我想從網站上獲取尺寸。頁面上的表格采用這種格式,顏色、尺寸、材料等細節并不總是按相同的順序排列[如下圖示例所示]。
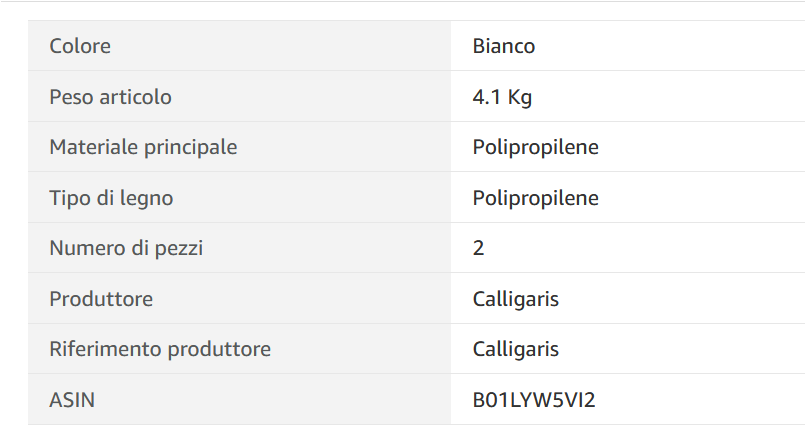

我有興趣提取這個“Peso articolo”值,它也可以作為“Peso do produto”或“Peso del producto”找到。問題是 Xpath 因頁面而異,并且表中所有詳細資訊的類都相同。
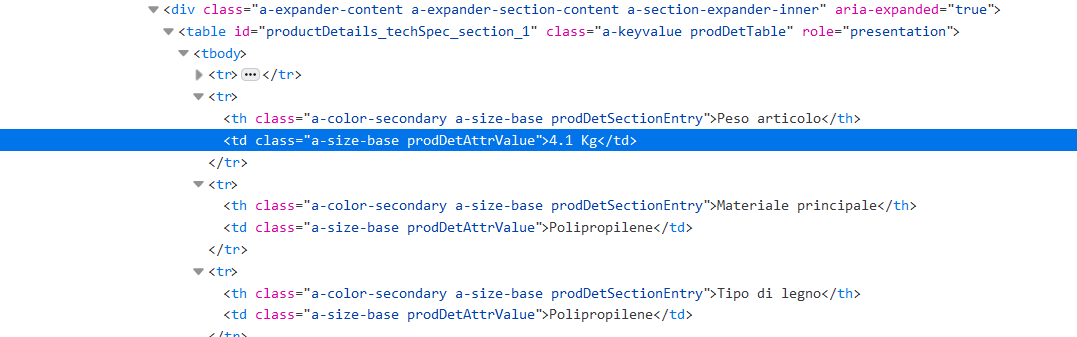
我正在使用此代碼進行提取,但由于每個頁面上的位置不同,因此有時會提取材料而不是維度 [使用 Xpath]。
def get_dimensions(driver):
# details XPATH
# details_xpath = '//*[@id="productDetails_techSpec_section_1"]/tbody/tr[4]/td'
details_xpath = '/html/body/div[2]/div[2]/div[3]/div[8]/div[7]/div/div/div/div[1]/div[1]/div/div[2]/div/div/table/tbody/tr[2]/td'
found = False
retries = 1
dimensions = ''
while retries > 0 and not found:
try:
retries = retries - 1
dimensions_elem = WebDriverWait(driver, 1).until(
EC.presence_of_element_located((By.XPATH, details_xpath))
)
found = True
dimensions = dimensions_elem.text
except:
pass
print('dimensions not found! Retrying...')
return dimensions
有沒有辦法可以更新它以僅訪問值為“Peso articolo”或“Peso do produto”或“Peso del producto”的那些類并從 td 類中獲取值?

uj5u.com熱心網友回復:
將td標簽 wrt 轉換為th標簽值Peso articolo使用以下任何方法xpath來獲取元素。
details_xpath ="//th[normalize-space(text())='Peso articolo']/following::td[1]"
或者
details_xpath ="//tr[./th[normalize-space(text())='Peso articolo']]/td"
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/424252.html