WAL機制
Write-Ahead Logging,預寫日志系統即當有資料更新請求的時候,先寫日志,再改記憶體,等“有空”的時候再落磁盤(刷臟頁),WAL機制的好處,因為寫日志是磁盤順序IO,而直接寫磁盤是隨機IO,性能較差,
binlog
MySQL server層自己的歸檔日志叫做binlog (binary log),binlog會記錄所有邏輯操作,采用“追加寫”的方式,log不會被覆寫,
binlog的三種格式
binlog有三種格式(binlog_format),一種叫statement, 一種叫row, 第三種叫mixed, 是前兩種的混合,舉個栗子??:
delete from t where code<=2 and create_time <= '2022-2-18' limit 1
如果binlog是statement的形式,binlog將記錄SQL原文:

(ps 但是這條陳述句會產生一個warning,因為binlog設定為statement格式,陳述句有limit可能是unsafe的, 至于原因這里暫時不討論,可以看鏈接)
如果binlog是row的形式,binlog不是記錄SQL的原文而是替換成了兩個event,table_map和delete_rows:
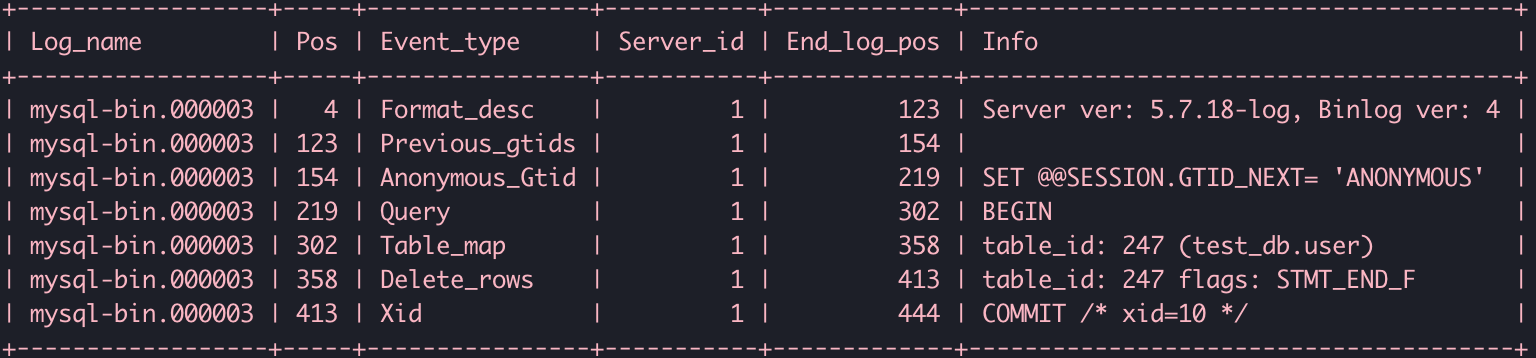
binlog的使用場景
- 主從復制
- 資料恢復
如何將資料庫恢復到之前的某個時刻?
找到這個時刻之前最近的一次全量備份,再從備份的時間點開始把binlog依次取出來,重放到需要恢復的那個時刻,
binlog的落盤時機
根據引數sync_binlog來控制:
| 引數值 | 含義 |
|---|---|
| 0 | 不控制binlog重繪,由檔案系統控制它快取落盤,風險較大,一旦crash, 會有binlog丟失的問題 |
| 1 | 每次事務提交都會刷盤到磁盤,最安全但是性能最差, |
| N | 每N次事務提交才會刷盤到磁盤 |
redo log
上面說binlog記錄的是所有邏輯操作,且是server層面實作的,而redo log 記錄的是資料頁中的真實二進制資料,是在InnoDB存盤引擎層面實作的,
redo log 包含兩部分,一個是日志緩沖區(redo log buffer),一個是磁盤上的日志檔案(redo log file),InnoDB的redo log是固定大小,配置為一組4個檔案,每個檔案1GB,機制是回圈寫,write pos記錄當前從哪里開始寫,寫之后就向后移動,check point記錄可以寫到哪個位置,從write pos到check point的區間(綠色部分)就是可以寫日志的區域,如下圖:
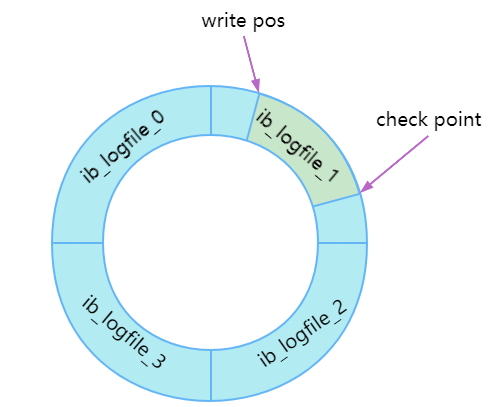
既然叫check point,那何時去check呢?(=什么時候刷臟頁/flush?=什么時候算WAL中提到的“有空”)
臟頁的落盤時機
- 第一直覺上來說,如果redo log寫滿了,也就是說write pos追上check point了,那必須要刷臟頁,把check point往后推,否則系統就無法處理更新了,
- 第二個就是寫記憶體的時候,發現記憶體不夠用了,需要釋放掉一些記憶體,在存盤部分提到過,記憶體里的要么是空頁,要么是干凈頁,要么是臟頁,如果是干凈頁,就可以直接釋放,如果是臟頁就必須要先落盤flush
- “有空”自然是說系統較為空閑的時候,因為WAL機制本身就是為了提高系統的性能,減少隨機IO帶來的性能損耗,如果系統負載很小,完全handle得過來,那就刷下臟頁吧
- MySQL需要關閉以前,那自然是要把資料落到磁盤上,
刷臟頁的能力
可以通過innodb_io_capacity引數告訴InnoDB這個磁盤的能力,一般是設定為磁盤的IOPS(Input/Output Per Second),InnoDB會根據這個引數和當前記憶體的臟頁比例以及redo log的落盤四度決定刷臟頁的速度,
除此之外,刷臟頁還有個特點就是“連坐”,如果當前需要被刷的這個臟頁的鄰居頁也是臟頁,那也會被一起刷到磁盤,可以通過設定innodb_flush_neighbors引數為0來避免,
redo log的落盤時機
前面說的刷臟頁,其實是把記憶體的最新資料更新到磁盤上,而上面也說了redo log其實也有快取和磁盤檔案,那redo log什么時候把快取給落盤呢?
首先,我們要知道計算機作業系統的用戶空間的緩沖區資料,要經過內核空間,由系統呼叫fsync()寫到磁盤上,如下圖:
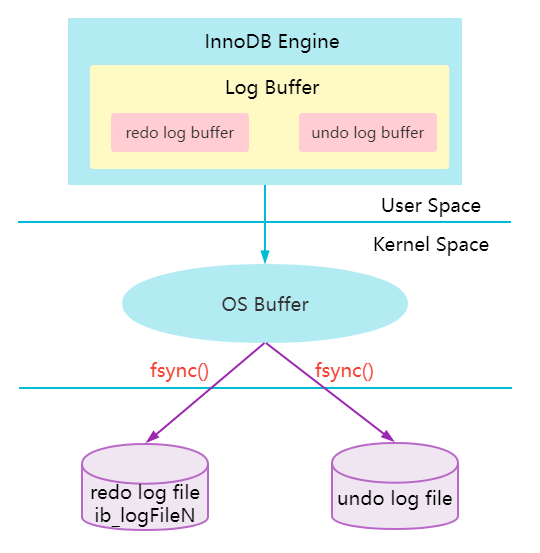
可以通過innodb_flush_log_at_trx_commit引數來配置這個redo log的落盤時機:
| 引數值 | 含義 |
|---|---|
| 0(延遲寫) | 事務提交時,不會將 redo log buffer中的日志寫入os buffer; 而是每秒寫入os buffer并呼叫fsync()寫入redo log file中,也就是說當系統崩潰,會丟失1s的資料 |
| 1(實時寫,實時刷) | 事務提交時,都會將redo log buffer中的日志寫入os buffer并呼叫fsync()刷到redo log file中,這種方式不會丟失任何資料,但是IO性能相對來說比較差 |
| 2(實時寫,延遲刷) | 事務提交時,都會寫入os buffer,但是每秒呼叫fsync()將os buffer中的日志寫入redo log file |
redo log的使用場景
InnoDB通過redo log來實作事務,同時保證資料庫即使發生例外重啟,之前提交的記錄都不會丟失,沒有提交的事務資料自動回滾,這個能力就叫做crash-safe,
redo log & binlog
| 比較項 | redo log | binlog |
|---|---|---|
| 記錄的內容 | 物理日志,記錄的是對XX表空間的XX資料頁XX偏移量的地方做了XX更新, 恢復速度快 | 邏輯日志,如真實的SQL陳述句,如對XX表條件為XX的資料做了什么修改,需要逐條執行,恢復速度慢 |
| 記錄的方式 | 回圈寫 | 追加寫 |
| 用途 | 重做資料頁 | 主從復制,資料備份 |
| 層級 | innodb存盤引擎提供 | mysql server層提供 |
為什么要兩個日志,一個不行嗎?
redo log是InnoDB提供的,MySQL很早之前還沒有InnoDB這個東西,都是用binlog來歸檔的,但是單獨的binlog不能提供crash-safe的能力,
兩階段提交
一條更新陳述句,到底是怎樣執行的呢?例如update t set number=number+1 where id=1
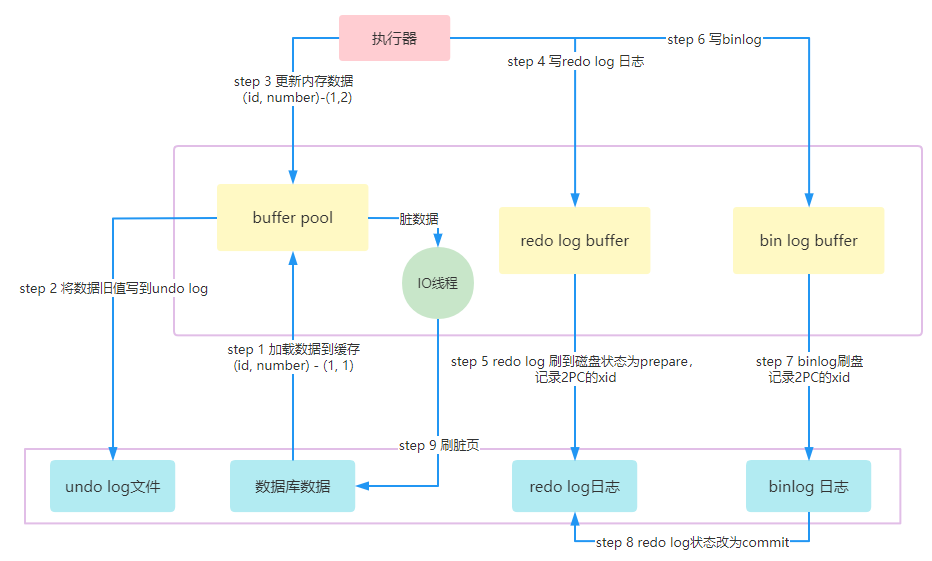
兩階段提交即將寫入redo log這個操作,拆成了寫prepare和寫commit,由此可以保證redo log和binlog的邏輯一致性,避免主從復制時產生資料不一致的問題,
試想先寫redo log再寫binlog或者先寫binlog再寫redo log會有什么問題:
- 先寫redo log, 此時MySQL(master)崩潰(沒來得及刷臟頁),那么binlog里面這條資料還是原來的,MySQL(master)重啟,會根據redo log來重放,那么此時master的資料是更新過后的,而從節點通過binlog去做復制的時候,這條資料就是老的,主比從多了一次資料更新,
- 先寫bin log, 此時MySQL(master)崩潰,那么redo log里面這條資料是舊的,MySQL(master)重啟,根據redo log來重放,那么此時master的資料是原來的,而從節點通過binlog去做復制的時候,這條資料就是新的,從比主多了一次資料更新,
但兩階段提交就不會有這個問題:
- 如果寫入了redo log - prepare, MySQL崩潰,此時binlog啥也沒有,MySQL重啟,根據redo log重放的時候發現redo log是prepare但是binlog啥也沒有,那就回滾,從節點根據binlog復制,不會有這條記錄;master回滾了,也不會有這條記錄,
- 如果寫入了redo log -prepare, 寫入了binlog, MySQL崩潰,此時binlog是有資料的,MySQL重啟,根據redo log重放的時候發現redo log是prepare但是binlog有對應的記錄,那就提交,從節點根據binlog復制,會有這條記錄;master提交了,也會有這條記錄
- 如果寫入了redo log-prepare,寫入了binlog, 寫入了redo log-commit過后,MySQL崩潰了,MySQL重啟,就按部就班重放redo log就行了,啥也不用做,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/431445.html
標籤:MySQL