存盤引擎
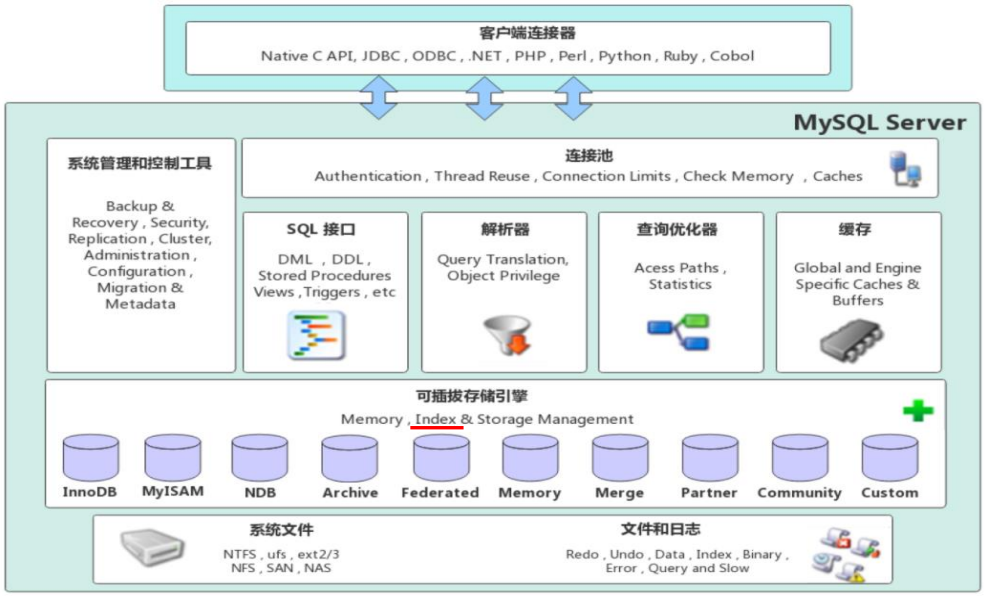
- 連接層:最上層是一些客戶端和鏈接服務,主要完成一些類似于連接處理、授權認證及相關的安全方案,服務器也會為安全接入的每個客戶端驗證它所具有的操作權限
- 服務層:第二層架構主要完成大多數的核心服務功能,如SQL介面,并完成快取的查詢,SQL的分析和優化,部分內置函式的執行,所有跨存盤引擎的功能也在這一層實作,如 程序、函式等
- 引擎層:存盤引擎真正的負責了MySQL中資料的存盤和提取,服務器通過API和存盤引擎進行通信,不同的存盤引擎具有不同的功能,這樣我們可以根據自己的需要,來選取合適的存盤引擎
- 存盤層:主要是將資料存盤在檔案系統之上,并完成與存盤引擎的互動
存盤引擎就是存盤資料、建立索引、更新/查詢資料等技術的實作方式,存盤引擎是基于表的,而不是基于庫的,所以存盤引擎也可被稱為表型別(一個資料庫中的不同表可以有不同的存盤引擎)
查看當前資料庫支持的存盤引擎: show engines;
在創建表時,指定存盤引擎
create table 表名 (
欄位名 欄位型別 [comment 欄位注釋]
) engine=innodb [comment 表注釋];
InnoDB存盤引擎
InnoDB是一種兼顧高可靠性和高性能的通用存盤引擎,在 MySQL 5.5 之后,InnoDB是默認的 MySQL 存盤引擎
- DML操作遵循ACID模型,支持事務
- 行級鎖 ,提高并發訪問性能
- 支持外鍵FOREIGN KEY約束,保證資料的完整性和正確性
InnoDB存盤引擎涉及的表檔案:
- xxx.ibd:xxx代表的是表名
- innoDB引擎的每張表都會對應這樣一個表空間檔案,存盤該表的表結構(frm:早期的表結構、sdi:MySQL8以后的表結構,而sdi檔案又融入到了ibd檔案中)、資料和索引
- 引數
innodb_file_per_table控制到底多張表共享一個表空間檔案還是每張表都對應一個表空間,默認是打開的
show variables like 'innodb_file_per_table';
MyISAM存盤引擎
MyISAM是MySQL早期的默認存盤引擎
- 不支持事務,不支持外鍵
- 支持表鎖,不支持行鎖
- 訪問速度快
MyISAM存盤引擎涉及的表檔案:
- xxx.sdi:存盤表結構資訊
- xxx.MYD: 存盤資料
- xxx.MYI: 存盤索引
Memory存盤引擎
Memory引擎的表資料時存盤在記憶體中的,由于受到硬體問題、或斷電問題的影響,只能將這些表作為臨時表或快取使用
- 記憶體存放,訪問速度快
- hash索引(默認)
Memory存盤引擎涉及的表檔案:
- xxx.sdi:存盤表結構資訊
- 資料都存放在記憶體當中,所以本地保存的只是表結構資訊
存盤引擎之間的區別
| 特點 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| 存盤限制 | 64TB | 有 | 有 |
| 事務安全 | 支持 | —— | —— |
| 鎖機制 | 行鎖 | 表鎖 | 表鎖 |
| B+tree索引 | 支持 | 支持 | 支持 |
| Hash索引 | —— | —— | 支持 |
| 全文索引 | 支持(5.6版本之后) | 支持 | —— |
| 空間使用 | 高 | 低 | N/A |
| 記憶體使用 | 高 | 低 | 中等 |
| 批量插入速度 | 低 | 高 | 高 |
| 支持外鍵 | 支持 | —— | —— |
在選擇存盤引擎時,應該根據應用系統的特點選擇合適的存盤引擎,對于復雜的應用系統,還可以根據實際情況選擇多種存盤引擎進行組合
- InnoDB:是Mysql的默認存盤引擎,支持事務、外鍵,如果應用對事務的完整性有比較高的要求,在并發條件下要求資料的一致性,資料操作除了插入和查詢之外,還包含很多的更新、洗掉操作,那么InnoDB存盤引擎是比較合適的選擇
- MyISAM:如果應用是以讀操作和插入操作為主,只有很少的更新和洗掉操作,并且對事務的完整性、并發性要求不是很高,那么選擇這個存盤引擎是非常合適的
- MEMORY:將所有資料保存在記憶體中,訪問速度快,通常用于臨時表及快取,MEMORY的缺陷就是對表的大小有限制,太大的表無法快取在記憶體中,而且無法保障資料的安全性
索引
索引(index)是幫助MySQL高效獲取資料的資料結構(有序),在資料之外,資料庫系統還維護著滿足特定查找演算法的資料結構,這些資料結構以某種方式參考(指向)資料, 這樣就可以在這些資料結構上實作高級查找演算法,這種資料結構就是索引
- 優點:提高資料檢索的效率,降低資料庫的IO成本;通過索引列對資料進行排序,降低資料排序的成本,降低CPU的消耗
- 缺點:索引列也是要占用空間的;索引大大提高了查詢效率,同時卻也降低更新表的速度,如對表進行INSERT/UPDATE/DELETE時效率降低
索引結構
MySQL的索引是在存盤引擎層面實作的,不同的存盤引擎有不同的結構,主要包含以下幾種:
| 索引結構 | 說明 |
|---|---|
| B+Tree索引 | 最常見的索引型別,大部分引擎都支持B+Tree索引 |
| Hash索引 | 底層資料結構是用哈希表實作的,只有精確匹配索引列的查詢才有效,不支持范圍查詢 |
| R-Tree(空間索引) | 空間索引是MyISM引擎的一個特殊索引型別,主要用于地理空間資料型別,通常使用較少 |
| Full-text(全文索引) | 是一種通過建立倒排索引,快速匹配檔案的方式.類似于Lucene,Solr,ES |
| 索引 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| B+Tree索引 | 支持 | 支持 | 支持 |
| Hash索引 | 不支持 | 不支持 | 支持 |
| R-Tree索引 | 不支持 | 支持 | 不支持 |
| Full-Text | 5.6版本之后支持 | 支持 | 不支持 |
索引分類
| 索引分類 | 含義 | 特點 | 關鍵字 |
|---|---|---|---|
| 主鍵索引 | 針對表中主鍵創建的索引 | 默認自動創建,只能有一個 | primary |
| 唯一索引 | 避免同一個表中某資料列中的值重復 | 可以有多個 | unique |
| 常規索引 | 快速定位特定資料 | 可以有多個 | |
| 全文索引 | 全文索引查找的是文本中的關鍵詞,而不是比較索引中的值 | 可以有多個 | fulltext |
在InnoDB存盤引擎中,根據索引的存盤形式,又可以分為以下兩種:
| 分類 | 含義 | 特點 |
|---|---|---|
| 聚集索引(Clustered Index) | 將資料存盤與索引放到了一塊,索引結構的葉子結點保存了行資料 | 必須有,而且只有一個 |
| 二級索引/輔助索引(Secondary Index) | 將資料和索引分開存盤,索引結構的葉子結點關聯的是對應的主鍵 | 可以存在多個 |
聚集索引選取規則:
- 如果存在主鍵,主鍵索引就是聚集索引
- 如果不存在主鍵,將使用第一個唯一(UNIQUE)索引作為聚集索引
- 如果表沒有主鍵,或沒有合適的唯一索引,則InnoDB會自動生成一個rowid作為隱藏的聚集索引
索引語法
一個索引可以是單列索引,也可以是聯合索引/組合索引(多列)
- index_name可以是idx_表名_欄位名
| 索引操作 | SQL語法 |
|---|---|
| 創建索引 | create [unique | fulltext] index index_name on table_name (index_col_name,…); |
| 查看索引 | show index from table_name; |
| 洗掉索引 | drop index index_name on table_name; |
SQL性能分析
查看SQL執行頻率
MySQL客戶端連接成功后,通過 show [session|global] status 命令可以提供服務器狀態資訊,通過如下指令,可以查看當前資料庫的INSERT、UPDATE、DELETE、SELECT的訪問頻次:
-- 7個下劃線
show global status like 'Com_______'
慢查詢日志
慢查詢日志記錄了所有執行時間超過指定引數(long_query_time,單位:秒,默認10秒)的所有SQL陳述句的日志
show variables like 'slow_query_log';
MySQL的慢查詢日志默認沒有開啟,需要在MySQL的組態檔(/etc/my.cnf)中配置如下資訊:
vi /etc/my.cnf
# 開啟MySQL慢查詢開關
slow_query_log=1
# 設定慢查詢的時間為2秒;SQL陳述句執行時間超過2秒,就會視為慢查詢
long_query_time=2
systemctl restart mysqld
慢查詢日志檔案存盤在 /var/lib/mysql/localhost-slow.log
profile詳情
show profiles 能夠在做SQL優化時幫助我們了解時間都耗費到哪里去了
- 首先查看當前MySQL是否支持profile功能:
select @@profiling; - 默認profiling是關閉的,可以通過set陳述句在session/global級別開啟profiling
select @@profiling;set profiling=1;
執行一系列的業務SQL的操作,然后通過如下指令查看指令的執行耗時:
-- 查看每一條SQL的耗時基本情況
show profiles;
-- 查看指定query_id的SQL陳述句各個階段的耗時情況
show profile for query query_id;
-- 查看指定query_id的SQL陳述句CPU的使用情況
show profile cpu for query query_id;
explain執行計劃
explain或者desc命令獲取MySQL如何執行select陳述句的資訊,包括在select陳述句執行程序中表如何連接和連接的順序
-- 直接在select陳述句之前加上關鍵字explain或者desc
explain select 欄位串列 from 表名 where 條件;
| explain各欄位 | 說明 |
|---|---|
| id | 表示查詢中執行select子句或者是操作表的順序(id相同,執行順序從上到下;id不同,值越大,越先執行) |
| select_type | 表示select的型別,常見的取值有simple(簡單表:不使用表連接或者子查詢);primary(主查詢:外層的查詢);union(union中的第二個或者后面的查詢陳述句);subquery(select/where之后包含了子查詢)等 |
| type | 表示連接型別,性能由好到差的連接型別為NULL、system、const、eq_ref、ref、range、 index、all(全表掃描) |
| possible_key | 顯示可能應用在這張表上的索引,一個或多個 |
| key | 實際使用的索引,如果為NULL,則沒有使用索引 |
| key_len | 表示索引中使用的位元組數,該值為索引欄位最大可能長度,并非實際使用長度,在不損失精確性的前提下,長度越短越好 |
| rows | MySQL認為必須要執行查詢的行數,在innodb引擎的表中,是一個估計值,可能并不總是準確的 |
| filtered | 表示回傳結果的行數占需讀取行數的百分比,filtered的值越大越好 |
索引使用失效場景
- 最左前綴法則:如果索引了多列(聯合索引),要遵守最左前綴法則.最左前綴法則指的是查詢從索引的最左列開始,并且不跳過索引中的列;如果跳躍某一列,索引將部分失效(后面的欄位索引失效)
- 范圍查詢:聯合索引中,出現范圍查詢(>,<),范圍查詢右側的列索引失效;所以在查詢的時候盡量使用 >= 或 <=
- 索引列運算:不要在索引列上進行運算操作,索引將失效
- 字串型別欄位使用時,不加引號,索引將失效
- 模糊查詢:如果僅僅是尾部模糊匹配,索引不會失效.如果是頭部模糊匹配,索引失效
- or連接的條件:用or分割開的條件,如果or前的條件中的列有索引,而后面的列中沒有索引,那么涉及的索引都不會被用到
- 資料分布影響:如果MySQL評估使用索引比全表更慢,則不使用索引(MySQL會自動進行選擇)
- 覆寫索引:盡量使用覆寫索引(查詢使用了索引,并且需要回傳的列,在該索引中已經全部能夠找到),減少select * ,因為這樣很容易出現回表現象
- using index condition :查找使用了索引,但是需要回表查詢資料
- using where; using index :查找使用了索引,但是需要的資料都在索引列中能找到,所以不需要回表查詢資料
SQL提示:是優化資料庫的一個重要手段,簡單來說,就是在SQL陳述句中加入一些人為的提示來達到優化操作的目的
- use index:
explain select * from tb_user use index(idx_user_pro) where profession='Java' - ignore index:
explain select * from tb_user ignore index(idx_user_pro) where profession='Java' - force index:
explain select * from tb_user force index(idx_user_pro) where profession='Java'
前綴索引:當欄位型別為字串(varchar,text等)時,有時候需要索引很長的字串,這會讓索引變得很大,查詢時,浪費大量的磁盤IO,影響查詢效率.此時可以只將字串的一部分前綴,建立索引,這樣可以大大節約索引空間,從而提高索引效率
- 語法:
create index idx_xxx on table_name(column(n)) - 前綴長度:可以根據索引的選擇性來決定,而選擇性是指不重復的索引值(基數)和資料表的記錄總數的比值,索引選擇性越高則查詢效率越高,唯一索引的選擇性是1,這是最好的索引選擇性,性能也是最好的
select count(distinct email)/count(*) from tb_user;select count(distinct substring(email,1,5)/count(*) from tb_user;
索引設計原則
- 針對于資料量較大,且查詢比較頻繁的表建立索引
- 針對于常作為查詢條件(where)、排序(order by)、分組(group by)操作的欄位建立索引
- 盡量選擇區分度高的列作為索引,盡量建立唯一索引,區分度越高,使用索引的效率越高
- 如果是字串型別的欄位,欄位的長度較長,可以針對于欄位的特點,建立前綴索引
- 盡量使用聯合索引,減少單列索引,查詢時,聯合索引很多時候可以覆寫索引,節省存盤空間,避免回表,提高查詢效率
- 要控制索引的數量,索引并不是多多益善,索引越多,維護索引結構的代價也就越大,會影響增刪改的效率
- 如果索引列不能存盤NULL值,請在創建表時使用NOT NULL約束它,當優化器知道每列是否包含NULL值時,它可以更好地確定哪個索引最有效地用于查詢
SQL優化

插入資料
- 批量插入(500-1000條資料):
insert into 表名 values(1,'Tom'),(2,'Cat'),(3,'Jerry'); - 手動提交事務(不用頻繁開關事務,所以性能高)
start transaction;
insert into 表名 values(1,'Tom'),(2,'Cat'),(3,'Jerry');
insert into 表名 values(4,'Tom'),(5,'Cat'),(6,'Jerry');
insert into 表名 values(7,'Tom'),(8,'Cat'),(9,'Jerry');
commit;
- 主鍵順序插入比主鍵亂序插入性能高
如果需要一次性插入大批量資料,使用insert陳述句插入性能較低,此時可以使用MySQL資料庫提供的load指令進行插入
- 客戶端連接服務端時,加上引數
--local-infile
mysql --local-infile -u root -p
- 設定全域引數local_infile為1,開啟從本地加載檔案匯入資料的開關
select @@local_infile;
set global local_infile=1;
- 執行load指令將準備好的資料,加載到表結構中
load data local infile '/opt/resources/load_user_100w_sort.txt' into table tb_user fields terminated by ',' lines terminated by '\n';
主鍵優化
資料組織方式:在InnoDB存盤引擎中,表資料都是根據主鍵順序組織存放的,這種存盤方式的表稱為索引組織表(index organized table IOT)
- 頁分裂:頁可以為空,也可以填充一半,也可以填充100%,每個頁包含了2-N行資料(如果一行資料多大,會行溢位),根據主鍵排列
- 頁合并:當洗掉一行記錄時,實際上記錄并沒有被物理洗掉,只是記錄被標記(flaged)為洗掉并且它的空間變得允許被其他記錄宣告使用;當頁中洗掉的記錄達到 MERGE_THRESHOLD(默認為頁的50%),InnoDB會開始尋找最靠近的頁(前或后)看看是否可以將兩個頁合并以優化空間使用
- MERGE_THRESHOLD:合并頁的閾值,可以自己設定,在創建表或者創建索引時指定
主鍵設計原則
- 滿足業務需求的情況下,盡量降低主鍵的長度
- 插入資料時,盡量選擇順序插入,選擇使用AUTO_INCREMENT自增主鍵
- 盡量不要使用UUID做主鍵或者是其他自然主鍵,如身份證號(因為亂序和主鍵長度過長)
- 業務操作時,避免對主鍵的修改
order by優化
① Using index:通過有序索引順序掃描直接回傳有序資料,這種情況即為using index,不需要額外排序,操作效率高
② Using filesort:通過表的索引或全表掃描,讀取滿足條件的資料行,然后在排序緩沖區sort buffer中完成排序操作,所有不是通過索引直接回傳排序結果的排序都叫FileSort排序
- 根據排序欄位建立合適的索引,多欄位排序時,也遵循最左前綴法則
- 盡量使用覆寫索引
- 多欄位排序,一個升序一個降序,此時需要注意聯合索引在創建時的規則(ASC/DESC)
- 如果不可避免的出現filesort,大資料量排序時,可以適當增大排序緩沖區大小 sort_buffer_size(默認256K)
-- 根據age和phone欄位進行排序:一個升序,一個降序
explain select id,age,phone from tb_user order by age asc,phone desc;
-- 根據age和phone欄位進行排序(默認都是升序)
explain select id,age,phone from tb_user order by age,phone;
-- 查看排序緩沖區大小
show variables like 'sort_buffer_size';
group by優化
- 在分組操作時,可以通過索引來提高效率
- 分組操作時,索引的使用也是滿足最左前綴法則的
limit優化
一個常見又非常頭疼的問題就是 limit 2000000,10,此時需要MySQL排序前2000010記錄,僅僅回傳2000000 - 2000010 的記錄,其他記錄丟棄,查詢排序的代價非常大
優化思路: 一般分頁查詢時,通過創建 覆寫索引 能夠比較好地提高性能,可以通過覆寫索引加子查詢形式進行優化
explain select * from tb_sku t,(select id from tb_sku order by id limit 2000000,10) a where t.id=a.id;
count優化
- MyISAM引擎把一個表的總行數存在了磁盤上,因此執行count(*)的時候會直接回傳這個數,效率很高
- InnoDB引擎就麻煩了,它執行count(*)的時候,需要把資料一行一行地從引擎里面讀出來,然后累積計數
count()是一個聚合函式,對于回傳的結果集,一行行地判斷,如果count函式的引數不是NULL,累計值就加1,否則不加,最后回傳累計值
- count(主鍵):InnoDB 引擎會遍歷整張表,把每一行的 主鍵id 值都取出來,回傳給服務層,服務層拿到主鍵后,直接按行進行累加(主鍵不可能為null)
- count(欄位):
- 沒有not null 約束 : InnoDB 引擎會遍歷整張表把每一行的欄位值都取出來,回傳給服務層,服務層判斷是否為null,不為null,計數累加
- 有not null 約束:InnoDB 引擎會遍歷整張表把每一行的欄位值都取出來,回傳給服務層,直接按行進行累加
- count(1):InnoDB 引擎遍歷整張表,但不取值,服務層對于回傳的每一行,放一個數字“1”進去,直接按行進行累加
- count(*):InnoDB引擎并不會把全部欄位取出來,而是專門做了優化,不取值,服務層直接按行進行累加
按照效率排序的話,count(欄位) < count(主鍵 id) < count(1) ≈ count(*),所以盡量使用 count(*)
update優化
InnoDB的行鎖是針對索引加的鎖,不是針對記錄加的鎖 ,并且該索引不能失效,否則會從行鎖升級為表鎖
視圖/存盤程序/觸發器
視圖
視圖(View)是一種虛擬存在的表,視圖中的資料并不在資料庫中實際存在,行和列資料來自定義視圖的查詢中使用的表,并且是在使用視圖時動態生成的
通俗的講,視圖只保存了查詢的SQL邏輯,不保存查詢結果,所以我們在創建視圖的時候,主要的作業就落在創建這條SQL查詢陳述句上
| 視圖操作分類 | 具體操作內容 | SQL語法 |
|---|---|---|
| 創建 | 創建視圖 | create [or replace] view 視圖名稱(列名串列) as select陳述句 [with [ cascaded | local ] check option] |
| 查詢 | 查看視圖結構 | show create view 視圖名稱; |
| 查看視圖資料 | select * from 視圖名稱; | |
| 修改 | 修改視圖 | create or replace view 視圖名稱(列名串列) as select陳述句 [with [ cascaded | local ] check option] |
| 修改視圖 | alter view 視圖名稱(列名串列) as select陳述句 [with [ cascaded | local ] check option] | |
| 洗掉 | 洗掉視圖 | drop view [if exists] 視圖名稱 [,視圖名稱]…; |
視圖的檢查選項:當使用WITH CHECK OPTION子句創建視圖時,MySQL會通過視圖檢查正在更改的每個行,例如 插入,更新,洗掉,以使其符合視圖的定義,MySQL允許基于另一個視圖創建視圖,它還會檢查依賴視圖中的規則以保持一致性,為了確定檢查的范圍,mysql提供了兩個選項:CASCADED 和 LOCAL ,默認值為 CASCADED
要使視圖可更新,視圖中的行與基礎表中的行之間必須存在一對一的關系,如果視圖包含以下任何一項,則該視圖不可更新:
- 聚合函式或視窗函式(SUM()、 MIN()、 MAX()、 COUNT()等)
- DISTINCT
- GROUP BY
- HAVING
- UNION 或者 UNION ALL
視圖的作用:
- 簡單:視圖不僅可以簡化用戶對資料的理解,也可以簡化他們的操作,那些被經常使用的查詢可以被定義為視圖,從而使得用戶不必為以后的操作每次指定全部的條件
- 安全:資料庫可以授權,但不能授權到資料庫特定行和特定的列上,通過視圖用戶只能查詢和修改他們所能見到的資料
- 資料獨立:視圖可幫助用戶屏蔽真實表結構變化帶來的影響
存盤程序
存盤程序是事先經過編譯并存盤在資料庫中的一段SQL陳述句的集合,呼叫存盤程序可以簡化應用開發人員的很多作業,減少資料在資料庫和應用服務器之間的傳輸,對于提高資料處理的效率是有好處的,存盤程序思想上很簡單,就是資料庫SQL語言層面的代碼封裝與重用
存盤程序特點
- 封裝,復用
- 可以接收引數,也可以回傳資料
- 減少網路互動,效率提升
-- 創建存盤程序語法
create procedure 存盤程序名稱([引數串列])
begin
-- SQL陳述句集合
end;
-- 呼叫存盤程序
call 名稱([引數串列]);
-- 查看指定資料庫的存盤程序及狀態資訊
select * from INFORMATION_SCHEMA.ROUTINES where ROUTINE_SCHEMA='xxx';
-- 查詢某個存盤程序的定義
show create procedure 存盤程序名稱;
-- 洗掉指定的存盤程序
drop procedure [if exists] 存盤程序名稱;
注意: 在命令列中,執行創建存盤程序的SQL時,需要通過關鍵字 delimiter 指定SQL陳述句的結束符
變數
系統變數是MySQL服務器提供,不是用戶定義的,屬于服務器層面,分為全域變數(GLOBAL)、會話變數(SESSION,默認);
| 操作分類 | 具體內容 | SQL語法 |
|---|---|---|
| 查看系統變數 | 查看所有系統變數 | show [ session | global ] variables; |
| 通過模糊匹配方式查找變數 | show [ session | global ] variables like '……'; | |
| 查看指定變數的值 | select @@[ session. | |
| 設定系統變數 | 設定系統變數方式一 | set [ session | global ] 系統變數名 = 值; |
| 設定系統變數方式二 | set [ session | global ] 系統變數名 := 值; | |
| 設定系統變數方式三 | set @@[ session. | global. ]系統變數名 = 值; |
注意
- 如果沒有指定SESSION/GLOBAL,默認是SESSION,會話變數
- mysql服務重新啟動之后,所設定的全域引數會失效,要想不失效,可以在 /etc/my.cnf 中配置
用戶定義變數是用戶根據需要自己定義的變數,用戶變數不用提前宣告,在用的時候直接用“@變數名”使用就可以,其作用域為當前連接
- 用戶定義的變數無需對其進行宣告或初始化,只不過獲取到的值為NUL
| 操作分類 | SQL語法 |
|---|---|
| 賦值 | set @變數名 = 變數值 [, @變數名 = 變數值]; |
| set @變數名 := 變數值 [, @變數名 := 變數值]; | |
| select @變數名 := 變數值 [, @變數名 := 變數值]; | |
| select 欄位名 into @變數名 from 表名; | |
| 使用 | select @變數名; |
區域變數是根據需要定義的在區域生效的變數,訪問之前,需要DECLARE宣告,可用作存盤程序內的區域變數和輸入引數,區域變數的范圍是在其內宣告的BEGIN ... END塊
- 變數型別就是資料庫欄位型別:INT、BIGINT、CHAR、VARCHAR、DATE、TIME等
| 操作分類 | SQL語法 |
|---|---|
| 宣告 | declare 變數名 變數型別 [default ……]; |
| 賦值 | set 變數名 = 值; |
| set 變數名 := 值; | |
| select 欄位名 into 變數名 from 表名; |
| 形參型別 | 說明 |
|---|---|
| in | 默認值;該類引數作為輸入,也就是需要呼叫時傳入值 |
| out | 該類引數作為輸出,也就是該引數可以作為回傳值 |
| inout | 既可以作為輸入引數,也可以作為輸出引數 |
流程控制語法
\[存盤程序流程控制陳述句 \begin{cases} \text{if-elseif-else 條件控制陳述句}\\ \text{case-when 條件控制陳述句}\\ \text{while 回圈控制陳述句}\\ \text{repeat 回圈控制陳述句}\\ \text{loop 回圈控制陳述句} \end{cases} \]if 條件1 then
……
elseif 條件2 then
……
else
……
end if;
if-elseif-else代碼案例
-- 案例一
create procedure p1(in score int, out result varchar(10))
begin
if score >= 85 then
set result := '優秀';
elseif score >= 60 then
set result := '及格';
else
set result := '不及格';
end if;
end;
call p1(98, @result);
select @result;
-- 案例二:將傳入的200分制的分數,進行換算,換算成百分比,然后回傳分數
create procedure p2(inout score double)
begin
set score := score * 0.5;
end;
set @score = 70;
call p2(@score);
select @score;
case case_value
when when_value1 then statement_list1
[when when_value2 then statement_list2]
[else statement_list]
end case;
-- 語法二
case
when search_condition1 then statement_list1
[when search_condition2 then statement_list2]
[else statement_list]
end case;
case-when代碼案例
-- 根據傳入的月份,判定月份所屬的季節
create procedure p3(in month int)
begin
declare result varchar(10);
case
when month >= 1 and month <= 3 then
set result := '第一季度';
when month >= 4 and month <= 6 then
set result := '第二季度';
when month >= 7 and month <= 9 then
set result := '第三季度';
when month >= 10 and month <= 12 then
set result := '第四季度';
else
set result := '非法引數';
end case;
select concat('您輸入的月份為:', month, ',所屬的季度為:', result);
end;
call p3(7);
-- while 回圈是有條件的回圈控制陳述句,滿足條件后,再執行回圈體中的SQL陳述句,具體語法為:
while 條件 do
SQL邏輯
end while;
while代碼案例
-- 計算從1累加到n的值,n為傳入的引數值
create procedure p4(in n int)
begin
declare total int default 0;
while n > 0
do
set total := total + n;
set n := n - 1;
end while;
select total;
end;
call p5(100);
-- repeat是有條件的回圈控制陳述句,當滿足條件的時候退出回圈
-- 先執行一次邏輯,然后判斷邏輯是否滿足;如果滿足,則退出;如果不滿足,則繼續下一次回圈
repeat
SQL邏輯
until 條件
end repeat;
repeat代碼案例
-- 計算從1累加到n的值,n為傳入的引數值
create procedure p5(in n int)
begin
declare total int default 0;
repeat
set total := total + n;
set n := n - 1;
until n <= 0
end repeat;
select total;
end;
call p5(100);
Loop實作簡單的回圈,如果不在SQL邏輯中增加退出回圈的條件,可以用來實作簡單的死回圈.Loop可以配合以下兩個陳述句使用:
- leave:配合回圈使用,退出回圈(類似于break)
- iterate:跳過當前回圈剩下的陳述句,直接進入下一次回圈(類似于continue)
[begin_label:] loop
SQL邏輯
end loop [end_label];
leave lable; -- 退出指定標記的回圈體
iterate label; -- 直接進入下一次回圈
loop代碼案例
-- 計算從1累加到n的值,n為傳入的引數值
create procedure p6(in n int)
begin
declare total int default 0;
sum:loop
if n <= 0 then
leave sum;
end if;
set total := total + n;
set n := n - 1;
end loop sum;
select total;
end;
call p6(100);
-- 計算從1到n之間的偶數累加的值,n為傳入的引數值
create procedure p7(in n int)
begin
declare total int default 0;
sum:
loop
if n <= 0 then
leave sum;
end if;
if n % 2 = 1 then
set n := n - 1;
iterate sum;
end if;
set total := total + n;
set n := n - 1;
end loop sum;
select total;
end;
call p7(100);
游標
游標(CURSOR)是用來存盤查詢結果集的資料型別 , 在存盤程序和函式中可以使用游標對結果集進行回圈的處理,游標的使用包括游標的宣告、OPEN、FETCH 和 CLOSE,其語法分別如下
| 操作分類 | 說明 |
|---|---|
| 宣告游標 | declare 游標名稱 cursor for 查詢陳述句; |
| 打開游標 | open 游標名稱; |
| 獲取游標記錄 | fetch 游標名稱 into 變數[,變數]; |
| 關閉游標 | close 游標名稱; |
游標使用邏輯流程:
- 宣告游標,存盤查詢結果即
- 準備:創建表結構
- 開啟游標
- 獲取游標中的記錄
- 插入資料到新表中
- 關閉游標
條件處理程式(Handler)可以用來定義在流程控制結構執行程序中遇到問題時相應的處理步驟,具體語法為:
declare handler_action handler for condition_value [,condition_value] statement;
handler_action
- continue:繼續執行當前程式
- exit:終止執行當前程式
condition_vlaue
- SQLSTATE sqlstate_value:狀態碼,如 02000
- SQLWARNING:所有以01開頭的SQLSTATE代碼的簡寫
- NOT FOUND:所有以02開頭的SQLSTATE代碼的簡寫
- SQLEXCEPTION:所有沒有被SQLWARNING 或 NOT FOUND捕獲的SQLSTATE代碼的簡寫
MySQL錯誤狀態碼
游標:存盤資料集相關代碼案例
-- 根據傳入的引數uage,來查詢用戶表tb_user中,所有用戶年齡小于等于uage的用戶姓名name和專業profession
-- 并將用戶的姓名和專業插入到新創建的表中(id,name,profession)中
create procedure p8(in uage int)
begin
declare uname varchar(100);
declare upro varchar(100);
declare u_cursor cursor for select name, profession from tb_user where age <= uage;
declare exit handler for SQLSTATE '02000' close u_cursor;
-- declare exit handler for not found close u_cursor;
drop table if exists tb_user_pro;
create table tb_user_pro(
id int primary key auto_increment,
name varchar(100),
profession varchar(100)
);
open u_cursor;
while true
do
fetch u_cursor into uname,upro;
insert into tb_user_pro vlaues(null, uname, upro);
end while;
close u_cursor;
end;
call p8(30);
存盤函式
存盤函式是有回傳值的存盤程序,存盤函式的引數只能是IN型別的,具體語法如下:
create function 存盤函式名稱([引數串列])
returns type [characteristic]
begin
SQL陳述句
return ...;
end;
characteristic說明
- deterministic:相同的輸入引數總是產生相同的結果
- no sql:不包含SQL陳述句
- reads sql data:包含讀取資料的陳述句,但不包含寫入資料的陳述句
存盤函式代碼案例:從1到n的累加
create function fun1(n int)
returns int deterministic
begin
declare total int default 0;
while n > 0
do
set total := total + n;
set n := n - 1;
end while;
return total;
end;
select fun1(100);
觸發器
觸發器是與表有關的資料庫物件,指在 insert/update/delete 之前或之后,觸發并執行觸發器中定義的SQL陳述句集合,觸發器的這種特性可以協助應用在資料庫端確保資料的完整性, 日志記錄, 資料校驗等操作
使用別名 OLD 和 NEW 來參考觸發器中發生變化的記錄內容,這與其他的資料庫是相似的,現在觸發器還只支持行級觸發,不支持陳述句級觸發
| 觸發器型別 | new和old |
|---|---|
| insert型觸發器 | new表示將要或者已經新增的資料 |
| update型觸發器 | old表示修改之前的資料,new表示將要或已經修改后的資料 |
| delete型觸發器 | old表示將要或者已經洗掉的資料 |
-- 創建觸發器
create trigger trigger_name
before/after insert/update/delete
on tbl_name for each row -- 行級觸發器
begin
trigger_stmt;
end;
-- 查看所有的觸發器
show triggers;
-- 洗掉觸發器
drop trigger [schema_name.]trigger_name; -- 如果沒有指定schema_name,默認為當前資料庫
觸發器代碼案例
create trigger tb_user_insert_trigger
after insert
on tb_user
for each row
begin
insert into user_logs(id, operation, operate_name, operate_id, operate_params)
values (null, 'insert', now(), new.id, concat('插入的資料內容為:id=', new.id, ',name=', new.name, 'phone=', new.phone));
end;
鎖
鎖是計算機協調多個行程或執行緒并發訪問某一資源的機制,在資料庫中,除傳統的計算資源(CPU、RAM、I/O)的爭用以外,資料也是一種供許多用戶共享的資源,如何保證資料并發訪問的一致性、有效性是所有資料庫必須解決的一個問題,鎖沖突也是影響資料庫并發訪問性能的一個重要因素,從這個角度來說,鎖對資料庫而言顯得尤其重要,也更加復雜
MySQL中的鎖,按照鎖的粒度分,分為以下三類:
- 全域鎖:鎖定資料庫中的所有表,
- 表級鎖:每次操作鎖住整張表,
- 行級鎖:每次操作鎖住對應的行資料
全域鎖
全域鎖就是對整個資料庫實體加鎖,加鎖后整個實體就處于只讀狀態,后續的DML的寫陳述句,DDL陳述句,已經更新操作的事務提交陳述句都將被阻塞
其典型的使用場景是做全庫的邏輯備份,對所有的表進行鎖定,從而獲取一致性視圖,保證資料的完整性
資料庫中加全域鎖,是一個比較重的操作,存在以下問題:
- 如果在主庫上備份,那么在備份期間都不能執行更新,業務基本上就得停擺,
- 如果在從庫上備份,那么在備份期間從庫不能執行主庫同步過來的二進制日志(binlog),會導致主從延遲
-- 加鎖
flush tables with read lock;
-- 釋放鎖
unlock tables;
-- 在cmd中輸入備份命令
mysqldump -uroot -p123456 資料庫名 > 資料庫備份名.sql
在InnoDB引擎中,我們可以在備份時加上引數 --single-transaction 引數來完成不加鎖的一致性資料備份
mysqldump --single-transaction -uroot -p123456 資料庫名 > 資料庫備份名.sql
表級鎖
表級鎖,每次操作鎖住整張表,鎖定粒度大,發生鎖沖突的概率最高,并發度最低,應用在MyISAM、InnoDB、BDB等存盤引擎中
\[表級鎖分類 \begin{cases} \text{表鎖} \begin{cases} \text{表共享讀鎖(read lock)}\\ \text{表獨占寫鎖(write lock)} \end{cases} \\ \text{元資料鎖(meta data lock,MDL)} \\ \text{意向鎖} \\ \end{cases} \]表鎖語法
- 加鎖:lock tables 表名... read/write
- 釋放鎖:unlock tables 或者 客戶端斷開連接
讀鎖不會阻塞其他客戶端的讀,但是會阻塞寫,寫鎖既會阻塞其他客戶端的讀,又會阻塞其他客戶端的寫
元資料鎖
MDL加鎖程序是系統自動控制,無需顯式使用,在訪問一張表的時候會自動加上,MDL鎖主要作用是維護表元資料的資料一致性,在表上有活動事務的時候,不可以對元資料進行寫入操作
在MySQL5.5中引入了MDL,當對一張表進行增刪改查的時候,加MDL讀鎖(共享);當對表結構進行變更操作的時候,加MDL寫鎖(排他)
| 對應SQL | 鎖型別 | 說明 |
|---|---|---|
| lock tables XXX read/write | shared_read_only 或 shared_no_read_write | |
| select 、select ... lock in share mode | shared_read | 與shared_read、shared_write兼容,與exclusive互斥 |
| insert、update、delete、select ... for update | shared_write | 與shared_read、shared_write兼容,與exclusive互斥 |
| alter table ... | exclusive | 與其他的MDL都互斥 |
查看元資料鎖
select object_type,object_schema,object_name,lock_type,lock_duration from performance_schema.metadata_locks;
意向鎖:為了避免DML在執行時,加的行鎖與表鎖的沖突,在InnoDB中引入了意向鎖,使得表鎖不用檢查每行資料是否加鎖,使用意向鎖來減少表鎖的檢查
- 意向共享鎖(IS):由陳述句 select ... lock in share mode添加
- 意向排他鎖(IX):由insert、update、delete、select ... for update 添加
查看意向鎖及行鎖的加鎖情況:
select object_schema,object_name,index_name,lock_type,lock_mode,lock_data from performance_schema.data_locks;
行級鎖
行級鎖,每次操作鎖住對應的行資料,鎖定粒度最小,發生鎖沖突的概率最低,并發度最高,應用在InnoDB存盤引擎中
InnoDB的資料是基于索引組織的,行鎖是通過對索引上的索引項加鎖來實作的,而不是對記錄加的鎖,對于行級鎖,主要分為以下三類:
- 行鎖(Record Lock):鎖定單個行記錄的鎖,防止其他事務對此行進行update和delete,在RC、RR隔離級別下都支持
- 間隙鎖(Gap Lock):鎖定索引記錄間隙(不含該記錄),確保索引記錄間隙不變,防止其他事務在這個間隙進行insert,產生幻讀,在RR隔離級別下都支持
- 臨鍵鎖(Next-Key Lock):行鎖和間隙鎖組合,同時鎖住資料,并鎖住資料前面的間隙Gap,在RR隔離級別下支持
InnoDB實作了以下兩種型別的行鎖:
- 共享鎖(S):允許一個事務去讀一行,阻止其他事務獲得相同資料集的排它鎖,
- 排他鎖(X):允許獲取排他鎖的事務更新資料,阻止其他事務獲得相同資料集的共享鎖和排他鎖
| 當前鎖型別/請求鎖型別 | S(共享鎖) | X(排它鎖) |
|---|---|---|
| S(共享鎖) | 兼容 | 沖突 |
| X(排它鎖) | 沖突 | 沖突 |
| SQL | 行鎖型別 | 說明 |
|---|---|---|
| INSERT ... | 排他鎖 | 自動加鎖 |
| UPDATE ... | 排他鎖 | 自動加鎖 |
| DELETE ... | 排他鎖 | 自動加鎖 |
| SELECT(正常) | 不加任何鎖 | |
| SELECT ... LOCK IN SHARE MODE | 共享鎖 | 需要手動在SELECT之后加LOCK IN SHARE MODE |
| SELECT ... FOR UPDATE | 排他鎖 | 需要手動在SELECT之后加FOR UPDATE |
默認情況下,InnoDB在 REPEATABLE READ事務隔離級別運行,InnoDB使用 next-key 鎖進行搜索和索引掃描,以防止幻讀,
- 針對唯一索引進行檢索時,對已存在的記錄進行等值匹配時,將會自動優化為行鎖,
- InnoDB的行鎖是針對于索引加的鎖,不通過索引條件檢索資料,那么InnoDB將對表中的所有記錄加鎖,此時 就會升級為表鎖
查看意向鎖及行鎖的加鎖情況:
select object_schema,object_name,index_name,lock_type,lock_mode,lock_data from performance_schema.data_locks;
默認情況下,InnoDB在 REPEATABLE READ事務隔離級別運行,InnoDB使用 next-key 鎖進行搜索和索引掃描,以防止幻讀
- 索引上的等值查詢(唯一索引),給不存在的記錄加鎖時, 優化為間隙鎖
- 索引上的等值查詢(普通索引),向右遍歷時最后一個值不滿足查詢需求時,next-key lock 退化為間隙鎖
- 索引上的范圍查詢(唯一索引)--會訪問到不滿足條件的第一個值為止
注意:間隙鎖唯一目的是防止其他事務插入間隙,間隙鎖可以共存,一個事務采用的間隙鎖不會阻止另一個事務在同一間隙上采用間隙鎖
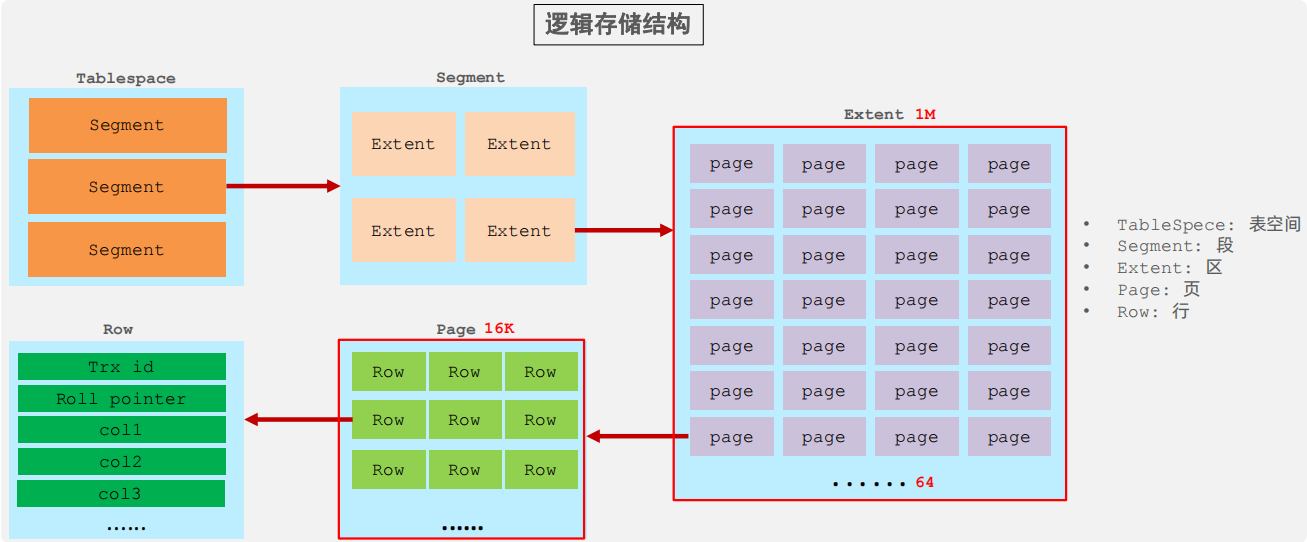
InnoDB存盤引擎
- 表空間(ibd檔案):一個mysql實體可以對應多個表空間,用于存盤記錄、索引等資料
- 段:分為資料段(Leaf node segment)、索引段(Non-leaf node segment)、回滾段(Rollback segment),InnoDB是索引組織表,資料段就是B+樹的葉子節點,索引段即為B+樹的非葉子節點,段用來管理多個Extent(區)
- 區:表空間的單元結構,每個區的大小為1M,默認情況下,InnoDB存盤引擎頁大小為16K,即一個區中一共有64個連續的頁
- 頁:是InnoDB存盤引擎磁盤管理的最小單元,每個頁的大小默認為 16KB,為了保證頁的連續性,InnoDB存盤引擎每次從磁盤申請4-5個區
- 行:InnoDB 存盤引擎資料是按行進行存放的
- Trx_id:每次對某條記錄進行改動時,都會把對應的事務id賦值給trx_id隱藏列
- Roll_pointer:每次對某條引記錄進行改動時,都會把舊的版本寫入到undo日志中,然后這個隱藏列就相當于一個指標,可以通過它來找到該記錄修改前的資訊
架構原理
MySQL5.5版本開始,默認使用InnoDB存盤引擎,它擅長事務處理,具有崩潰恢復特性,在日常開發中使用非常廣泛,下面是InnoDB架構圖,左側為記憶體結構,右側為磁盤結構
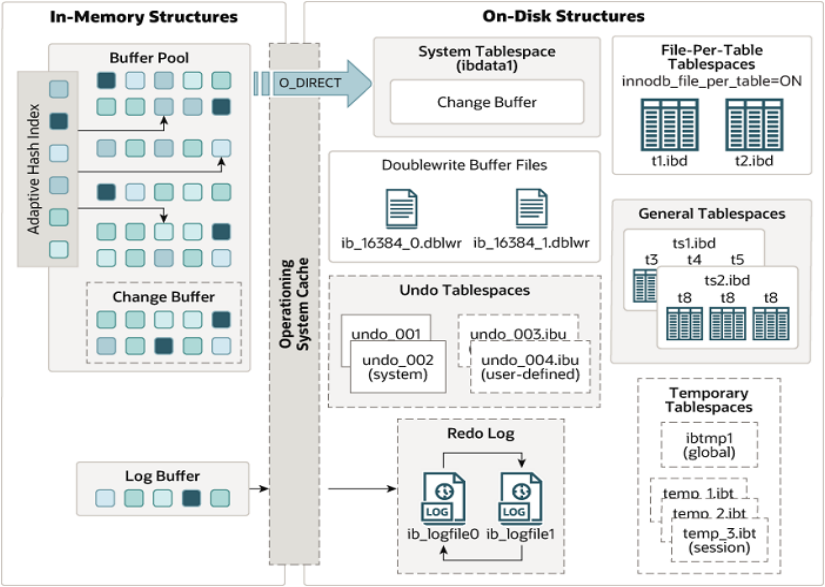
記憶體架構
- Buffer Pool:緩沖池是主記憶體中的一個區域,里面可以快取磁盤上經常操作的真實資料,在執行增刪改查操作時,先操作緩沖池中的資料(若緩沖池沒有資料,則從磁盤加載并快取),然后再以一定頻率重繪到磁盤,從而減少磁盤IO,加快處理速度.緩沖池以Page頁為單位,底層采用鏈表資料結構管理Page,根據狀態,將Page分為三種型別:
- free page:空閑page,未被使用,
- clean page:被使用page,資料沒有被修改過,
- dirty page:臟頁,被使用page,資料被修改過,也中資料與磁盤的資料產生了不一致
- Change Buffer:更改緩沖區(針對于非唯一二級索引頁),在執行DML陳述句時,如果這些資料Page沒有在Buffer Pool中,不會直接操作磁盤,而會將資料變更存在更改緩沖區 Change Buffer 中,在未來資料被讀取時,再將資料合并恢復到Buffer Pool中,再將合并后的資料重繪到磁盤中
- 與聚集索引不同,二級索引通常是非唯一的,并且以相對隨機的順序插入二級索引,同樣,洗掉和更新可能會影響索引樹中不相鄰的二級索引頁,如果每一次都操作磁盤,會造成大量的磁盤IO,有了
ChangeBuffer之后,我們可以在緩沖池中進行合并處理,減少磁盤IO,
- 與聚集索引不同,二級索引通常是非唯一的,并且以相對隨機的順序插入二級索引,同樣,洗掉和更新可能會影響索引樹中不相鄰的二級索引頁,如果每一次都操作磁盤,會造成大量的磁盤IO,有了
- Adaptive Hash Index:自適應hash索引,用于優化對Buffer Pool資料的查詢,InnoDB存盤引擎會監控對表上各索引頁的查詢,如果觀察到hash索引可以提升速度,則建立hash索引,稱之為自適應hash索引,自適應哈希索引,無需人工干預,是系統根據情況自動完成
- 引數: adaptive_hash_index
- Log Buffer:日志緩沖區,用來保存要寫入到磁盤中的log日志資料(redo log 、undo log),默認大小為 16MB,日志緩沖區的日志會定期重繪到磁盤中,如果需要更新、插入或洗掉許多行的事務,增加日志緩沖區的大小可以節省磁盤 I/O
- 引數 innodb_log_buffer_size:緩沖區大小
- 引數 innodb_flush_log_at_trx_commit:日志重繪到磁盤時機
- 1: 日志在每次事務提交時寫入并重繪到磁盤(默認)
- 0:每秒將日志寫入并重繪到磁盤一次
- 2:日志在每次事務提交后寫入,并每秒重繪到磁盤一次
磁盤結構
- System Tablespace:系統表空間是更改緩沖區的存盤區域,如果表是在系統表空間而不是每個表檔案或通用表空間中創建的,它也可能包含表和索引資料,(在MySQL5.x版本中還包含InnoDB數
據字典、undolog等)- 引數:innodb_data_file_path
- File-Per-Table Tablespaces:每個表的檔案表空間包含單個InnoDB表的資料和索引 ,并存盤在檔案系統上的單個資料檔案中
- 引數:innodb_file_per_table
- General Tablespaces:通用表空間,需要通過 CREATE TABLESPACE 語法創建通用表空間,在創建表時,可以指定該表空間
- 創建表空間:
create tablespace xxx add datafile 'file_name' engine=engine_name; - 創建表的同時指定表空間:
create table xxx ... tablespace ts_name;
- 創建表空間:
- Undo Tablespaces:撤銷表空間,MySQL實體在初始化時會自動創建兩個默認的undo表空間(初始大小16M),用于存盤undo log日志
- Temporary Tablespaces:InnoDB 使用會話臨時表空間和全域臨時表空間,存盤用戶創建的臨時表等資料
- Doublewrite Buffer Files:雙寫緩沖區,innoDB引擎將資料頁從Buffer Pool重繪到磁盤前,先將資料頁寫入雙寫緩沖區檔案中,便于系統例外時恢復資料
- Redo Log:重做日志,是用來實作事務的持久性,該日志檔案由兩部分組成:重做日志緩沖(redo log buffer)以及重做日志檔案(redo log),前者是在記憶體中,后者在磁盤中,當事務提
交之后會把所有修改資訊都會存到該日志中, 用于在重繪臟頁到磁盤時,發生錯誤時, 進行資料恢復使用,以回圈方式寫入重做日志檔案,涉及兩個檔案:ib_logfile0和ib_logfile1
后臺執行緒
- Master Thread:核心后臺執行緒,負責調度其他執行緒,還負責將緩沖池中的資料異步重繪到磁盤中, 保持資料的一致性,還包括臟頁的重繪、合并插入快取、undo頁的回收
- IO Thread:在InnoDB存盤引擎中大量使用了AIO來處理IO請求, 這樣可以極大地提高資料庫的性能,而IO Thread主要負責這些IO請求的回呼
- Purge Thread:主要用于回收事務已經提交了的undo log,在事務提交之后,undo log可能不用了,就用它來回收
- Page Cleaner Thread:協助 Master Thread 重繪臟頁到磁盤的執行緒,它可以減輕 Master Thread 的作業壓力,減少阻塞
| IO執行緒型別 | 默認個數 | 職責 |
|---|---|---|
| Read thread | 4 | 負責讀操作 |
| Write thread | 4 | 負責寫操作 |
| Log thread | 1 | 負責將日志緩沖區重繪到磁盤 |
| Insert buffer thread | 1 | 負責將寫緩沖區內容重繪到磁盤 |
事務原理
-
redo log解決事務的持久性
- 重做日志,記錄的是事務提交時資料頁的物理修改,是用來實作事務的持久性
- 該日志檔案由兩部分組成:重做日志緩沖(redo log buffer)以及重做日志檔案(redo log file),前者是在記憶體中,后者在磁盤中,當事務
- 提交之后會把所有修改資訊都存到該日志檔案中, 用于在重繪臟頁到磁盤,發生錯誤時, 進行資料恢復使用
-
undo log解決事務的原子性:回滾日志,用于記錄資料被修改前的資訊,作用包含兩個:提供回滾和MVCC(多版本并發控制)
- undo log和redo log記錄物理日志不一樣,它是邏輯日志,可以認為當delete一條記錄時,undo log中會記錄一條對應的insert記錄,反之亦然,當update一條記錄時,它記錄一條對應相反的update記錄,當執行rollback時,就可以從undo log中的邏輯記錄讀取到相應的內容并進行回滾
- Undo log銷毀:undo log在事務執行時產生,事務提交時,并不會立即洗掉undo log,因為這些日志可能還用于MVCC
- Undo log存盤:undo log采用段的方式進行管理和記錄,存放在前面介紹的 rollback segment 回滾段中,內部包含1024個undo log segment
MySQL管理
MySQL資料庫安裝完成后,自帶了四個資料庫,具體作用如下:
| 資料庫 | 含義 |
|---|---|
| mysql | 存盤MySQL服務器正常運行所需要的各種資訊(時區/主從/用戶/權限等) |
| information_schema | 提供了訪問資料庫元資料的各種表和視圖,包含資料庫、表、欄位型別及訪問權限等 |
| performance_schema | 為MySQL服務器運行時狀態提供了一個底層監控功能,主要用于收集資料庫服務器性能引數 |
| sys | 包含了一系列方便DBA和開發人員利用performance_schema性能資料庫進行性能調優和診斷的視圖 |
mysql:該mysql不是指mysql服務,而是指mysql的客戶端工具

-e選項可以在Mysql客戶端執行SQL陳述句,而不用連接到MySQL資料庫再執行,對于一些批處理腳本,這種方式尤其方便
mysql -h192.168.2.128 -P3306 -p123456 資料庫名 -e "select * from stu"
mysqladmin:mysqladmin 是一個執行管理操作的客戶端程式,可以用它來檢查服務器的配置和當前狀態、創建并洗掉資料庫等
mysqladmin --help
mysqladmin -uroot -p123456 drop 'test01';
mysqladmin -uroot -p123456 version;
mysqlbinlog:由于服務器生成的二進制日志檔案以二進制格式保存,所以如果想要檢查這些文本的文本格式,就會使用到mysqlbinlog日志管理工具

mysqlshow:mysqlshow 客戶端物件查找工具,用來很快地查找存在哪些資料庫、資料庫中的表、表中的列或者索引

mysqldump:mysqldump 客戶端工具用來備份資料庫或在不同資料庫之間進行資料遷移,備份內容包含創建表,及插入表的SQL陳述句

mysqlimport/source:mysqlimport 是客戶端資料匯入工具,用來匯入mysqldump 加 -T 引數后匯出的文本檔案

如果需要匯入sql檔案,可以使用mysql中的source 指令
source /root/xxx.sql
本文來自博客園,作者:不二橘子醬,轉載請注明原文鏈接:https://www.cnblogs.com/marmaladeHY/p/15824667.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/423153.html
標籤:其他
上一篇:MongoDB學習筆記:JavaScript shell
下一篇:MySQL資料庫索引介紹