前言
VACUUM 是 PostgreSQL MVCC (Multiversion concurrency control) 實作的核心機制之一,是 PostgreSQL 正常運行的重要保證,本文將通過實體演示 PostgreSQL 為什么需要做 VACUUM,以及一步一步精準觸發 AUTOVACUUM, 到 VACUUM 優化實戰,深入淺出,一看就懂,
測驗環境準備
以下測驗是在 PostgreSQL 11 中進行,
通過以下 SQL 創建:
測驗用戶: alvin,普通用戶,非 superuser
測驗資料庫: alvindb,owner 是 alvin
測驗 schema: alvin,owner 也是 alvin
這里采用的是 user 與 schema 同名,結合默認的 search_path("$user", public),這樣操作物件(table, sequence, etc.)時就不需要加 schema 前綴了,
postgres=# CREATE USER alvin WITH PASSWORD 'alvin';
CREATE ROLE
postgres=# CREATE DATABASE alvindb OWNER alvin;
CREATE DATABASE
postgres=# \c alvindb
You are now connected to database "alvindb" as user "postgres".
alvindb=# CREATE SCHEMA alvin AUTHORIZATION alvin;
CREATE SCHEMA
alvindb=# \c alvindb alvin
You are now connected to database "alvindb" as user "alvin".
alvindb=> SHOW search_path;
search_path
-----------------
"$user", public
(1 row)
PostgreSQL 為什么需要做 VACUUM
這要從 PostgreSQL MVCC UPDATE/DELETE 實作講起,
下面通過簡單演示 PostgreSQL 中 UPDATE/DELETE 時底層資料變化,揭秘其 MVCC 設計的藝術,
為了方便看其底層資料,通過 superuser postgres 創建 extension pageinspect:
$ psql -d alvindb -U postgres
alvindb=# CREATE EXTENSION IF NOT EXISTS pageinspect;
CREATE EXTENSION
alvindb=# \dx pageinspect
List of installed extensions
Name | Version | Schema | Description
-------------+---------+--------+-------------------------------------------------------
pageinspect | 1.7 | public | inspect the contents of database pages at a low level
(1 row)
首先,創建測驗表
$ psql -d alvindb -U alvin
alvindb=>
CREATE TABLE tb_test_vacuum (
test_id BIGSERIAL PRIMARY KEY,
test_num BIGINT
);
CREATE TABLE
插入 3 條測驗資料
alvindb=> INSERT INTO tb_test_vacuum(test_num) SELECT gid FROM generate_series(1,3,1) gid;
INSERT 0 3
alvindb=> SELECT * FROM tb_test_vacuum ORDER BY 1 DESC LIMIT 5;
test_id | test_num
---------+----------
3 | 3
2 | 2
1 | 1
(3 rows)
查看其底層資料,
alvindb=> SELECT * FROM heap_page_items(get_raw_page('alvin.tb_test_vacuum', 0)) LIMIT 10;
ERROR: must be superuser to use raw functions
可以看到底層資料只有 superuser 才可以查看,這里另打開一個視窗,用 superuser 用戶 postgres 查看,
psql -d alvindb -U postgres
alvindb=# SELECT * FROM heap_page_items(get_raw_page('alvin.tb_test_vacuum', 0)) LIMIT 10;

這里 t_xmin 為其插入時 transaction id,
下面洗掉 2 條資料:
alvindb=> DELETE FROM tb_test_vacuum WHERE test_id = 2;
DELETE 1
alvindb=> DELETE FROM tb_test_vacuum WHERE test_id = 3;
DELETE 1
alvindb=> SELECT * FROM tb_test_vacuum ORDER BY 1 DESC LIMIT 5;
test_id | test_num
---------+----------
1 | 1
(1 row)
此時在第二個視窗再看其底層資料
alvindb=> SELECT * FROM heap_page_items(get_raw_page('alvin.tb_test_vacuum', 0)) LIMIT 10;

這時你會發現,實際資料并未被洗掉,只是修改了 t_xmax,t_infomask2 和 t_infomask,t_xmax 為洗掉時的 transaction id,t_infomask2 和 t_infomask 為各種標志位,這里顯示的是其二進制轉換后的十進制,
為什么不直接物理洗掉資料呢?
主要是出于以下考慮:
這些被洗掉的資料可能還在被其他事務訪問,所以不能直接洗掉,這就是所謂的 MVCC 中的 multi version,即多版本,不同事務訪問的可能是不同版本的資料,transaction id 可以理解為版本號,其他事務可能還在訪問 t_xmax 為 15400741 或 15400742 的資料,
為什么有的其他資料庫 MVCC 實作底層資料就不是這樣呢?
Oracle 中將要洗掉資料轉移到了 UNDO tablespace 中,供其他事務訪問,以實作 MVCC,
PostgreSQL 為什么這么實作呢?
大家可以想一下,“轉移資料” 與 “改標志位”,哪個 cost 高呢?當然是 “改標志位” 既簡單又高效了!可見 PostgreSQL 設計之巧妙,
另外,PostgreSQL 這樣做還有一個好處,
Oracle DBA 都非常熟悉 ORA-01555: snapshot too old,其原因是 UNDO tablespace 大小畢竟是有限的,存盤的老版本資料也是有限的,Oracle 中解決 snapshot too old 一個辦法就是增大 UNDO tablespace,PostgreSQL 中這樣保留老版本資料,可以說磁盤有多大,“UNDO tablespace” 就有多大,就不會出現類似類似 snapshot too old 這樣的問題,
但凡事都有兩面性,
PostgreSQL 中這樣保留老版本資料有什么弊端呢?
老版本的資料是可能有其他事務需要訪問,但隨著時間的推移,這些事務終將結束,對應老版本的資料終將不被需要,它們將不斷占用甚至耗盡磁盤空間,使資料訪問變得很慢,這就是 PostgreSQL 中的 Bloat ,即膨脹,
PostgreSQL 中的 bloat 問題如何解決呢?
就是 VACUUM,可以理解為“回收空間”,
現在對表 alvin.tb_test_vacuum 進行 VACUUM 操作,
alvindb=> VACUUM VERBOSE tb_test_vacuum;
INFO: vacuuming "alvin.tb_test_vacuum"
INFO: scanned index "tb_test_vacuum_pkey" to remove 2 row versions
DETAIL: CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s
INFO: "tb_test_vacuum": removed 2 row versions in 1 pages
DETAIL: CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s
INFO: index "tb_test_vacuum_pkey" now contains 1 row versions in 2 pages
DETAIL: 2 index row versions were removed.
0 index pages have been deleted, 0 are currently reusable.
CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s.
INFO: "tb_test_vacuum": found 2 removable, 1 nonremovable row versions in 1 out of 1 pages
DETAIL: 0 dead row versions cannot be removed yet, oldest xmin: 15400744
There were 0 unused item pointers.
Skipped 0 pages due to buffer pins, 0 frozen pages.
0 pages are entirely empty.
CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s.
VACUUM
可以看到,VACUUM 不僅針對表資料,還包括索引,即不僅表資料可造成 Bloat (膨脹),索引也會,
pageinspect extension 除了可以用 heap_page_items 看底層資料,也可以通過 bt_page_items 看其索引底層資料,在此不再查看索引底層資料,感興趣可以執行如下 function 自行測驗,
SELECT * FROM bt_page_items('index_name', 1);
在第二個視窗重新查看表底層資料:
psql -d alvindb -U postgres
alvindb=# SELECT * FROM heap_page_items(get_raw_page('alvin.tb_test_vacuum', 0)) LIMIT 10;

可以看到,老版本資料已被清除,此時回收的空間新插入的資料使用,但并未回傳給作業系統,
如何將回收的空間真正回傳給作業系統呢?
就是 VACUUM FULL 操作:
alvindb=> VACUUM FULL VERBOSE tb_test_vacuum;
INFO: vacuuming "alvin.tb_test_vacuum"
INFO: "tb_test_vacuum": found 0 removable, 1 nonremovable row versions in 1 pages
DETAIL: 0 dead row versions cannot be removed yet.
CPU: user: 0.01 s, system: 0.01 s, elapsed: 0.08 s.
VACUUM
在第二個視窗查看表底層資料:
psql -d alvindb -U postgres
alvindb=# SELECT * FROM heap_page_items(get_raw_page('alvin.tb_test_vacuum', 0)) LIMIT 10;

可以看到,老版本資料已徹底回收了,
但要注意,生產環境需要謹慎使用 VACUUM FULL,因為它將在表上加 ACCESS EXCLUSIVE 鎖,即連 SELECT 也不可以,除非應用端可以計劃不訪問該表,
上面通過 DELETE 演示了為什么需要做 VACUUM,
那么 UPDATE 在 PostgreSQL 中是如何實作的呢?它會不會產生 Bloat (膨脹) 呢?
執行 UPDATE 操作如下:
alvindb=> UPDATE tb_test_vacuum SET test_num = 1 WHERE test_id = 1;
UPDATE 1
在第二個視窗查看表底層資料:
psql -d alvindb -U postgres
alvindb=# SELECT * FROM heap_page_items(get_raw_page('alvin.tb_test_vacuum', 0)) LIMIT 10;

可以看到,UPDATE 其實是 DELETE + INSERT,
為什么 PostgreSQL 如此實作 UPDATE 呢?
是因為 DELETE + INSERT 執行效率高?直接修改原資料不可以么?
因為老版本資料有可能還被其他事務需要!這是 MVCC 實作所需要的,
當然,相比 Oracle 中將老版本資料轉移到 UNDO tablespace, DELETE + INSERT 中的 DELETE 減少了 I/O,因為其只修改了標志位而已,
那么只有 UPDATE 和 DELETE 會產生 Bloat (膨脹) 嗎? INSERT 會嗎?
INSERT 不是只插入資料嗎?它怎么會產生 Bloat (膨脹) 呢?
接下來看下面的 case,
在事務中,ROLLBACK INSERT 的資料:
alvindb=> TRUNCATE tb_test_vacuum;
TRUNCATE TABLE
alvindb=> INSERT INTO tb_test_vacuum(test_num) SELECT gid FROM generate_series(1,1,1) gid;
INSERT 0 1
alvindb=> BEGIN;
BEGIN
alvindb=> INSERT INTO tb_test_vacuum(test_num) SELECT gid FROM generate_series(2,3,1) gid;
INSERT 0 2
alvindb=> ROLLBACK;
ROLLBACK
alvindb=> SELECT * FROM tb_test_vacuum ORDER BY 1 DESC LIMIT 5;
test_id | test_num
---------+----------
8 | 1
(1 row)
在第二個視窗查看表底層資料:
psql -d alvindb -U postgres
alvindb=# SELECT * FROM heap_page_items(get_raw_page('alvin.tb_test_vacuum', 0)) LIMIT 10;

可以看到,在事務中,PostgreSQL 中 ROLLBACK 時并未洗掉已 INSERT 的資料,
進一步測驗 ROLLBACK UPDATE,
alvindb=> TRUNCATE tb_test_vacuum;
TRUNCATE TABLE
alvindb=> INSERT INTO tb_test_vacuum(test_num) SELECT gid FROM generate_series(1,1,1) gid;
INSERT 0 1
alvindb=> BEGIN;
BEGIN
alvindb=> SELECT * FROM tb_test_vacuum ORDER BY 1 DESC LIMIT 5;
test_id | test_num
---------+----------
12 | 1
(1 row)
alvindb=> UPDATE tb_test_vacuum SET test_num = test_num + 1 WHERE test_id = 12;
UPDATE 1
alvindb=> SELECT clock_timestamp();
clock_timestamp
-------------------------------
2021-11-14 18:25:11.651518+08
(1 row)
此時在第二個視窗查看表底層資料:

接下來在第一個視窗 ROLLBACK:
alvindb=> ROLLBACK;
ROLLBACK
alvindb=> SELECT clock_timestamp();
clock_timestamp
-------------------------------
2021-11-14 18:25:35.948455+08
(1 row)
alvindb=> SELECT * FROM tb_test_vacuum ORDER BY 1 DESC LIMIT 5;
test_id | test_num
---------+----------
12 | 1
(1 row)
再在第二個視窗查看表底層資料:
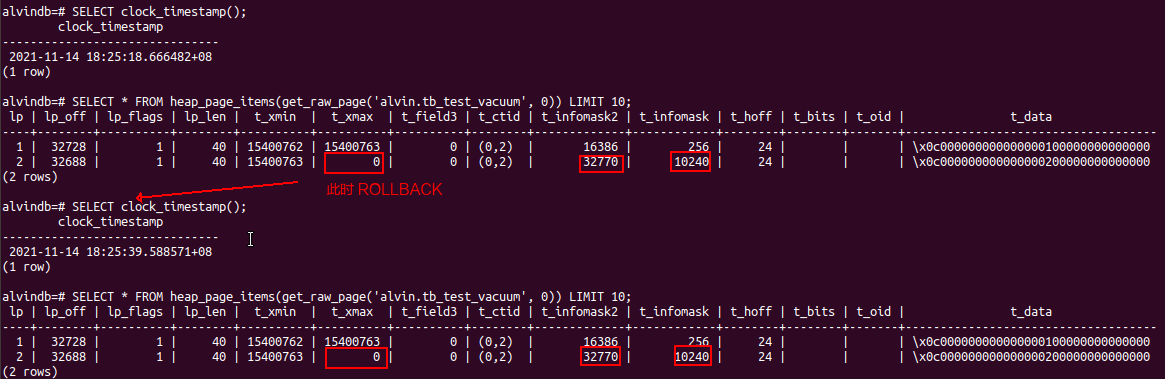
如果反復測驗會發現,如果 COMMIT,其會修改標志位;如果 ROLLBACK ,PostgreSQL 什么也不做,因為標志位未修改,其仍不可見,即使 t_xmax 為 0,
相比 Oracle 中的 UPDATE 先將老版本中資料轉移到 UNDO,ROLLBACK 再利用 UNDO 中原資料恢復,PostgreSQL 中的 ROLLBACK 避免了兩次不必要的 IO,既提高了性能,又節省了時間,
根據上面實驗,可以看到 UPDATE/DELETE/ROLLBACK 都有可能造成 Bloat (膨脹),如果頻繁更新的表長時間未做 VACUUM,VACUUM 完之后仍會占用很大空間,Bloat (膨脹) 仍然存在,生產又不能隨便做 VACUUM FULL 回收空間 ,
那么如何有效減少 Bloat (膨脹)?
在計劃內大量更新資料等情況,可以根據需要手動 VACUUM,這樣回收的空間可供下次大量更新資料使用,這樣可以有效減少 Bloat (膨脹),
VACUUM 除了回收空間,還有其他作用嗎?
transaction id (事務 id) 是 32 位的,即最多有 2 的 32 次方,即 4294967296 個事務 id,中國人口按 14 億算,一人也就能分配 3 個事務 id,所以 transaction id 范圍是非常有限的,那么 PostgreSQL 是如何解決這個問題的呢?
從下圖可以看出,PostgreSQL 是回圈利用 transaction id 的,這樣,transaction id 就無窮無盡的了,
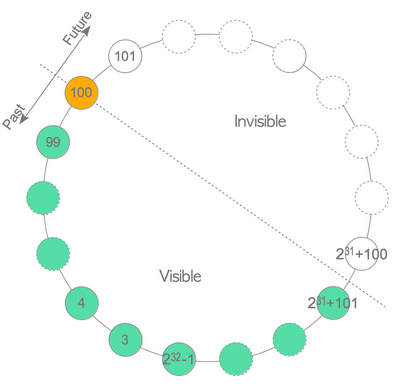
以當前 transaction id 是 100 為例,大于 100 的約 21 億 個事務對事務 100 不可見,小于 100 的約 21 億 個事務對事務 100 可見,如果 transaction id 一直沒有回收,直至 transaction id 耗盡,就會產生 wraparound (回卷) 問題,原來可見的突然變得不可見了,資料就“憑空消失”了,
那么 VACUUM 是如何回收 transaction id 的?是通過 FREEZE 對所有事務可見的資料,由于篇幅有限,且實際作業中基本不需要對 FREEZE 相關引數進行優化,FREEZE 將通過另外一篇文章單獨講述,本文不對 FREEZE 展開,
應用程式一般會有頻繁的更新,不斷造成 Bloat (膨脹) 及消耗 transaction id,總不能都手動 VACUUM 吧?
有沒有自動的方式呢?當然!
優質文章推薦
PostgreSQL VACUUM 之深入淺出
華山論劍之 PostgreSQL sequence
[PG Upgrade Series] Extract Epoch Trap
[PG Upgrade Series] Toast Dump Error
GitLab supports only PostgreSQL now
MySQL or PostgreSQL?
PostgreSQL hstore Insight
ReIndex 失敗原因調查
PG 資料匯入 Hive 亂碼問題調查
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/432056.html
標籤:其他
上一篇:iceberg合并小檔案沖突測驗