一、存盤引擎
資料庫存盤引擎是資料庫底層軟體組織,資料庫管理系統(DBMS)使用資料引擎進行創建、查詢、更新和洗掉資料,不同的存盤引擎提供不同的存盤機制、索引技巧、鎖定水平等功能,使用不同的存盤引擎,還可以獲得特定的功能,現在許多不同的資料庫管理系統都支持多種不同的資料引擎,
因為在關系資料庫中資料的存盤是以表的形式存盤的,所以存盤引擎也可以稱為表型別(Table Type,即存盤和操作此表的型別),
1.1 MySQL存盤引擎
MySQL給開發者提供了查詢存盤引擎的功能,執行以下sql即可查詢到mysql中的存盤引擎:
show engines;
我的MySQL版本是5.6.50,下面是執行結果:
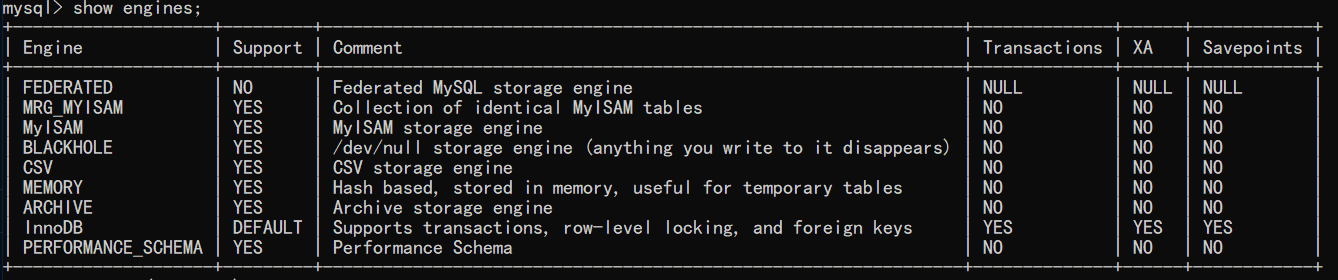
-
InnoDB存盤引擎
InnoDB是事務型資料庫的首選引擎,通過上圖也看到了,InnoDB是目前MYSQL的默認事務型引擎,是目前最重要、使用最廣泛的存盤引擎,支持事務安全表(ACID),支持行鎖定和外鍵,InnoDB主要特性有:
1、InnoDB給MySQL提供了具有提交、回滾和崩潰恢復能力的事物安全(ACID兼容)存盤引擎,InnoDB鎖定在行級并且也在SELECT陳述句中提供一個類似Oracle的非鎖定讀,這些功能增加了多用戶部署和性能,在SQL查詢中,可以自由地將InnoDB型別的表和其他MySQL的表型別混合起來,甚至在同一個查詢中也可以混合,
2、InnoDB是為處理巨大資料量的最大性能設計,它的CPU效率可能是任何其他基于磁盤的關系型資料庫引擎鎖不能匹敵的,
3、InnoDB存盤引擎完全與MySQL服務器整合,InnoDB存盤引擎為在主記憶體中快取資料和索引而維持它自己的緩沖池,InnoDB將它的表和索引在一個邏輯表空間中,表空間可以包含數個檔案(或原始磁盤檔案),這與MyISAM表不同,比如在MyISAM表中每個表被存放在分離的檔案中,InnoDB表可以是任何尺寸,即使在檔案尺寸被限制為2GB的作業系統上
4、InnoDB支持外鍵完整性約束,存盤表中的資料時,每張表的存盤都按主鍵順序存放,如果沒有在表定義時指定主鍵,InnoDB會為每一行生成一個6位元組的ROWID,并以此作為主鍵,
5、InnoDB被用在眾多需要高性能的大型資料庫站點上,
InnoDB不創建目錄,使用InnoDB時,MySQL將在MySQL資料目錄下創建一個名為ibdata1的10MB大小的自動擴展資料檔案,以及兩個名為ib_logfile0和ib_logfile1的5MB大小的日志檔案,
場景:由于其支持事務處理,支持外鍵,支持崩潰修復能力和并發控制,如果需要對事務的完整性要求比較高(比如銀行),要求實作并發控制(比如售票),那選擇InnoDB有很大的優勢,如果需要頻繁的更新、洗掉操作的資料庫,也可以選擇InnoDB,因為支持事務的提交(commit)和回滾(rollback),
-
MyISAM存盤引擎
MyISAM基于ISAM存盤引擎,并對其進行擴展,它是在Web、資料倉儲和其他應用環境下最常使用的存盤引擎之一,MyISAM擁有較高的插入、查詢速度,但不支持事物和外鍵,
MyISAM主要特性有:
1、大檔案(達到63位檔案長度)在支持大檔案的檔案系統和作業系統上被支持,
2、當把洗掉和更新及插入操作混合使用的時候,動態尺寸的行產生更少碎片,這要通過合并相鄰被洗掉的塊,以及若下一個塊被洗掉,就擴展到下一塊自動完成,
3、每個MyISAM表最大索引數是64,這可以通過重新編譯來改變,每個索引最大的列數是16,
4、最大的鍵長度是1000位元組,這也可以通過編譯來改變,對于鍵長度超過250位元組的情況,一個超過1024位元組的鍵將被用上,
5、BLOB和TEXT列可以被索引,支持FULLTEXT型別的索引,而InnoDB不支持這種型別的索引,
6、NULL被允許在索引的列中,這個值占每個鍵的0~1個位元組,
7、所有數字鍵值以高位元組優先被存盤以允許一個更高的索引壓縮,
8、每個MyISAM型別的表都有一個AUTO_INCREMENT的內部列,當INSERT和UPDATE操作的時候該列被更新,同時AUTO_INCREMENT列將被重繪,所以說,MyISAM型別表的AUTO_INCREMENT列更新比InnoDB型別的AUTO_INCREMENT更快,
9、可以把資料檔案和索引檔案放在不同目錄,
10、每個字符列可以有不同的字符集,
11、有VARCHAR的表可以固定或動態記錄長度,
12、VARCHAR和CHAR列可以多達64KB,
存盤格式:
1、靜態表(默認):欄位都是非變長的(每個記錄都是固定長度的),存盤非常迅速、容易快取,出現故障容易恢復;占用空間通常比動態表多,
2、動態表:占用的空間相對較少,但是頻繁的更新洗掉記錄會產生碎片,需要定期執行optimize table或myisamchk -r命令來改善性能,而且出現故障的時候恢復比較困難,
3、壓縮表:使用myisampack工具創建,占用非常小的磁盤空間,因為每個記錄是被單獨壓縮的,所以只有非常小的訪問開支,
靜態表的資料在存盤的時候會按照列的寬度定義補足空格,在回傳資料給應用之前去掉這些空格,如果需要保存的內容后面本來就有空格,在回傳結果的時候也會被去掉,(其實是資料型別char的行為,動態表中若有這個資料型別也同樣會有這個問題)
使用MyISAM引擎創建資料庫,將產生3個檔案,檔案的名字以表名字開始,擴展名之處檔案型別:frm檔案存盤表定義、資料檔案的擴展名為.MYD(MYData)、索引檔案的擴展名時.MYI(MYIndex),
場景:如果表主要是用于插入新記錄和讀出記錄,那么選擇MyISAM能實作處理高效率,
-
MEMORY存盤引擎
MEMORY存盤引擎將表中的資料存盤到記憶體中,為查詢和參考其他表資料提供快速訪問,MEMORY主要特性有:
1、MEMORY表的每個表可以有多達32個索引,每個索引16列,以及500位元組的最大鍵長度,
2、MEMORY存盤引擎執行HASH和BTREE縮影,
3、可以在一個MEMORY表中有非唯一鍵值,
4、MEMORY表使用一個固定的記錄長度格式,
5、MEMORY不支持BLOB或TEXT列,
6、MEMORY支持AUTO_INCREMENT列和對可包含NULL值的列的索引,
7、MEMORY表在所由客戶端之間共享(就像其他任何非TEMPORARY表),
8、MEMORY表記憶體被存盤在記憶體中,記憶體是MEMORY表和服務器在查詢處理時的空閑中,創建的內部表共享,
9、當不再需要MEMORY表的內容時,要釋放被MEMORY表使用的記憶體,應該執行DELETE FROM或TRUNCATE TABLE,或者洗掉整個表(使用DROP TABLE),
MEMORY存盤引擎默認使用哈希(HASH)索引,其速度比使用B-+Tree型要快,但也可以使用B樹型索引,由于這種存盤引擎所存盤的資料保存在記憶體中,所以其保存的資料具有不穩定性,比如如果mysqld行程發生例外、重啟或計算機關機等等都會造成這些資料的消失,所以這種存盤引擎中的表的生命周期很短,一般只使用一次,現在mongodb、redis等NOSQL資料庫愈發流行,MEMORY存盤引擎的使用場景越來越少,
場景:如果需要該資料庫中一個用于查詢的臨時表,
-
BLACKHOLE存盤引擎(黑洞引擎)
該存盤引擎支持事務,而且支持mvcc的行級鎖,寫入這種引擎表中的任何資料都會消失,主要用于做日志記錄或同步歸檔的中繼存盤,這個存盤引擎除非有特別目的,否則不適合使用,
場景:如果配置一主多從的話,多個從服務器會在主服務器上分別開啟自己相對應的執行緒,執行 binlogdump 命令而且多個此類行程并不是共享的,為了避免因多個從服務器同時請求同樣的事件而導致主機資源耗盡,可以單獨建立一個偽的從服務器或者叫分發服務器,
-
MERGE存盤引擎
MERGE存盤引擎是一組MyISAM表的組合,這些MyISAM表結構必須完全相同,盡管其使用不如其它引擎突出,但是在某些情況下非常有用,說白了,Merge表就是幾個相同MyISAM表的聚合器;Merge表中并沒有資料,對Merge型別的表可以進行查詢、更新、洗掉操作,這些操作實際上是對內部的MyISAM表進行操作,
場景:對于服務器日志這種資訊,一般常用的存盤策略是將資料分成很多表,每個名稱與特定的時間端相關,例如:可以用12個相同的表來存盤服務器日志資料,每個表用對應各個月份的名字來命名,當有必要基于所有12個日志表的資料來生成報表,這意味著需要撰寫并更新多表查詢,以反映這些表中的資訊,與其撰寫這些可能出現錯誤的查詢,不如將這些表合并起來使用一條查詢,之后再洗掉Merge表,而不影響原來的資料,洗掉Merge表只是洗掉Merge表的定義,對內部的表沒有任何影響,
-
ARCHIVE存盤引擎
Archive是歸檔的意思,在歸檔之后很多的高級功能就不再支持了,僅僅支持最基本的插入和查詢兩種功能,在MySQL 5.5版以前,Archive是不支持索引,但是在MySQL 5.5以后的版本中就開始支持索引了,Archive擁有很好的壓碩訓制,它使用zlib壓縮庫,在記錄被請求時會實時壓縮,所以它經常被用來當做倉庫使用,
場景:由于高壓縮和快速插入的特點Archive非常適合作為日志表的存盤引擎,但是前提是不經常對該表進行查詢操作,
-
CSV存盤引擎
使用該引擎的MySQL資料庫表會在MySQL安裝目錄data檔案夾中的和該表所在資料庫名相同的目錄中生成一個.CSV檔案(所以,它可以將CSV型別的檔案當做表進行處理),這種檔案是一種普通文本檔案,每個資料行占用一個文本行,該種型別的存盤引擎不支持索引,即使用該種型別的表沒有主鍵列;另外也不允許表中的欄位為null,csv的編碼轉換需要格外注意,
場景:這種引擎支持從資料庫中拷入/拷出CSV檔案,如果從電子表格軟體輸出一個CSV檔案,將其存放在MySQL服務器的資料目錄中,服務器就能夠馬上讀取相關的CSV檔案,同樣,如果寫資料庫到一個CSV表,外部程式也可以立刻讀取它,在實作某種型別的日志記錄時,CSV表作為一種資料交換格式,特別有用,
-
PERFORMANCE_SCHEMA存盤引擎
該引擎主要用于收集資料庫服務器性能引數,這種引擎提供以下功能:提供行程等待的詳細資訊,包括鎖、互斥變數、檔案資訊;保存歷史的事件匯總資訊,為提供MySQL服務器性能做出詳細的判斷;對于新增和洗掉監控事件點都非常容易,并可以隨意改變mysql服務器的監控周期,例如(CYCLE、MICROSECOND), MySQL用戶是不能創建存盤引擎為PERFORMANCE_SCHEMA的表,
場景: DBA能夠較明細得了解性能降低可能是由于哪些瓶頸,
-
Federated存盤引擎
該存盤引擎可以不同的Mysql服務器聯合起來,邏輯上組成一個完整的資料庫,這種存盤引擎非常適合資料庫分布式應用,
Federated存盤引擎可以使你在本地資料庫中訪問遠程資料庫中的資料,針對federated存盤引擎表的查詢會被發送到遠程資料庫的表上執行,本地是不存盤任何資料的,
缺點:
-
對本地虛擬表的結構修改,并不會修改遠程表的結構
-
truncate 命令,會清除遠程表資料
-
drop命令只會洗掉虛擬表,并不會洗掉遠程表
-
不支持 alter table 命令
-
select count(*), select * from limit M, N 等陳述句執行效率非常低,資料量較大時存在很嚴重的問題,但是按主鍵或索引列查詢,則很快,如以下查詢就非常慢(假設 id 為主索引)
select id from db.tablea where id >100 limit 10 ;而以下查詢就很快:
select id from db.tablea where id >100 and id<150; -
如果虛擬虛擬表中欄位未建立索引,而物體表中為此欄位建立了索引,此種情況下,性能也相當差,但是當給虛擬表建立索引后,性能恢復正常,
-
類似 where name like "str%" limit 1 的查詢,即使在 name 列上創建了索引,也會導致查詢過慢,是因為federated引擎會將所有滿足條件的記錄讀取到本地,再進行 limit 處理,
場景: dblink,
-
1.2 存盤引擎的選擇
| 功能 | MYISAM | Memory | InnoDB | Archive |
|---|---|---|---|---|
| 存盤限制 | 256TB | RAM | 64TB | None |
| 支持事務 | No | No | Yes | No |
| 支持全文索引 | Yes | No | No | No |
| 支持數索引 | Yes | Yes | Yes | No |
| 支持哈希索引 | No | Yes | No | No |
| 支持資料快取 | No | N/A | Yes | No |
| 支持外鍵 | No | No | Yes | No |
二、MySQL基本資料型別
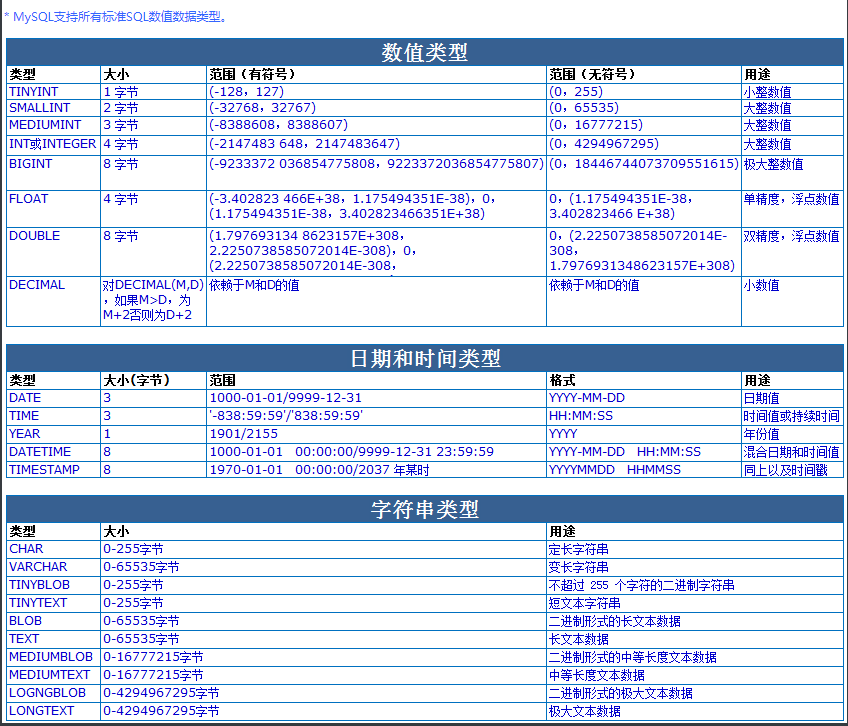
2.1 整形
不同的int型別能夠存盤的數字范圍是不一樣的,
-
要注意是否存負數(正負號需要占一個位元位)
-
針對手機號碼只能用bigint
'''研究默認是否需要正負號'''
create table t5(id tinyint);
insert into t5 values(-999),(999);
'''結論:所有的int型別默認都需要正負號'''
create table t6(id tinyint unsigned); # 移除正負號
insert into t6 values(-999),(999);
2.2 浮點型
float(255,30) """總共255位 小數位占30位"""
double(255,30) """總共255位 小數位占30位"""
decimal(65,30) """總共65位 小數位占30位"""
"""研究三者的不同"""
create table tb7(id float(255,30));
create table tb8(id double(255,30));
create table tb9(id decimal(65,30));
insert into tb7 values(1.11111111111111111111111);
insert into tb8 values(1.11111111111111111111111);
insert into tb9 values(1.11111111111111111111111);
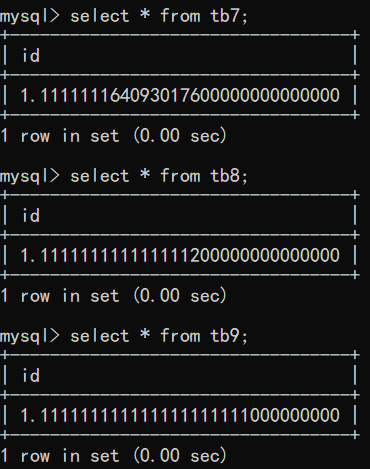
"""結論:三者的精確度不一樣"""
float < double < decimal
一般情況下小數點后面只保留兩位 所以float足矣;如果是從事高精密業務,則需要考慮更高的精確度,
ps:有時候很多看似需要用數字存盤的資料,可能都是存的字串,
2.3 字符型別
char(4):
定長型別 最多只能存四個字符 多了報錯少了自動空格填充至四個
varchar(4):
變長型別 最多只能存四個字符 多了報錯少了有幾個則存幾個
"""研究定長與變長特性"""
create table t10(id int,name char(4));
create table t11(id int,name varchar(4));
insert into t10 values(1,'jason');
insert into t11 values(1,'jason');
"""5.6版本以后超出范圍不會報錯,而是自動幫你截取并保存(此行為不合理)"""
方式1:命令修改(暫時)
show variables like '%mode%'; '''查看當前sql_mode'''
set session '''當前視窗有效'''
set global '''當前服務端有效'''
set global sql_mode = 'strict_trans_tables';
'''修改完畢后退出客戶端重新進入即可'''
'''再次執行上述插入命令 會直接報錯'''
方式2:修改組態檔(永久)
'''添加如下陳述句'''
[mysqld]
sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
'''統計某個欄位資料的長度 char_length()'''
insert into t10 values(2,'j');
insert into t11 values(2,'t');
'''底層確實會填充 但是取出來的時候又會自動去除'''
set global sql_mode = 'strict_trans_tables,pad_char_to_full_length';
select char_length(name) from tb10;
select char_length(name) from tb11;
2.4 char與varchar的對比
-
char優勢:整存整取,速度快
劣勢:浪費存盤空間
-
varchar優勢:節省存盤空間
劣勢:存取資料的速度較于char稍慢
補充:在創建欄位的時候可以加上相應的注釋
create table tb12(
id int comment '序號',
name char(4) comment '姓名'
);
2.5 整形中括號內數字的作用
create table t13(id int(3));
insert into t13 values(4444444); '''正常顯示'''
在整型中括號內的數字并不是用來限制存盤的長度,而是用來控制展示的長度,需搭配約束條件(如:zerofill)一起使用,
我們以后在定義整型欄位的時候,基本不需要自己添加數字,使用默認的即可,
create table t14(id int(3) zerofill);
insert into t13 values(4); '''顯示004'''
"""結論:整型比較特殊 是唯一個括號內的數字不是用來限制存盤長度的型別"""
2.6 列舉與集合型別
-
列舉:
enum(),多選一create table user1( id int, name varchar(32), gender enum('male','female','others') ); insert into user1 values(1,'jason','男'); '''報錯''' insert into user1 values(1,'jason','male'); '''正常''' -
集合:
set(),多選多(包含了多選一)create table user2( id int, name char(16), hobby set('basketball','football','doublecolorball') ); insert into user2 values(1,'jason','basketball'); insert into user2 values(2,'kevin','football,doublecolorball');
2.7 日期型別
date 年月日
datetime 年月日時分秒
time 時分秒
year 年份
create table client(
id int,
name varchar(32),
reg_time date,
birth datetime,
study_time time,
join_time year
);
insert into client values(1,'jason','2000-11-11','2000-1-21 11:11:11','11:11:11',1995);
三、創建表
3.1 創建表的完整語法
create table 表名(
欄位名1 欄位型別(數字) 約束條件,
欄位名2 欄位型別(數字) 約束條件,
欄位名3 欄位型別(數字) 約束條件
);
- 欄位名和欄位型別是必須的
- 數字和約束條件是可選的,并且約束條件可以有多個,使用空格隔開即可
- 最后一個陳述句的結尾不要加逗號
,
3.2 約束條件
約束條件相當于是在欄位型別的基礎之上添加的額外約束
-
unsigned:讓數字型別變為只允許正數create table tb1(id int unsigned); -
zerofill:資料所占位數不夠時,多余的位數用數字0填充create table tb2(id int(4) zerofill); -
not null:非空;create table tb3( id int, name varchar(32) not null );補充:新增表資料的方式
-
方式1:按照欄位順序一一傳值
insert into tb3 values(1,'jason'); -
方式2:自定義傳值順序,也可以不傳
insert into tb3(name,id) values('jason',1); insert into tb3(id) values(1);
默認情況下,在MySQL中不傳資料,會使用關鍵字NULL填充,意思就是空 類似于Python中的None,
-
-
default:默認值所有的欄位都可以設定默認值,如果用戶沒有給該欄位傳值則使用默認值,否則使用所傳的值,
create table tb4( id int default 911, name varchar(16) default 'jason' ); -
unique:唯一值-
單列唯一
create table tb5( id int, name varchar(32) unique ); -
聯合唯一
create table tb5( id int, host varchar(32), port int, unique(host,port) );
-
-
primary key:主鍵單從約束層面上來說,相當于是
not null + unique(非空且唯一),并且在此基礎上還可以加快資料的查詢,InnoDB存盤引擎規定了一張表必須有且只有一個主鍵,因為InnoDB是通過主鍵的方式來構造表的,
如果沒有設定主鍵,會分為兩種情況,如下:
-
情況1:沒有主鍵和其他約束條件
InnoDB會為每一行生成一個6位元組的ROWID,并以此作為主鍵,
-
情況2:沒有主鍵但是有非空且唯一的欄位
自動將該欄位升級為主鍵:
create table tb6( id int, age int not null unique, '''從上到下選取第一個非空唯一欄位作為主鍵''' pwd int not null unique );
結論:
以后我們在創建表的時候一定要設定主鍵,并且主鍵欄位一般都設定為表的id欄位(uid、sid、pid、cid ...)
create table user( id int primary key, name varchar(32) ); -
-
auto_increment:自增由于主鍵類似于資料的唯一標識,并且主鍵一般都是數字型別,
我們在添加資料的時候不可能記住接下來的序號的是多少,這樣很麻煩,所以使用
auto_increment可以幫助我們實作主鍵欄位的自增,create table user1( id int primary key auto_increment, name varchar(32) );需要注意的一點是自增的特性:
自增不會因為洗掉資料等操作而回退(delete from無法影響自增)
如果想要重置需要使用truncate關鍵字:
truncate 表名 '''清空表資料并且重置主鍵值'''
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/427462.html
標籤:MySQL