這是我的代碼:
import glob
import itertools
import sys, os
import six
import csv
import numpy as np
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdftypes import resolve1
os.chdir("PATH/pdf")
extension = 'pdf'
all_filenames = [i for i in glob.glob('*.{}'.format(extension))]
valeur = []
n = 1
for i in all_filenames:
fp = open(i, "rb")
parser = PDFParser(fp)
doc = PDFDocument(parser)
fields = resolve1(doc.catalog["AcroForm"])["Fields"]
for i in fields:
field = resolve1(i)
name, value = field.get("T"), field.get("V")
filehehe = "{0}:{1}".format(name,value)
values = resolve1(value)
names = resolve1(name)
valeur.append(values)
n = n 1
with open('test.csv','wb') as f:
for i in valeur:
f.write(i)
這里的目標是在 PDF 中獲取一些資訊。這是輸出:
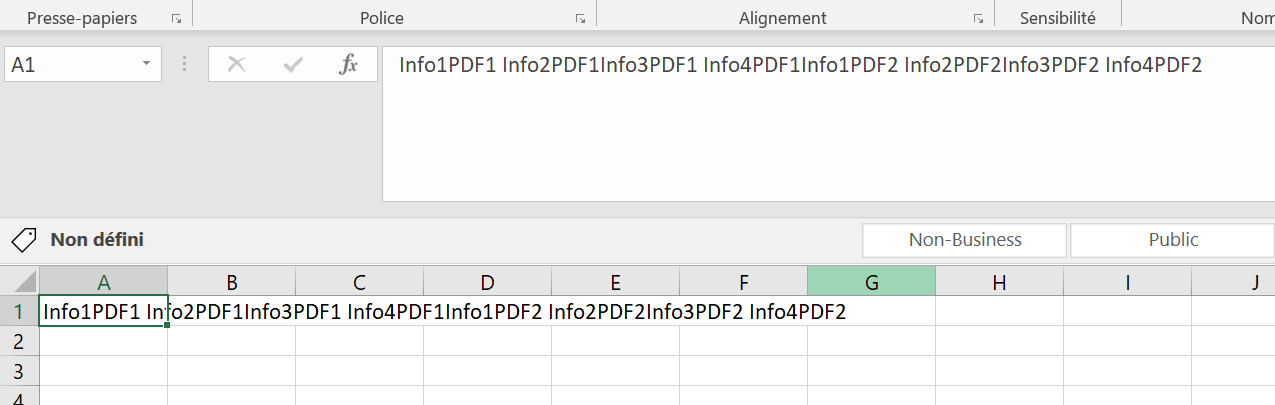
如您所見,格式并不漂亮。我不是很熟悉,open()所以我有點卡住了。
我希望每個 PDF 都有不同的行,每個資訊都有自己的單元格。類似的東西:
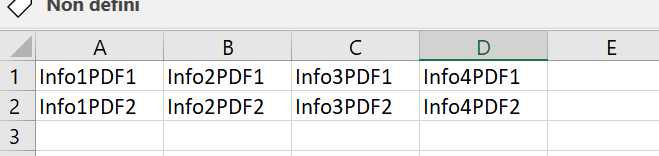
uj5u.com熱心網友回復:
- 嘗試將每個 pdf 檔案中的資料存盤在單獨的串列中。并將此串列添加到
valeur您擁有的串列中。 - 正確建議使用
csv模塊作為@martineau。
您可以嘗試使用以下代碼。
import csv
valeur = []
#your code
n = 1
for i in all_filenames:
temp_list = []
fp = open(i, "rb")
parser = PDFParser(fp)
doc = PDFDocument(parser)
fields = resolve1(doc.catalog["AcroForm"])["Fields"]
for i in fields:
field = resolve1(i)
name, value = field.get("T"), field.get("V")
filehehe = "{0}:{1}".format(name,value)
values = resolve1(value)
names = resolve1(name)
temp_list.append(values)
n = n 1
valeur.append(temp_list)
#Finally when you have the required data, you can write to csv file like this.
with open('mycsv.csv', 'w', newline='') as myfile:
wr = csv.writer(myfile, quoting=csv.QUOTE_ALL)
for val in valeur:
wr.writerow(val)
有了這個,輸出將是這樣的
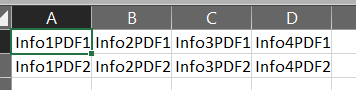
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/428830.html