前面我們了解了SQL查詢陳述句是如何執行的,一條SQL查詢陳述句的程序需要經過連接器、分析器、優化器、執行器等功能模塊,最終到達存盤引擎,
在MySQL中,可以恢復到半個月內的任何一個時間點,這時基于日志系統來實作的,
更新陳述句的流程
在這個例子中,假設創建了表T,
create table T(ID int primary key, c int)
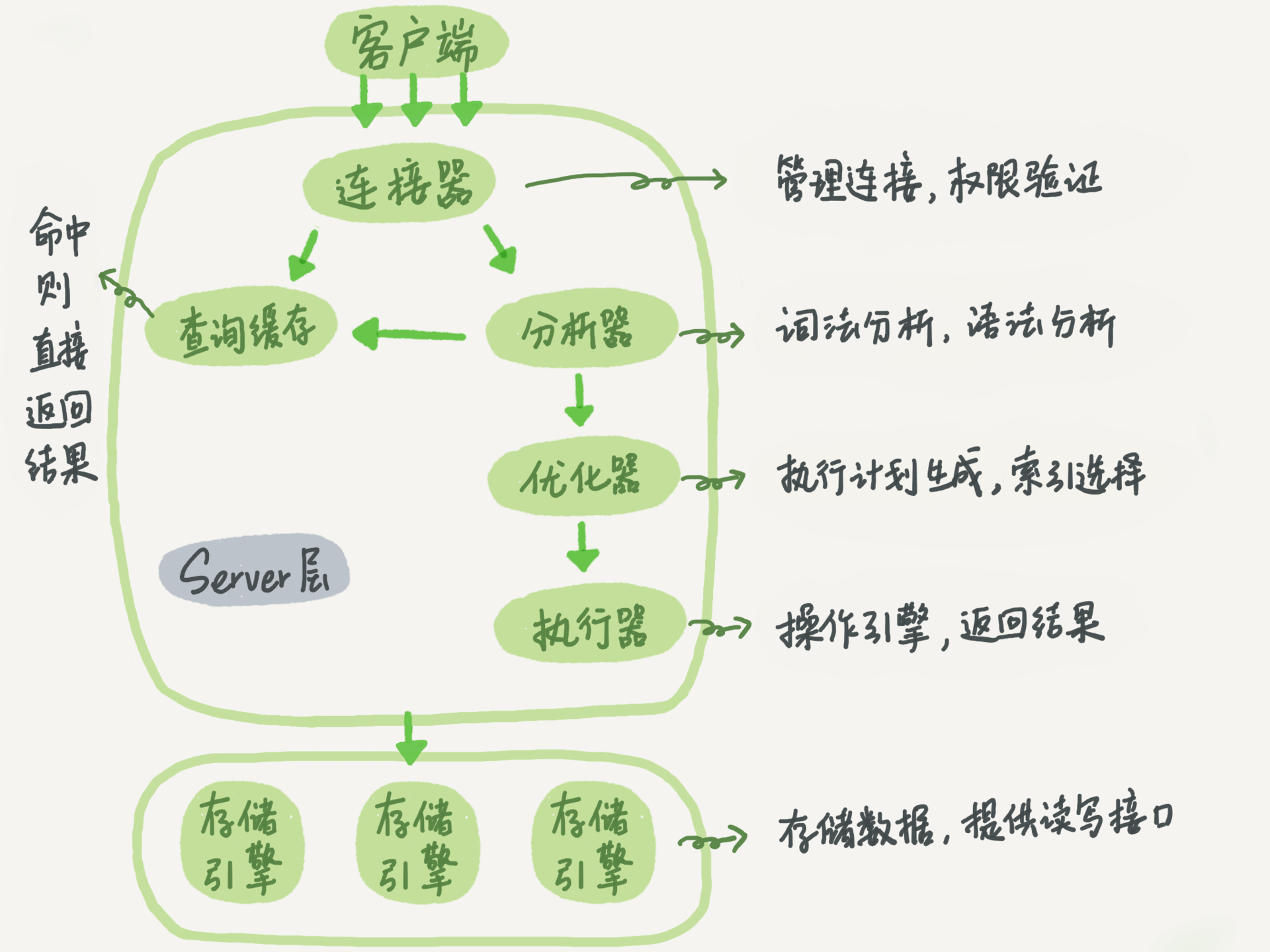
前面提到了查詢陳述句的流程如上所示,首先可以確定的是,更新陳述句的流程也和查詢陳述句的流程一樣,
再假如我們在表T中執行更新陳述句如下:
update T set c = c + 1 where ID = 2;
執行任何陳述句前都需要連接上MySQL,這就是連接器的作業,
接下來,因為我們執行的是更新操作,所以查詢快取就需要重繪以確保快取中資料的正確性,因此需要將表T中的查詢快取都清空,這也是之前不推薦使用查詢快取的原因,
接下來,分析器會通過詞法和語法決議知道這是一條更新陳述句,
優化器決定來使用ID這個索引,
然后,執行器負責具體執行,找到對應的資料行,然后執行更新,
與查詢流程不一樣的是,更新流程還涉及兩個重要的日志模塊\(redo\ log\)(重做日志)和\(bin\ log\)(歸檔日志),
redo log
在MySQL中,如果每一次的更新都需要重新寫入磁盤,然后從磁盤中找到那條記錄,然后再執行更新,整個程序的I/O成本、查找成本都很高,為了解決這個問題,MySQL使用了WAL技術,全稱為\(Write-Ahead-Logging\),關鍵點在于先寫日志,再寫磁盤,
具體的做法是,當有記錄需要更新時,InnoDB引擎會先把記錄寫到\(redo\ log\)中,這時更新就算是完成了,同時,InnoDB引擎會在適當的時候,將這次操作更新到磁盤中,這個更新往往是在系統比較空閑的時候執行的,
再繼續聯想,如果更新的記錄不多,系統可以等待空閑時再執行真正的更新,如果更新的記錄比較多,就只好先暫停下系統,將更新寫入磁盤,再把這些記錄從日志中移去,為新的更新提供空間,
InnoDB的\(redo\ log\)大小是固定的,比如可以配置一組4個檔案,每個檔案的大小是1GB,那么整個日志的大小就是4GB,
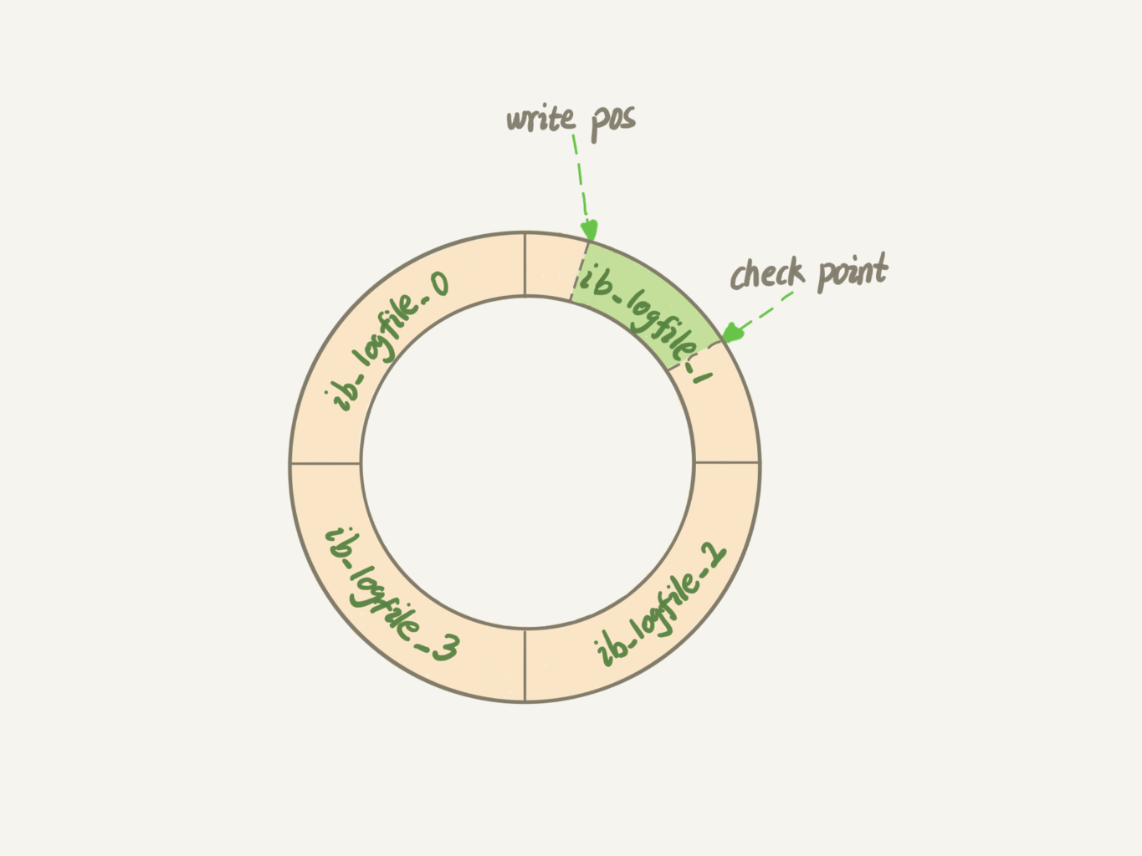
如上所示,從頭開始寫,寫到末尾又從頭開始寫,
\(write\ pos\)是當前記錄的位置,一邊寫一邊后移,寫到第3號檔案末尾就又從第0號檔案開頭開始寫,
\(checkpoint\)是當前要擦除的位置,也是往后推移并且回圈的,
\(write\ pos\)和\(checkpoint\)之間的空間是空著的部分,用來記錄新的操作,
當\(write\ pos\)追上\(checkpoint\)后,表示\(redo\ log\)滿了,這時候不能執行新的更新,必須先把操作寫入磁盤后,才能繼續更新,需要把\(checkpoint\)往后推移一些距離,
有了\(redo\ log\),InnoDB就可以保證即使資料庫發生了例外重啟,之前提交的記錄不會丟失,這個能力成為\(crash-safe\),
bin log
前面的\(redo\ log\)更多的是資料引擎層面的日志,在Server層也有\(bin\ log\)日志,
因為最初時MySQL并沒有InnoDB引擎,自帶的引擎是MyISAM,MyISAM并不具備\(crash-safe\)能力,\(bin\ log\)日志用于歸檔,
這兩種日志有以下三點不同,
- \(redo\ log\) 是 InnoDB 引擎特有的;\(bin\ log\) 是 MySQL 的 Server 層實作的,所有引擎都可以使用,
- \(redo\ log\) 是物理日志,記錄的是“在某個資料頁上做了什么修改”;\(bin\ log\) 是邏輯日志,記錄的是這個陳述句的原始邏輯,比如“給 ID=2 這一行的 c 欄位加 1 ”,
- \(redo\ log\) 是回圈寫的,空間固定會用完;\(bin\ log\) 是可以追加寫入的,“追加寫”是指 \(bin\ log\) 檔案寫到一定大小后會切換到下一個,并不會覆寫以前的日志,
案例分析
在上面提到的例子中,update陳述句的流程如下:
- 執行器先找引擎取ID=2這一行,ID是主鍵,引擎直接到主鍵索引樹上搜索找到這一行,如果ID=2這一行所在的資料頁本來就在記憶體中,就直接回傳給執行器,否則,需要先從磁盤中讀入記憶體,然后再回傳,
- 執行器拿到引擎給的行資料,把這個值加上1,比如原來是N,現在將其修改為N+1,得到新的一行資料,再呼叫引擎介面寫入這行新資料;
- 引擎把這行新資料更新到記憶體中,同時將這個更新操作記錄到\(redo\ log\)中,此時\(redo\ log\)處于prepare狀態,然后告知執行器執行完成,可以提交事務;
- 執行器生產這個操作的\(bin\ log\),并把\(bin\ log\)寫入磁盤;
- 執行器呼叫引擎的提交事務介面,引擎把剛剛寫入的\(redo\ log\)改成commit狀態,表示事務已提交,更新完成,
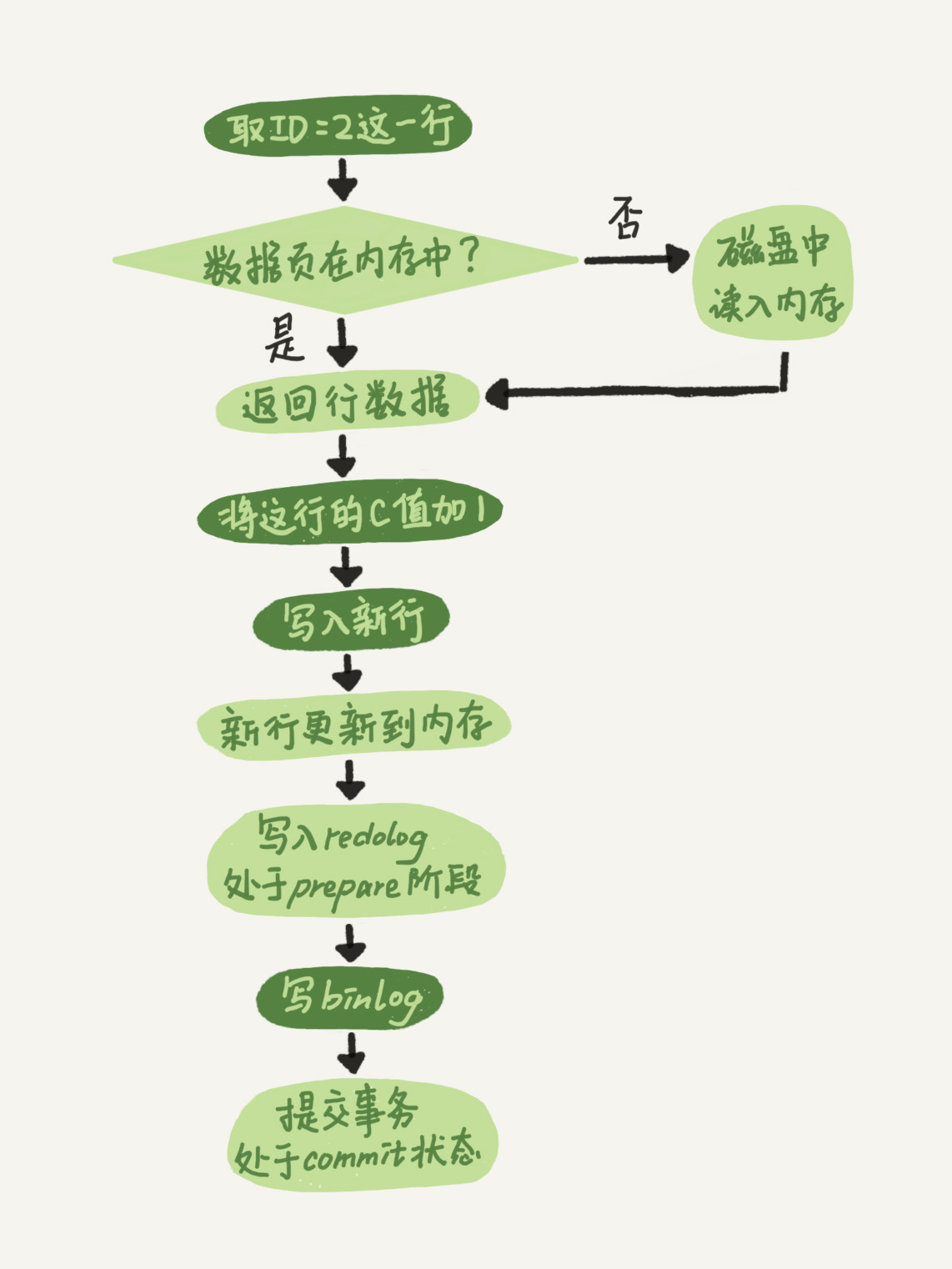
上圖中深色部分表示在執行器中執行,淺色部分表示在引擎中執行,
將\(redo\ log\)的寫入拆分為兩個步驟:prepared和commit也成為兩階段提交,
兩階段提交
兩階段提交這是為了讓兩份日志之間的邏輯一致,
我們先查看一下如何使用兩份日志來做資料恢復,
\(bin\ log\)會記錄下所有的邏輯操作,并且是追加寫方式,因此當我們對某個時間的系統進行備份后,如果在某天下午2點發現12點有一次誤刪操作,需要找回資料,我們可以這么操作,
- 首先,找到最近的一次全量備份,如昨天晚上的一次備份,我們將其備份到臨時庫中;
- 然后從備份的時間點開始,將備份的\(bin\ log\)依次取出來,重放到中午誤刪表之前的那個時刻;
這時我們的臨時庫就和誤刪之前的線上庫一樣了,這時再把表資料從臨時庫中取出來,按需要恢復到線上庫去,
由于 \(redo\ log\) 和 \(bin\ log\) 是兩個獨立的邏輯,如果不用兩階段提交,要么就是先寫完 \(redo\ log\) 再寫 \(bin\ log\),或者采用反過來的順序,我們看看這兩種方式會有什么問題,
假定當前ID=2的行,欄位c的值是0,再假定update程序中,我們寫完第一個日志后,第二個日志還沒有寫入就發生了\(crash\),會出現如下情況:
- 先寫 \(redo\ log\) 后寫 \(bin\ log\),假設在 \(redo\ log\) 寫完,\(bin\ log\) 還沒有寫完的時候,MySQL 行程例外重啟,由于我們前面說過的,\(redo\ log\) 寫完之后,系統即使崩潰,仍然能夠把資料恢復回來,所以恢復后這一行 c 的值是 1,
但是由于 \(bin\ log\) 沒寫完就 crash 了,這時候 \(bin\ log\) 里面就沒有記錄這個陳述句,因此,之后備份日志的時候,存起來的 \(bin\ log\) 里面就沒有這條陳述句,
然后你會發現,如果需要用這個 \(bin\ log\) 來恢復臨時庫的話,由于這個陳述句的 \(bin\ log\) 丟失,這個臨時庫就會少了這一次更新,恢復出來的這一行 c 的值就是 0,與原庫的值不同, - 先寫 \(bin\ log\) 后寫 \(redo\ log\),如果在 \(bin\ log\) 寫完之后 crash,由于 \(redo\ log\) 還沒寫,崩潰恢復以后這個事務無效,所以這一行 c 的值是 0,但是 \(bin\ log\) 里面已經記錄了“把 c 從 0 改成 1”這個日志,所以,在之后用 \(bin\ log\) 來恢復的時候就多了一個事務出來,恢復出來的這一行 c 的值就是 1,與原庫的值不同,
因此,可以看到,如果不使用兩階段性提交,那么資料庫的狀態就很可能和它日志恢復出來的狀態不一樣,
其實不只是恢復時需要遷移資料,當我們需要增加庫容量或者是增加備份庫來增加系統的讀能力時,都需要遷移資料,
現在的常用做法也是全量備份+\(bin\ log\)來實作的,
簡單說,\(redo\ log\) 和 \(bin\ log\) 都可以用于表示事務的提交狀態,而兩階段提交就是讓這兩個狀態保持邏輯上的一致,
?
?
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/423387.html
標籤:其他
下一篇:一條SQL更新陳述句是如何執行的