對于特定查詢,我有以下 2 個查詢計劃(第二個是通過關閉 seqscan 獲得的):
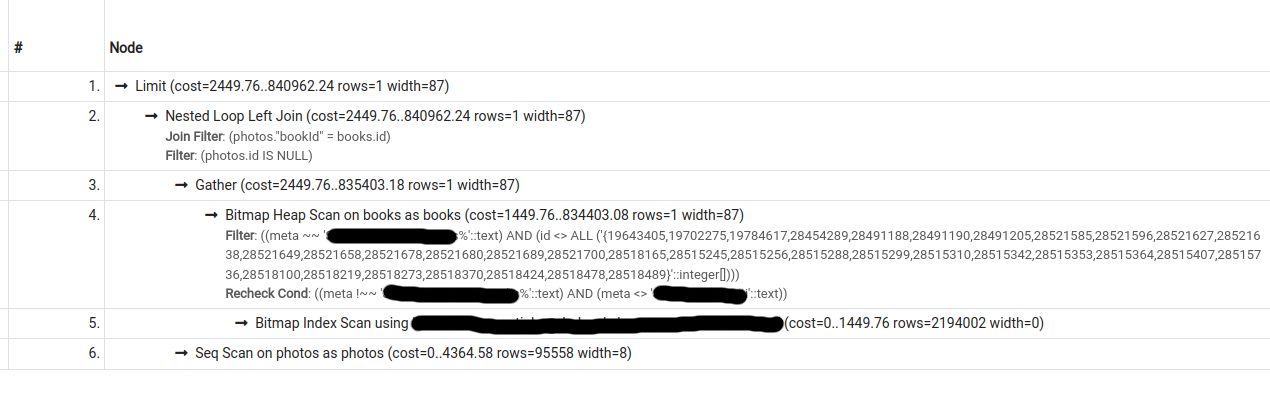
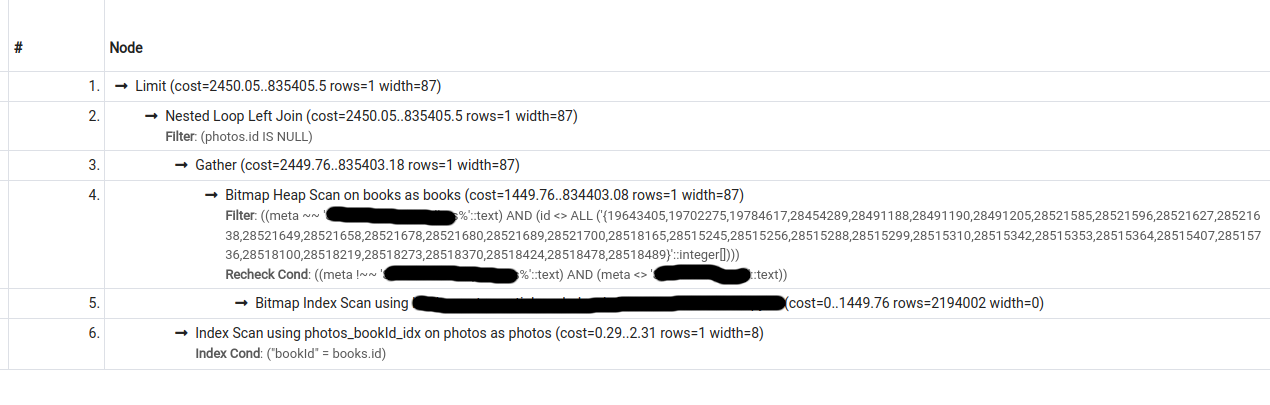
第二個計劃的成本估計低于第一個計劃,但是,如果被迫這樣做(通過關閉 seqscan),pg 只會選擇第二個計劃。
什么可能導致這種行為?
編輯:使用評論中要求的資訊更新問題:
查詢 1 的輸出EXPLAIN (ANALYZE, BUFFERS, VERBOSE)(seqscan on;不使用索引)。也可以在https://explain.depesz.com/s/cGLY上查看:
QUERY PLAN
Limit (cost=2449.76..840962.24 rows=1 width=87) (actual time=25701.021..26540.060 rows=10 loops=1)
Output: books.id, books.title, books.authors, books.meta
Buffers: shared hit=2254959
-> Nested Loop Left Join (cost=2449.76..840962.24 rows=1 width=87) (actual time=25289.899..26128.923 rows=10 loops=1)
Output: books.id, books.title, books.authors, books.meta
Join Filter: (photos."bookId" = books.id)
Rows Removed by Join Filter: 62876457
Filter: (photos.id IS NULL)
Rows Removed by Filter: 707
Buffers: shared hit=2254959
-> Gather (cost=2449.76..835403.18 rows=1 width=87) (actual time=391.874..494.669 rows=658 loops=1)
Output: books.id, books.title, books.authors, books.meta
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=11837
-> Parallel Bitmap Heap Scan on public.books (cost=1449.76..834403.08 rows=1 width=87) (actual time=868.495..874.706 rows=554 loops=3)
Output: books.id, books.title, books.authors, books.meta
Recheck Cond: ((books.meta !~~ 'foo%'::text) AND (books.meta <> 'bar'::text))
Filter: ((books.meta ~~ 'baz%'::text) AND (books.id <> ALL ('{19643405,19702275,19784617,28454289,28491188,28491190,28491205,28521585,28521596,28521627,28521638,28521649,28521658,28521678,28521680,28521689,28521700,28518165,28515245,28515256,28515288,28515299,28515310,28515342,28515353,28515364,28515407,28515736,28518100,28518219,28518273,28518370,28518424,28518478,28518489}'::integer[])))
Rows Removed by Filter: 77897
Heap Blocks: exact=11567
Buffers: shared hit=11837
Worker 0: actual time=1107.154..1115.320 rows=1113 loops=1
JIT:
Functions: 6
Options: Inlining true, Optimization true, Expressions true, Deforming true
Timing: Generation 5.001 ms, Inlining 471.271 ms, Optimization 365.866 ms, Emission 269.821 ms, Total 1111.959 ms
Buffers: shared hit=40
Worker 1: actual time=1108.335..1108.975 rows=541 loops=1
JIT:
Functions: 6
Options: Inlining true, Optimization true, Expressions true, Deforming true
Timing: Generation 11.915 ms, Inlining 450.341 ms, Optimization 364.168 ms, Emission 293.461 ms, Total 1119.885 ms
Buffers: shared hit=21
-> Bitmap Index Scan on books_meta_partial_exclude_foo_and_bar (cost=0.00..1449.76 rows=2194002 width=0) (actual time=41.801..41.802 rows=238689 loops=1)
Buffers: shared hit=209
-> Seq Scan on public.photos (cost=0.00..4364.58 rows=95558 width=8) (actual time=0.002..17.127 rows=95558 loops=658)
Output: photos.id, photos.url, photos.type, photos."userId", photos."libraryId", photos."bookId", photos."libraryBookId", photos."isPrimaryPic", photos."processingStatus", photos."createdAt", photos."updatedAt", photos."otherData"
Buffers: shared hit=2243122
Planning:
Buffers: shared hit=17
Planning Time: 0.758 ms
JIT:
Functions: 24
Options: Inlining true, Optimization true, Expressions true, Deforming true
Timing: Generation 20.953 ms, Inlining 1005.367 ms, Optimization 915.620 ms, Emission 705.338 ms, Total 2647.278 ms
Execution Time: 26544.310 ms
EXPLAIN (ANALYZE, BUFFERS, VERBOSE)查詢 2 的輸出(seqscan 關閉;使用索引)。也可以在https://explain.depesz.com/s/VDfP查看:
QUERY PLAN
Limit (cost=2450.18..835405.63 rows=1 width=87) (actual time=1110.719..2424.086 rows=10 loops=1)
Output: books.id, books.title, books.authors, books.meta
Buffers: shared hit=16834
-> Nested Loop Left Join (cost=2450.18..835405.63 rows=1 width=87) (actual time=464.812..1778.175 rows=10 loops=1)
Output: books.id, books.title, books.authors, books.meta
Filter: (photos.id IS NULL)
Rows Removed by Filter: 1321
Buffers: shared hit=16834
-> Gather (cost=2449.76..835403.18 rows=1 width=87) (actual time=411.878..1753.914 rows=1232 loops=1)
Output: books.id, books.title, books.authors, books.meta
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=11822
-> Parallel Bitmap Heap Scan on public.books (cost=1449.76..834403.08 rows=1 width=87) (actual time=653.691..663.053 rows=411 loops=3)
Output: books.id, books.title, books.authors, books.meta
Recheck Cond: ((books.meta !~~ 'foo%'::text) AND (books.meta <> 'bar'::text))
Filter: ((books.meta ~~ 'baz%'::text) AND (books.id <> ALL ('{19643405,19702275,19784617,28454289,28491188,28491190,28491205,28521585,28521596,28521627,28521638,28521649,28521658,28521678,28521680,28521689,28521700,28518165,28515245,28515256,28515288,28515299,28515310,28515342,28515353,28515364,28515407,28515736,28518100,28518219,28518273,28518370,28518424,28518478,28518489}'::integer[])))
Rows Removed by Filter: 77893
Heap Blocks: exact=11611
Buffers: shared hit=11822
Worker 0: actual time=774.890..774.891 rows=1 loops=1
JIT:
Functions: 6
Options: Inlining true, Optimization true, Expressions true, Deforming true
Timing: Generation 14.889 ms, Inlining 364.167 ms, Optimization 205.348 ms, Emission 205.226 ms, Total 789.630 ms
Buffers: shared hit=1
Worker 1: actual time=780.309..780.311 rows=1 loops=1
JIT:
Functions: 6
Options: Inlining true, Optimization true, Expressions true, Deforming true
Timing: Generation 4.595 ms, Inlining 362.465 ms, Optimization 209.509 ms, Emission 208.145 ms, Total 784.715 ms
Buffers: shared hit=1
-> Bitmap Index Scan on books_meta_partial_exclude_foo_and_bar (cost=0.00..1449.76 rows=2194002 width=0) (actual time=56.500..56.501 rows=238689 loops=1)
Buffers: shared hit=209
-> Index Scan using "photos_bookId_idx" on public.photos (cost=0.42..2.44 rows=1 width=8) (actual time=0.012..0.013 rows=1 loops=1232)
Output: photos.id, photos.url, photos.type, photos."userId", photos."libraryId", photos."bookId", photos."libraryBookId", photos."isPrimaryPic", photos."processingStatus", photos."createdAt", photos."updatedAt", photos."otherData"
Index Cond: (photos."bookId" = books.id)
Buffers: shared hit=5012
Planning:
Buffers: shared hit=17
Planning Time: 2.640 ms
JIT:
Functions: 25
Options: Inlining true, Optimization true, Expressions true, Deforming true
Timing: Generation 39.565 ms, Inlining 839.818 ms, Optimization 765.817 ms, Emission 599.027 ms, Total 2244.228 ms
Execution Time: 2455.226 ms
編輯 2:添加有關表結構、索引和查詢本身的資訊
-- Table: public.books
-- DROP TABLE IF EXISTS public.books;
CREATE TABLE IF NOT EXISTS public.books
(
id integer NOT NULL DEFAULT nextval('books_id_seq'::regclass),
title text COLLATE pg_catalog."default" NOT NULL,
authors text COLLATE pg_catalog."default" NOT NULL,
slug text COLLATE pg_catalog."default" NOT NULL,
"desc" text COLLATE pg_catalog."default",
meta text COLLATE pg_catalog."default",
"createdAt" timestamp(3) without time zone NOT NULL DEFAULT CURRENT_TIMESTAMP,
"updatedAt" timestamp(3) without time zone NOT NULL,
tsv tsvector GENERATED ALWAYS AS (to_tsvector('english'::regconfig, ((COALESCE(title, ''::text) || ' '::text) || COALESCE(authors, ''::text)))) STORED,
CONSTRAINT books_pkey PRIMARY KEY (id)
)
TABLESPACE pg_default;
ALTER TABLE IF EXISTS public.books
OWNER to [REDACTED];
-- Index: books_fts_idx
-- DROP INDEX IF EXISTS public.books_fts_idx;
CREATE INDEX IF NOT EXISTS books_fts_idx
ON public.books USING gin
(tsv)
TABLESPACE pg_default;
-- Index: books_meta_partial_exclude_foo_and_bar
-- DROP INDEX IF EXISTS public.books_meta_partial_exclude_foo_and_bar;
CREATE INDEX IF NOT EXISTS books_meta_partial_exclude_foo_and_bar
ON public.books USING btree
(meta COLLATE pg_catalog."default" ASC NULLS LAST)
TABLESPACE pg_default
WHERE meta !~~ 'foo%'::text AND meta <> 'bar'::text;
-- Index: books_slug_key
-- DROP INDEX IF EXISTS public.books_slug_key;
CREATE UNIQUE INDEX IF NOT EXISTS books_slug_key
ON public.books USING btree
(slug COLLATE pg_catalog."default" ASC NULLS LAST)
TABLESPACE pg_default;
-- Table: public.photos
-- DROP TABLE IF EXISTS public.photos;
CREATE TABLE IF NOT EXISTS public.photos
(
id integer NOT NULL DEFAULT nextval('photos_id_seq'::regclass),
url text COLLATE pg_catalog."default" NOT NULL,
type text COLLATE pg_catalog."default",
"userId" integer,
"libraryId" integer,
"bookId" integer,
"libraryBookId" integer,
"isPrimaryPic" boolean DEFAULT false,
"processingStatus" "PhotoProcessingStatus" NOT NULL DEFAULT 'UNPROCESSED'::"PhotoProcessingStatus",
"createdAt" timestamp(3) without time zone NOT NULL DEFAULT CURRENT_TIMESTAMP,
"updatedAt" timestamp(3) without time zone NOT NULL,
"otherData" jsonb,
CONSTRAINT photos_pkey PRIMARY KEY (id),
CONSTRAINT "photos_bookId_fkey" FOREIGN KEY ("bookId")
REFERENCES public.books (id) MATCH SIMPLE
ON UPDATE CASCADE
ON DELETE SET NULL,
CONSTRAINT "photos_libraryBookId_fkey" FOREIGN KEY ("libraryBookId")
REFERENCES public.library_books (id) MATCH SIMPLE
ON UPDATE CASCADE
ON DELETE SET NULL,
CONSTRAINT "photos_libraryId_fkey" FOREIGN KEY ("libraryId")
REFERENCES public.libraries (id) MATCH SIMPLE
ON UPDATE CASCADE
ON DELETE SET NULL,
CONSTRAINT "photos_userId_fkey" FOREIGN KEY ("userId")
REFERENCES public.users (id) MATCH SIMPLE
ON UPDATE CASCADE
ON DELETE SET NULL
)
TABLESPACE pg_default;
ALTER TABLE IF EXISTS public.photos
OWNER to [REDACTED];
-- Index: photos_bookId_idx
-- DROP INDEX IF EXISTS public."photos_bookId_idx";
CREATE INDEX IF NOT EXISTS "photos_bookId_idx"
ON public.photos USING btree
("bookId" ASC NULLS LAST)
TABLESPACE pg_default;
-- Index: photos_libraryId_idx
-- DROP INDEX IF EXISTS public."photos_libraryId_idx";
CREATE INDEX IF NOT EXISTS "photos_libraryId_idx"
ON public.photos USING btree
("libraryId" ASC NULLS LAST)
TABLESPACE pg_default;
-- Index: photos_userId_idx
-- DROP INDEX IF EXISTS public."photos_userId_idx";
CREATE INDEX IF NOT EXISTS "photos_userId_idx"
ON public.photos USING btree
("userId" ASC NULLS LAST)
TABLESPACE pg_default;
查詢本身是:
SELECT
books.id, books.title, books.authors, books.meta
FROM books
LEFT JOIN photos ON photos."bookId" = books.id
WHERE photos.id IS NULL
AND books.id NOT IN (19643405,19702275,19784617,28454289,28491188,28491190,28491205,28521585,28521596,28521627,28521638,28521649,28521658,28521678,28521680,28521689,28521700,28518165,28515245,28515256,28515288,28515299,28515310,28515342,28515353,28515364,28515407,28515736,28518100,28518219,28518273,28518370,28518424,28518478,28518489)
AND meta NOT LIKE 'foo%'
AND meta != 'bar'
AND meta LIKE 'baz%'
LIMIT 10;
uj5u.com熱心網友回復:
這兩個計劃實際上是捆綁在一起的,它們的預期成本相差不到 1%。計劃者避免完全充實顯然捆綁的計劃,以避免額外的作業。
請參閱源代碼中的 compare_path_costs_fuzzily。
uj5u.com熱心網友回復:
你應該有這兩個索引來加速你的查詢:
CREATE INDEX X1 ON books (meta, id) INCLUDE (title, authors);
CREATE INDEX X2 ON photos (id, bookId);
還要重寫您的查詢以消除過濾謂詞的冗余成員:
SELECT books.id, books.title, books.authors, books.meta
FROM books
LEFT OUTER JOIN photos
ON photos.bookId = books.id
WHERE photos.id IS NULL
AND books.id NOT IN (19643405,19702275,19784617,28454289,28491188,28491190,28491205,28521585,28521596,28521627,28521638,28521649,28521658,28521678,28521680,28521689,28521700,28518165,28515245,28515256,28515288,28515299,28515310,28515342,28515353,28515364,28515407,28515736,28518100,28518219,28518273,28518370,28518424,28518478,28518489)
-- AND books.meta NOT LIKE '[REDACTED-1]%' --> useless because books.meta LIKE '[REDACTED-3]%'
-- AND books.meta != '[REDACTED-2]' --> useless because books.meta LIKE '[REDACTED-3]%'
AND books.meta LIKE '[REDACTED-3]%'
LIMIT 10;
最后使用臨時表可能會做得更好:
CREATE LOCAL TEMPORARY TABLE temp_books_NOT_IN
(id INT PRIMARY KEY);
INSERT INTO temp_books_NOT_IN VALUES
(19643405),
(19702275),
(19784617),
(28454289),
(28491188),
(28491190),
(28491205),
(28521585),
(28521596),
(28521627),
(28521638),
(28521649),
(28521658),
(28521678),
(28521680),
(28521689),
(28521700),
(28518165),
(28515245),
(28515256),
(28515288),
(28515299),
(28515310),
(28515342),
(28515353),
(28515364),
(28515407),
(28515736),
(28518100),
(28518219),
(28518273),
(28518370),
(28518424),
(28518478),
(28518489);
SELECT books.id, books.title, books.authors, books.meta
FROM books
LEFT OUTER JOIN photos
ON photos.bookId = books.id
WHERE photos.id IS NULL
AND books.meta LIKE '[REDACTED-3]%'
AND books.id NOT IN (SELECT id FROM temp_books_NOT_IN)
LIMIT 10;
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/426892.html
標籤:PostgreSQL