中不僅存盤鍵,也會存盤資料,B + 樹之所以這么做的意義在于;樹一個節點就是一個頁,而資料庫中頁的大小是固定的,innodb 存盤引擎默認一頁為16kb,所以在頁大小固定的前提下,能往一個頁中放入更多的節點,相應的樹的階數就會更大,那么樹的高度必然更矮更胖,如此一來我們查找資料進行磁盤io次數又會再次減少,資料查詢的效率也會更快,
-
B+ 樹的階數是等于鍵的數量的,列如我們的B+ 樹中每個節點可以存盤3個鍵,3層B+ 樹可以存盤
3*3*3=9個資料,所以如果我們的B+ 樹一個節點可以存盤1000個鍵值,那么3層B+ 樹可以存盤1000*1000*1000=10億個資料,而一般節點是常駐記憶體的,所以一般我們查找出10億資料,只需要2次磁盤IO, -
因為B+ 樹索引的所有資料均存盤在葉子節點leaf node ,而且資料是按照順序排列的,那么B+ 樹使得范圍查找,排序查找,分組查找以及去重查找變得例外簡單,而B 樹因為資料分散在各個節點,要實作這一點是很不容易的,
而且B+ 樹中各個頁之間也是通過雙向鏈表連接的,葉子節點找那個的資料是通過單向鏈表連接的,其實在B 樹中我們也可以多各個節點加上鏈表,其實這些不是它們之間的區別,是因為在mysql的innodb存盤引擎中,索引及時這樣存盤的,也就是說B+ 樹索引就是innodb中 B+ 樹索引真正的實作方式,準確的說應該是聚集索引,
在innodb中,我們通過資料頁之間通過雙向鏈表連接以及葉子節點中資料之間通過單向鏈表連接的方式可以找到表中所有的資料,
七、B+ 樹分類
聚集索引、聚簇索引、主鍵索引:
以主鍵欄位值為key構建的B+ 樹,改B+ 樹的葉子節點放的是主鍵值與本行完整的記錄,
即:表中的資料都聚聚在葉子節點中,所以稱之為聚集索引,
非聚集索引、非聚簇索引、輔助索引、二級索引:
以非主鍵欄位值為key構成的B+ 樹,改B+ 樹的葉子節點放的是key與其主鍵對應的欄位值,
補充:一張innodb 存盤引擎中有且只能有一張聚集索引,但是可以有多個非聚集索引(輔助索引)
聚集索引負責聚集整張表的所有的資料,而輔助索引是專門提速來用
八、覆寫了索引、回表操作
覆寫了索引:在命中了索引的基礎上,只在本索引樹的葉子節點就找到了我們想要的資料,
回表操作:在命中了輔助索引的基礎上,在輔助索引的葉子節點并沒有找想要的資料,需要拿到對應的主鍵欄位值去聚集索引去找,
舉例:假設我有一張表,我們這張表是以ID欄位為基礎創建的主鍵索引,我是以name欄位創建的輔助索引
主鍵索引——》id欄位
輔助索引——》name欄位
select name, age, gender from user where name='yang';
這個命中了輔助索引,那么就順著索引樹從根節點一路找下去,找到葉子節點后,葉子節點放的是 ‘yang’ 這個人名以及它的主鍵欄位值
但是我要的是name age gender ,我要的不是id值和主鍵值,如果我要的是主鍵值和id值那么我就不需要去其他地方找了——》這就叫覆寫了索引,
因為在自己本索引樹的,本索引樹的就能找到自己想要的資料,就不需要去別的地方找
但是這并不是我想要的,那么我要拿著我 ‘yang’的主鍵欄位值假如是3,就回過頭繼續去主鍵索引樹根節點繼續找到我想要的葉子節點的資料,那里面所有資料都有——》這就叫回表操作
提問:
1、命中了輔助索引的前提下能不能覆寫了索引?
可能是!向這種情況下就是select name, id from user where name='yang'; '
這就不是select name, age, gender from user where name='yang';
2、如果命中了主鍵索引是否覆寫了索引?
一定是!·select name, age, gender from user where id=3;
所以一個SQL陳述句查詢的欄位盡量不要想寫什么就寫什么甚至是 * ,要盡量覆寫了索引,
九、索引管理
MySQL常用的索引分類
聚集索引:即主鍵索引,primary key
用途:
1.加速查找
2.約束(不為空,不能重復)
輔助索引:
唯一索引:unique
用途:
1.加速查找
2.約束(不能重復)
普通索引:index
用途:
1.加速查找
創建聚集索引
alter table 表名 add prmary key 表名(欄位名);
alter table 表名 drop primary key;——>洗掉
創建唯一索引
alter table 表名 add unique key 表名(欄位名); 沒有寫索引名 show create table 表名; 查看
alter table 表名 drop index 索引名;——>洗掉
創建普通索引
創建表時
create table 表名(
id int primary key auto_increment,
class_name varchar(10) unique,
name varchar(16),
age int
);
創建表后
create index 索引名 on 表名(欄位名);
drop index 索引名 on 表名;——>洗掉
十、聯合索引最左前綴匹配原則
create index zz on t1(id, name,age)
例如:有這樣的資料
id name age gender email
1 yang1 18 male [email protected]
2 yang2 28 female [email protected]
3 yang3 38 male [email protected]
4 yang4 48 female [email protected]
我現在對它們建聯合索引,那么我每條記錄提取的key就是 id,name,value對應的是該條記錄,列如:
1,yang1,18 ————>對應 1 yang1 18 male [email protected]
2,yang2, 28 ————>對應 2 yang2 28 female [email protected]
那么,當初只有一個欄位的時候比大小的時候很好比,那兩個欄位值怎么比大小?
1,yang1,18
2,yang2,28
注意這個和字串比大小一樣,從左到右一個一個比,第一個如果分勝負了,就沒有必要在比聯合的了第二個欄位了
在查詢條件中出現了id name,age欄位那么就肯定能命中這個聯合索引
但是必須帶著id、例如:id name、id age、id age name
最核心的原理就是每次從最左邊第一個位置開始比大小,通過最左邊就能夠縮小范圍,這就是最左前綴匹配原則,
什么時候建立聯合索引?
聯合索引就只有一棵樹,當不用聯合索引聚集索引和輔助索引就需要建三棵樹,這樣就浪費了空間,
如果要平凡的用這幾個欄位來一起查詢,就可以考慮建立聯合索引,就一棵樹,
但是注意在查詢條件中一定要帶有最左邊的欄位
總結:如果查詢條件中涉及到多個欄位值,這多個欄位值有一個同性,大家都會帶著某一個欄位,那這時候就可以鍵聯合索引,
學習之旅轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/423149.html
標籤:MySQL
上一篇:MySQL-進階知識