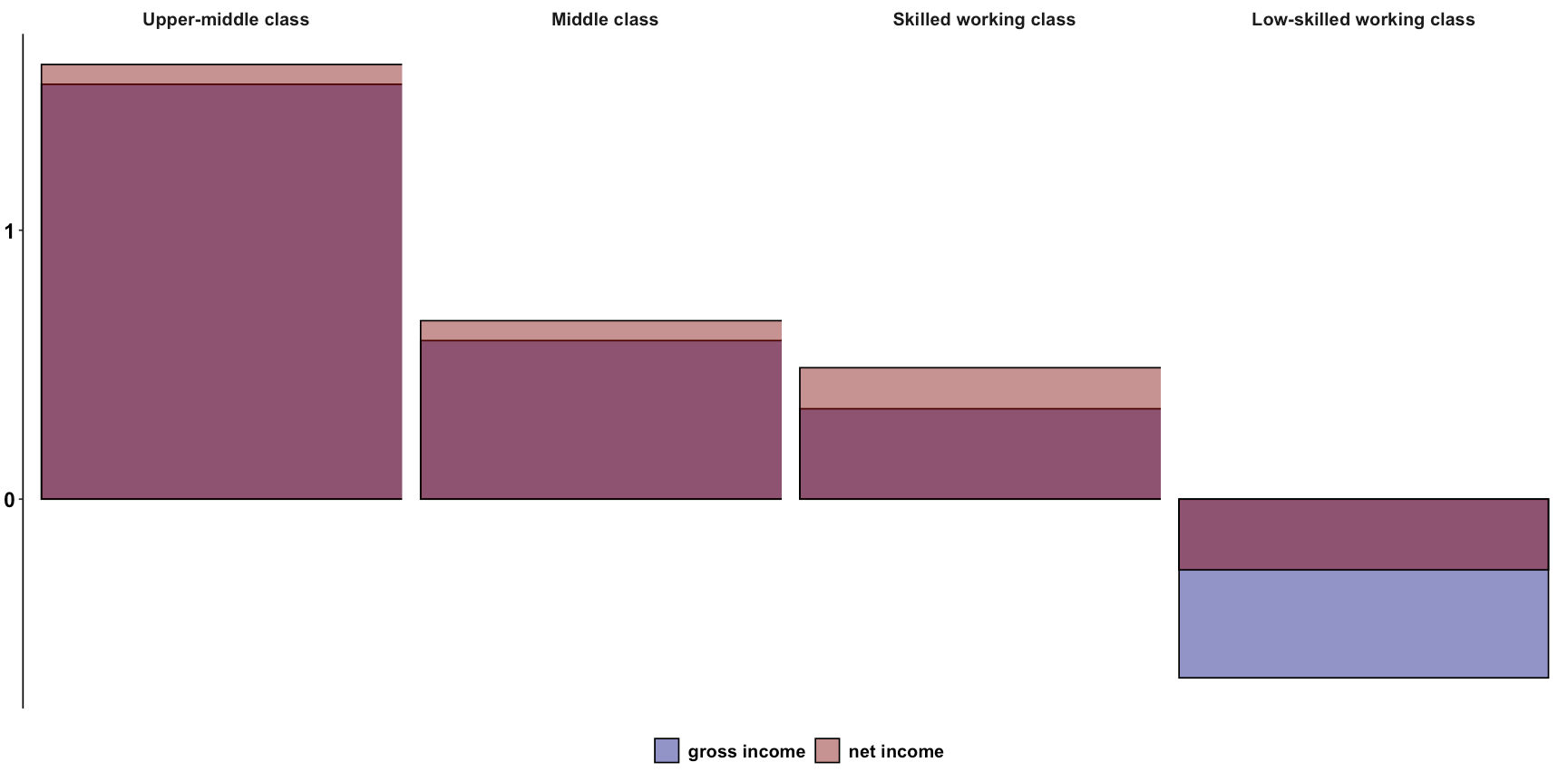
我在下面畫了這張圖,我想展示不同社會階層的總收入和凈收入之間的年增長率差異。正如你所看到的,當總收入和凈收入走向不同的方向時,就像低技能工人階級的情況一樣,顏色與圖例相匹配。但是,如果年增長率與前三個柱的情況相同,那么我們會看到增長收入為紅色,而凈收入為橙色。有沒有辦法讓顏色保持對比,就像右邊最后一列一樣,即使它們重疊?
這是圖表:
這是代碼的簡化版本:
ggplot(df, aes(x=year, y=annual_chg, fill=income,color=income))
geom_col(position = "identity", alpha = 1/2,colour= "black")
facet_wrap(~Class,nrow=1)
theme_classic() xlab(NULL) ylab(NULL)
scale_color_manual(values = c("blue4","red4"))
scale_fill_manual(values=c("blue4","red4"))
這是資料:
df= structure(list(year = c(2018, 2018, 2018, 2018, 2018, 2018, 2018,
2018), annual_chg = c(-0.66, 0.34, 0.59, 1.54, -0.26, 0.49, 0.66,
1.62), Class = structure(c(4L, 3L, 2L, 1L, 4L, 3L, 2L, 1L), .Label = c("Upper-middle class",
"Middle class", "Skilled working class", "Low-skilled working class"
), class = "factor"), income = c("gross income", "gross income",
"gross income", "gross income", "net income", "net income", "net income",
"net income")), row.names = c(NA, -8L), class = c("tbl_df", "tbl",
"data.frame"))
uj5u.com熱心網友回復:
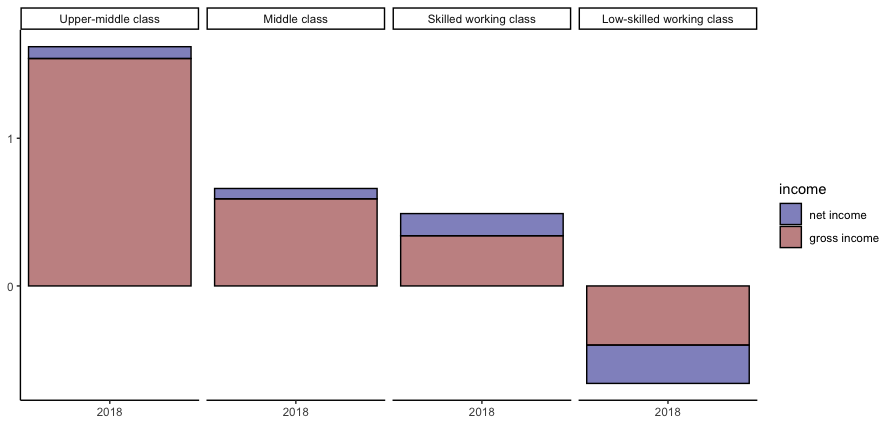
聽起來您想修改資料,以便當我們看到相對較大的值時,應該繪制增量,而不是與它取代的較小值重疊的部分。
我會通過首先預處理資料來找到增量來做到這一點,這樣我們就可以繪制這些而不是原始值。
library(dplyr); library(forcats); library(ggplot2)
df %>%
group_by(Class, year) %>%
arrange(abs(annual_chg)) %>%
mutate(increm = annual_chg - lag(annual_chg, default = 0)) %>%
mutate(income = forcats::fct_rev(income)) %>%
ungroup() %>%
ggplot(aes(x=year, y=increm, fill=income, color=income))
geom_col(position = "stack", alpha = 1/2, color = "black")
facet_wrap(~Class,nrow=1)
theme_classic() xlab(NULL) ylab(NULL)
scale_x_continuous(breaks = scales::breaks_width(1))
scale_color_manual(values = c("blue4","red4"))
scale_fill_manual(values=c("blue4","red4"))
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/431990.html