本代碼通過掃描同一行和后續行中的相鄰元素來選擇最小值。但是,如果它們小于閾值,我希望代碼選擇所有值。例如,在第 2 行中,我希望代碼同時選擇 0.86 和 0.88,因為兩者都小于 0.9,而不僅僅是 0.86、0.88 中的最小值。基本上,如果所有相鄰元素都大于閾值,則代碼應該選擇最小值。如果不是這種情況,它應該選擇所有小于閾值的值。
import numpy as np
import numba as nb
Pe = np.random.rand(5,5)
def minValues(arr):
n, m = arr.shape
assert n >= 1 and m >= 2
res = []
i, j = 0, np.argmin(arr[0,:])
res.append((i, j))
iPrev = jPrev = -1
while iPrev < n-1:
cases = [(i, j-1), (i, j 1), (i 1, j)]
minVal = np.inf
iMin = jMin = -1
# Find the best candidate (smallest value)
for (i2, j2) in cases:
if i2 == iPrev and j2 == jPrev: # No cycles
continue
if i2 < 0 or i2 >= n or j2 < 0 or j2 >= m: # No out-of-bounds
continue
if arr[i2, j2] < minVal:
iMin, jMin = i2, j2
minVal = arr[i2, j2]
assert not np.isinf(minVal)
# Store it and update the values
res.append((iMin, jMin))
iPrev, jPrev = i, j
i, j = iMin, jMin
return np.array(res)
T=minValues(Pe)
Path=Pe[T.T[0], T.T[1]]
電流輸出: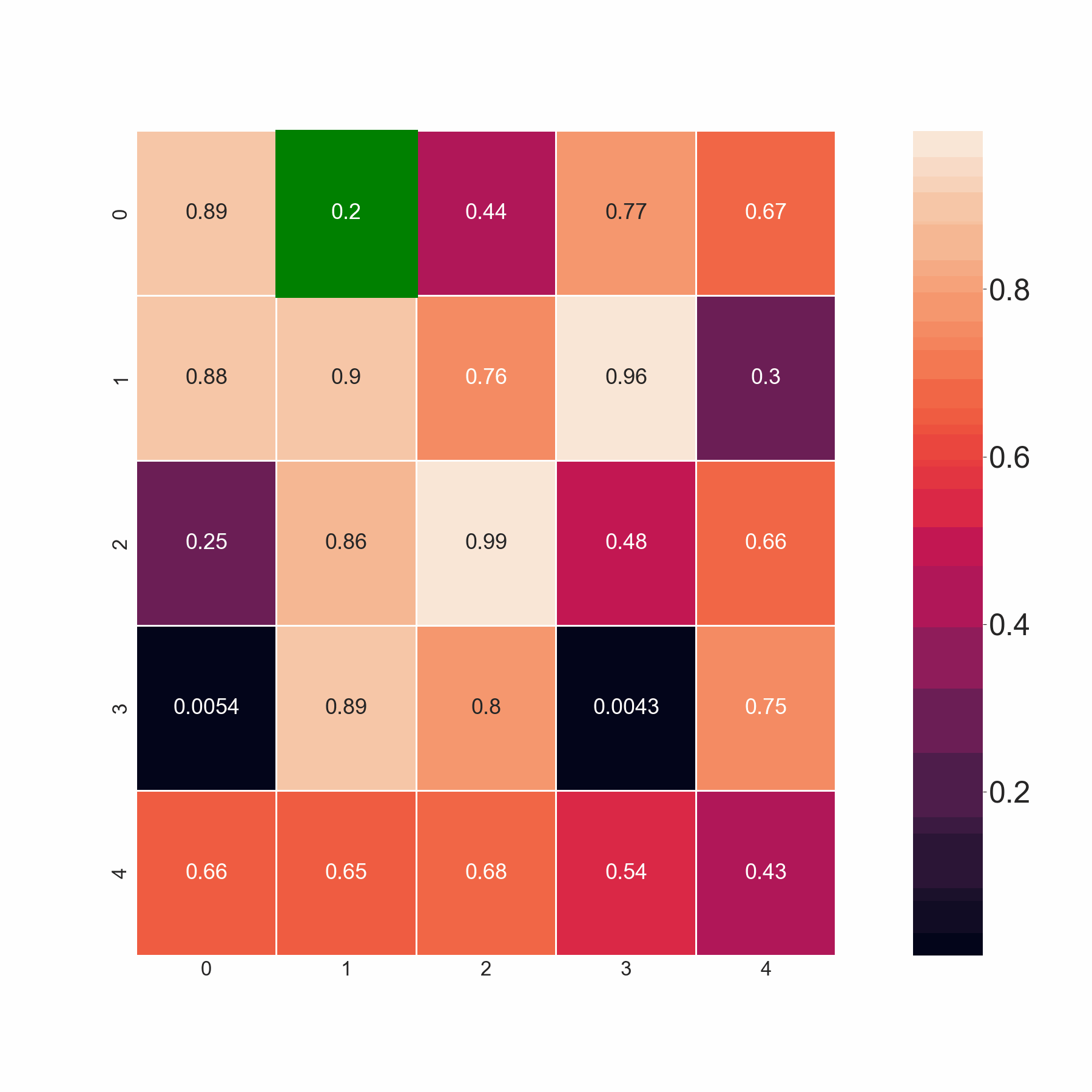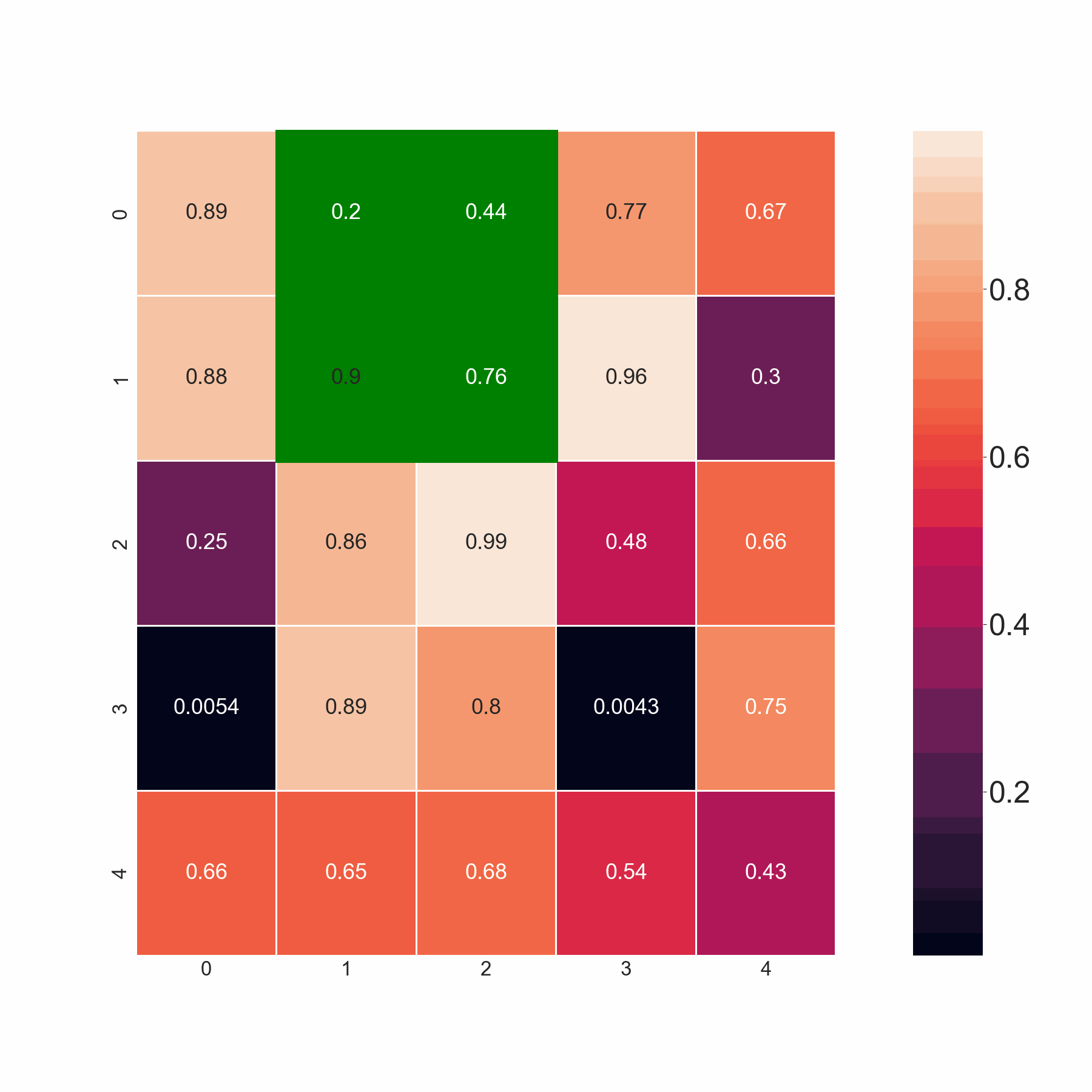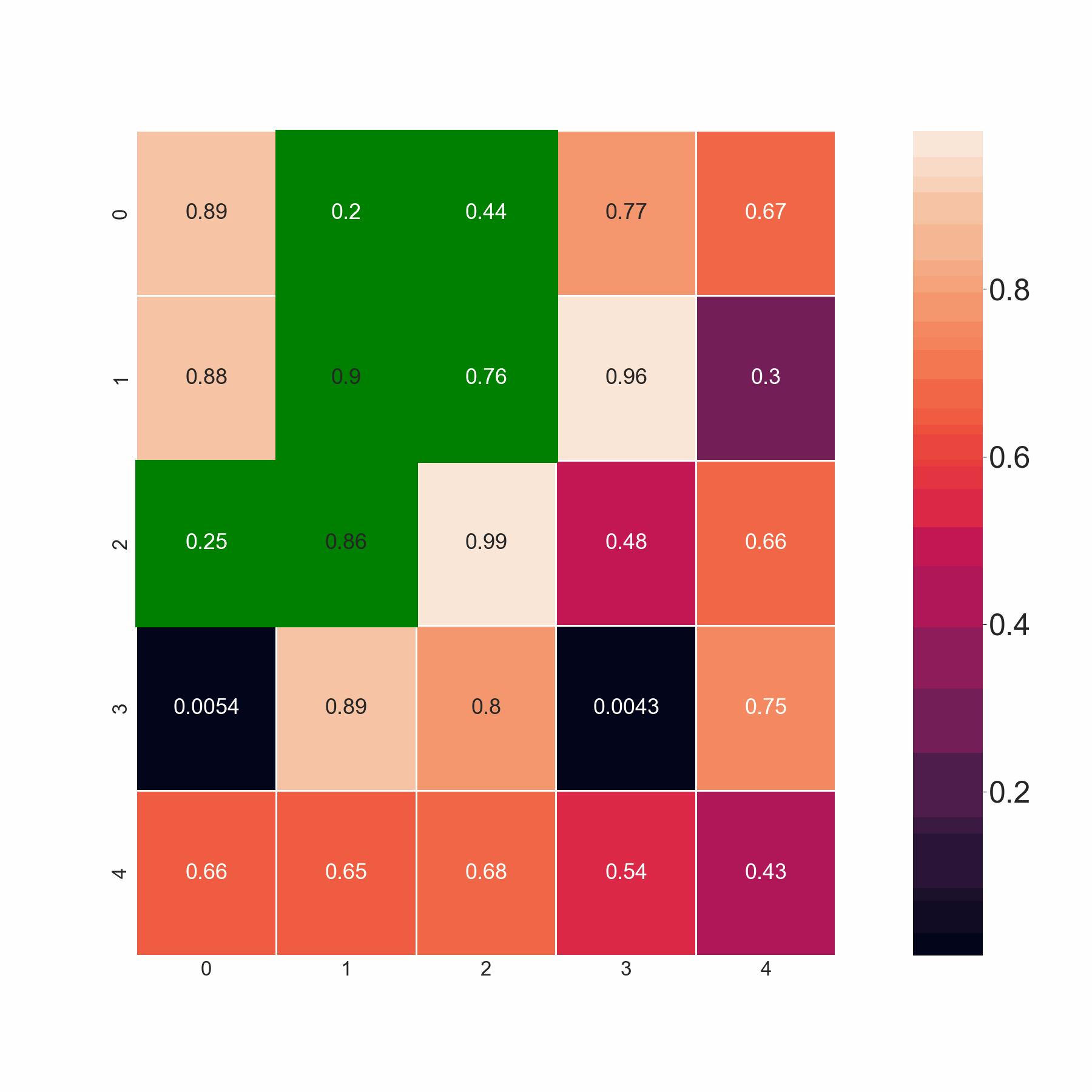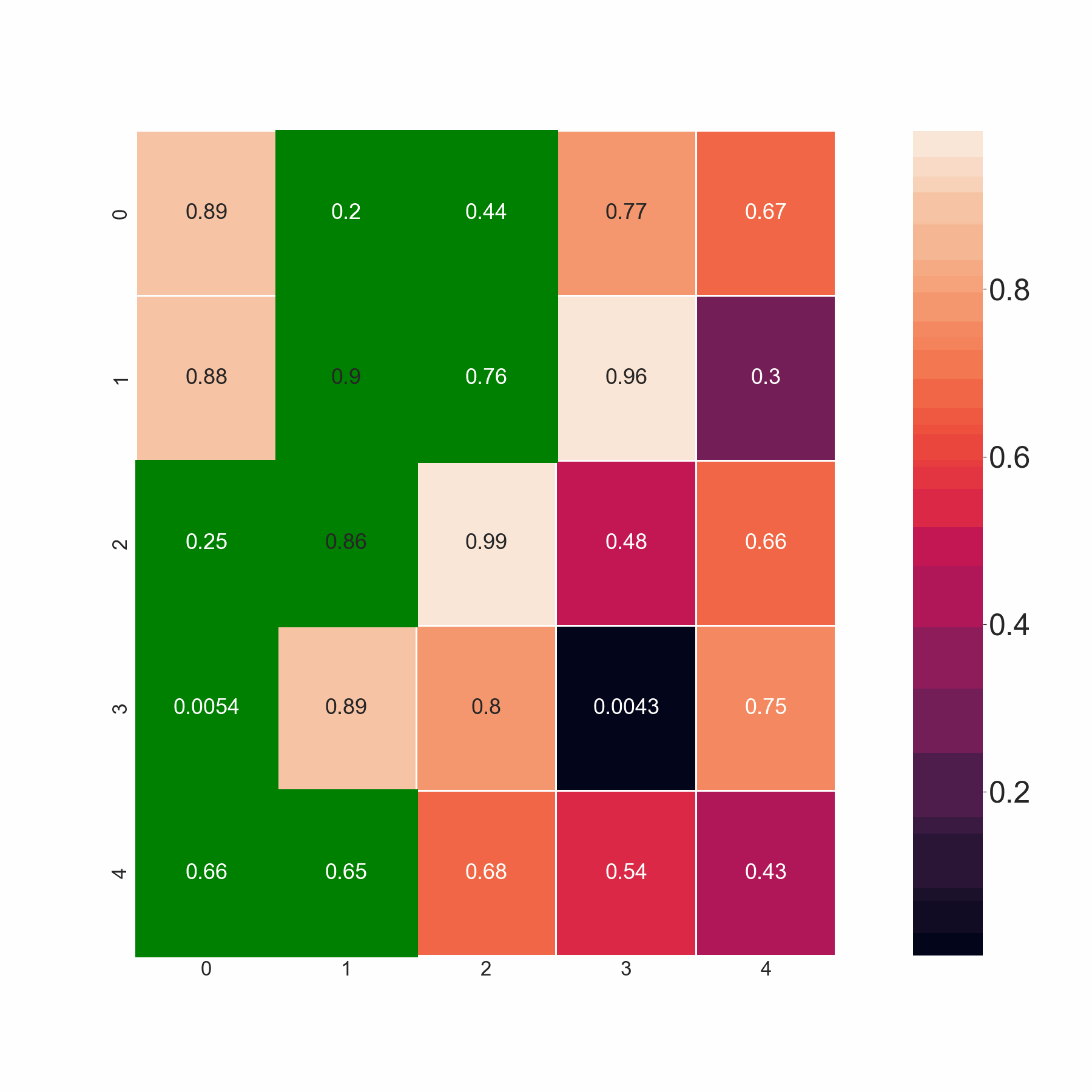
期望的輸出: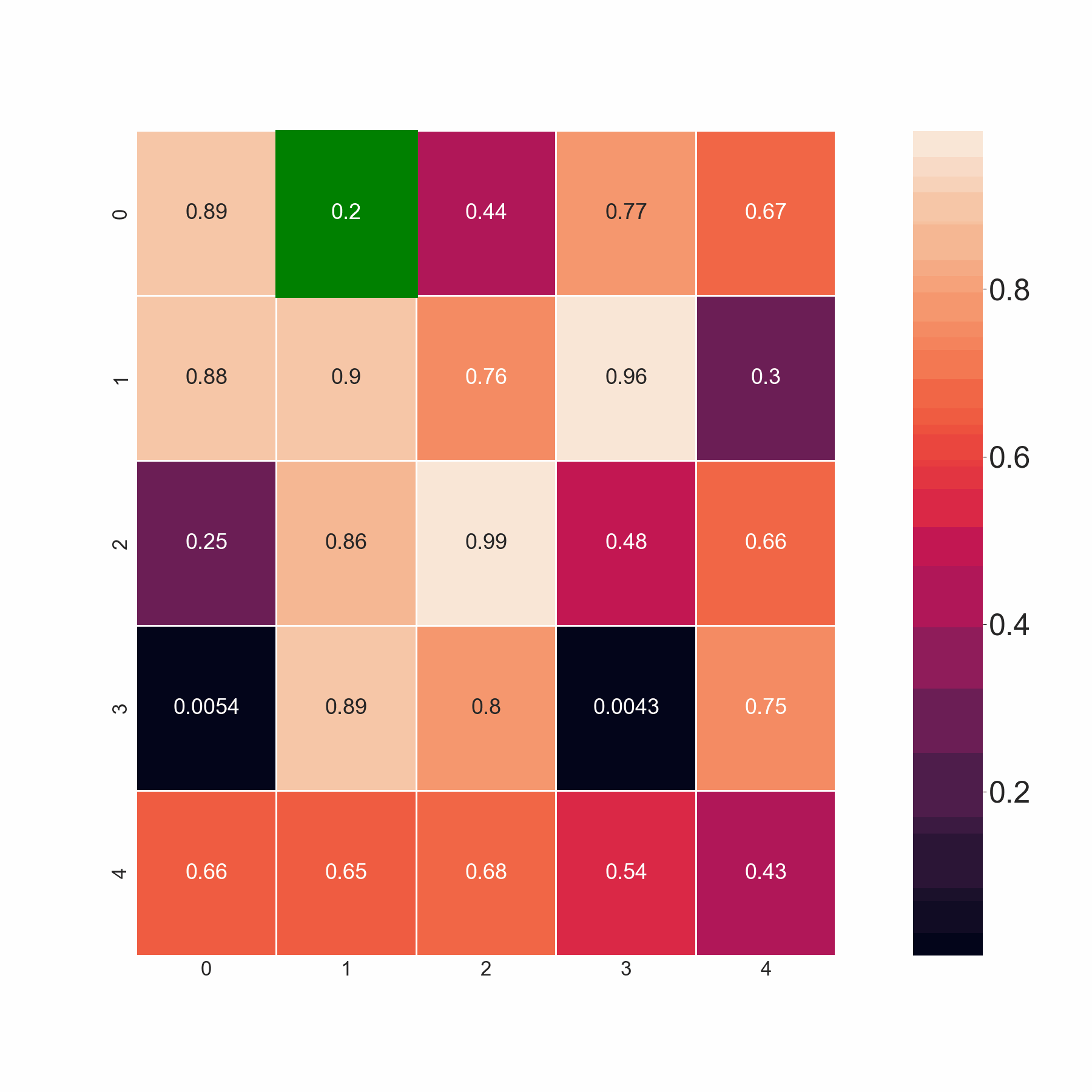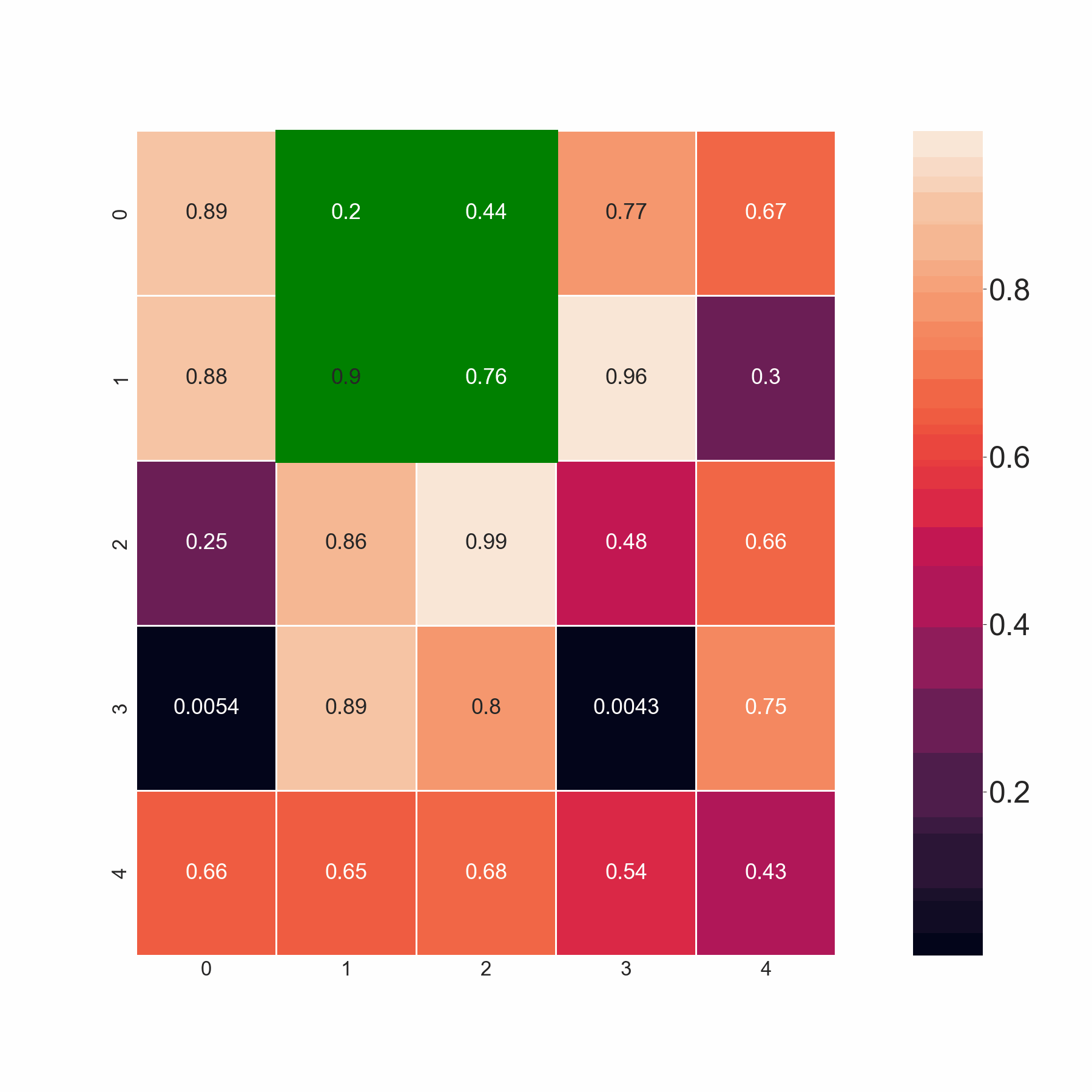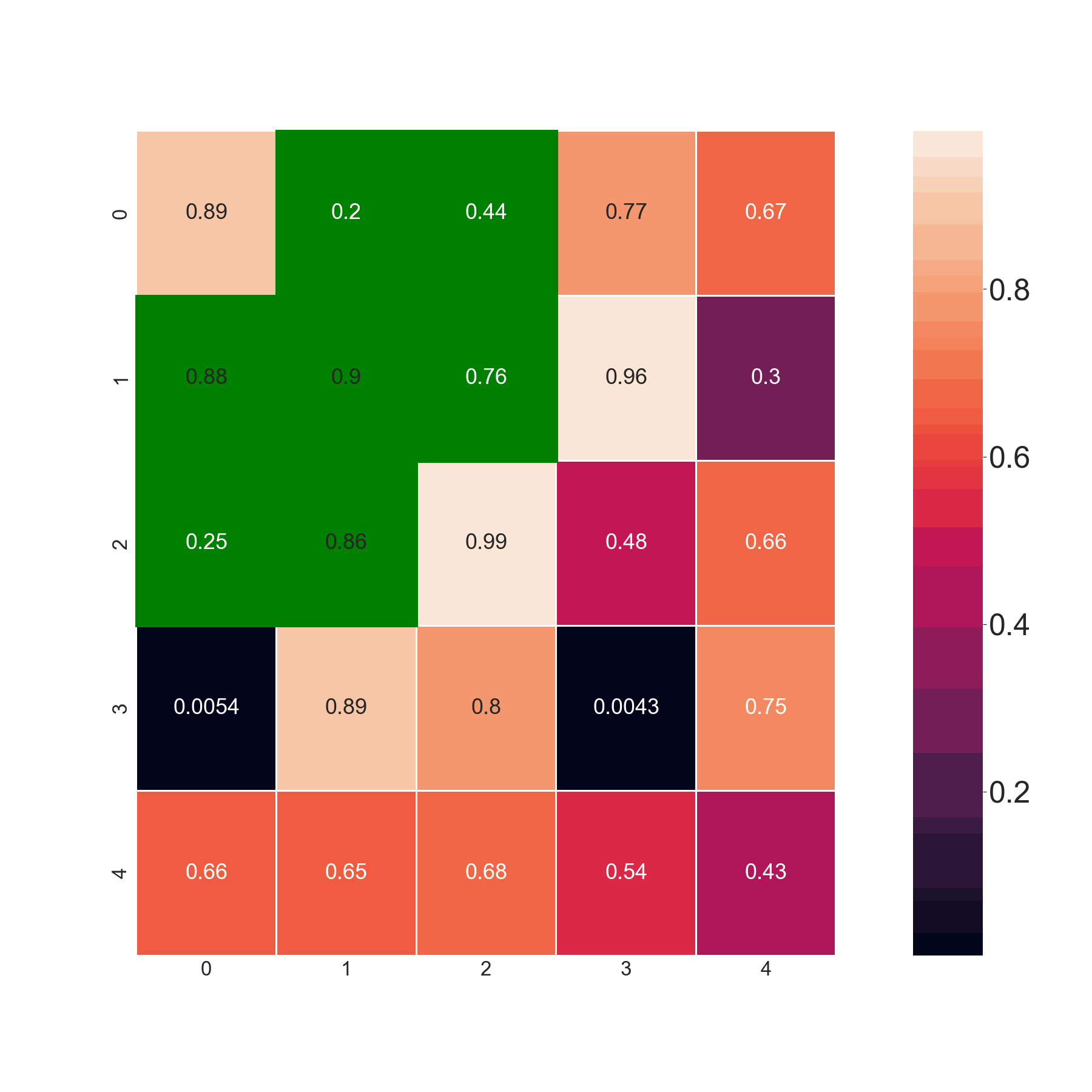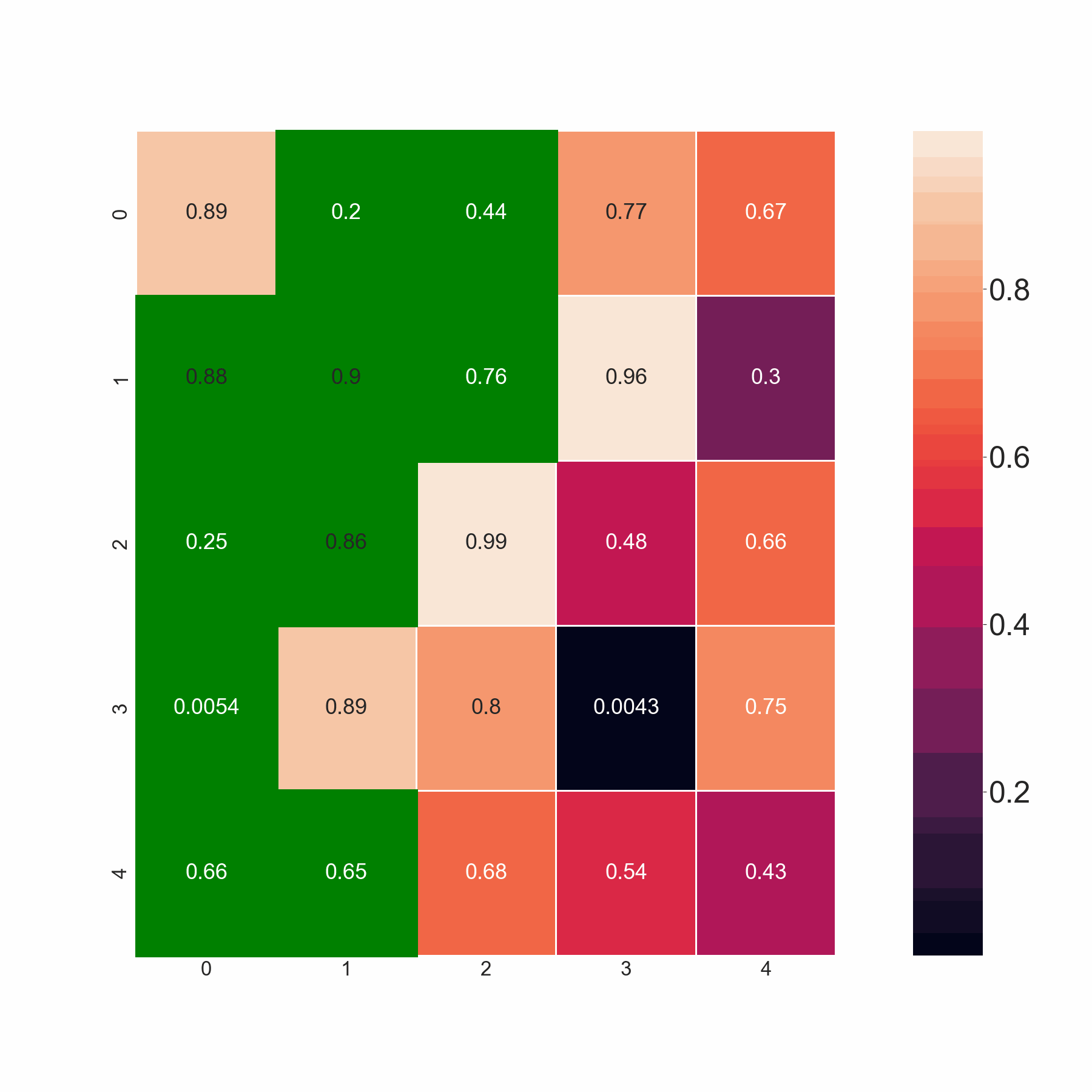
uj5u.com熱心網友回復:
試試這個:
def minValues(arr):
n, m = arr.shape
assert n >= 1 and m >= 2
res = []
i, j = 0, np.argmin(arr[0,:])
print(f"Values i, j are: {i}, {j}")
res.append((i, j))
iPrev = jPrev = -1
while iPrev < n-1:
lowerVals = []
print(f"Values iPrev, jPrev are: {iPrev}, {jPrev}")
cases = [(i, j-1), (i, j 1), (i 1, j)]
print(f"Posible cases are: {cases}")
minVal = np.inf
print(f"MinVal is: {minVal}")
iMin = jMin = -1
# Find the best candidate (smallest value)
for (i2, j2) in cases:
if i2 == iPrev and j2 == jPrev: # No cycles
continue
if i2 < 0 or i2 >= n or j2 < 0 or j2 >= m: # No out-of-bounds
continue
if arr[i2, j2] < arr[i, j]:
lowerVals.append((i2, j2))
if arr[i2, j2] < minVal:
iMin, jMin = i2, j2
minVal = arr[i2, j2]
if not lowerVals: lowerVals.append((iMin, jMin))
print(f"Values iMin, jMin are: {iMin}, {jMin}")
print(f"MinVal is: {minVal}")
print(f"Lower values are: {lowerVals}")
assert not np.isinf(minVal)
# Store it and update the values
res = lowerVals
print(f"Final res after current iteration: {res}\n")
iPrev, jPrev = i, j
i, j = iMin, jMin
return np.array(res)
我使用列印進行除錯,但我只是在每次迭代中檢查所有低于當前值的值,并在迭代結束時將它們添加到路徑中。
編輯:引入我的評論的額外行你得到上面的代碼,這應該作業。
uj5u.com熱心網友回復:
這是一個有趣的問題——看水文流/下坡方向?
描述的問題是您沒有指定哪個要迭代到下一個的相鄰單元格,這意味著,如果您有三個較低的相鄰單元格,它們都會被添加到輸出陣列中,但是選擇了哪個?此外,當回顧輸出陣列時,您如何知道相對于單個相鄰單元格添加了哪些?我通過選擇小于源單元格值(最大下降)的相鄰單元格的最小值來解決此問題,然后從該單元格繼續搜索,依此類推。對于每次迭代,對于較低的相鄰單元格,都有一個新的嵌套單元格位置串列。這可以通過多種方式輕松更新,包括匯出一個附加串列,顯示哪些單元格用于搜索(本質上是所采用的路徑,而可能有突出顯示的單元格(下部)本身沒有被訪問。
import numpy as np
Pe = np.random.rand(5,5)
def nearestMin(arr, output_arr=[[0,0]], n=0, m=0):
if m==arr.shape[1]:
return output_arr
lower_vals = np.argwhere(arr < arr[n,m])
if lower_vals.size == 0: #No values anywhere less than current cell
return output_arr
#Get offset from current point, as tuple of x and y distance
smaller_adjacents = np.where(Pe < Pe[n, m])
if smaller_adjacents[0].size == 0: #No lower points anywhere
return output_arr
ind = np.where((abs(n - smaller_adjacents[0]) <= 1 ) & \
(abs(m - smaller_adjacents[1]) <= 1))[0]
if ind.size == 0: #No lower points neighboring
return output_arr
xs, ys = smaller_adjacents[0][ind], smaller_adjacents[1][ind]
lower_neighbors = np.vstack((xs, ys)).T.tolist()
output_arr.append(lower_neighbors) #Unbracket to have final output array be flat (2d)
n_depth = [Pe[x,y] for x,y in lower_neighbors] - Pe[n,m]
biggest_drop = np.where(n_depth==n_depth.min())[0][0]
lowest_neighbor = lower_neighbors[biggest_drop]
return nearestMin(arr, output_arr, n=lowest_neighbor[0], m=lowest_neighbor[1])
nearestMin(Pe)
如果需要路徑,可以修改相同的代碼,如下所示,將其作為第二個陣列回傳。在此示例中,列出了路徑的值。每個值對應于第一個回傳的相鄰較低值陣列中的“串列串列”項。同樣,不確定您要做什么。
import numpy as np
Pe = np.random.rand(5,5)
def nearestMin(arr, output_arr=[[0,0]], path=[], n=0, m=0):
#Initialize path variable properly
if output_arr == [[0,0]]:
path.append(arr[0,0])
if m==arr.shape[1]:
return (output_arr, path)
lower_vals = np.argwhere(arr < arr[n,m])
if lower_vals.size == 0: #No values anywhere less than current cell
return (output_arr, path)
#Get offset from current point, as tuple of x and y distance
smaller_adjacents = np.where(Pe < Pe[n, m])
if smaller_adjacents[0].size == 0: #No lower points anywhere
return (output_arr, path)
ind = np.where((abs(n - smaller_adjacents[0]) <= 1 ) & \
(abs(m - smaller_adjacents[1]) <= 1))[0]
if ind.size == 0: #No lower points neighboring
return (output_arr, path)
xs, ys = smaller_adjacents[0][ind], smaller_adjacents[1][ind]
lower_neighbors = np.vstack((xs, ys)).T.tolist()
output_arr.append(lower_neighbors) #Unbracket to have final output array be flat (2d)
n_depth = [Pe[x,y] for x,y in lower_neighbors] - Pe[n,m]
biggest_drop = np.where(n_depth==n_depth.min())[0][0]
lowest_neighbor = lower_neighbors[biggest_drop]
path.append(arr[lowest_neighbor[0], lowest_neighbor[1]])
return nearestMin(arr, output_arr, path, n=lowest_neighbor[0], m=lowest_neighbor[1])
nearestMin(Pe)
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/426288.html
下一篇:ListView上的位置引數太多