我有一個如下所示的資料框
df = pd.DataFrame(
{'stud_name' : ['ABC', 'ABC','ABC','DEF',
'DEF','DEF'],
'qty' : [123,31,490,518,70,900],
'trans_date' : ['13/11/2020','10/1/2018','11/11/2017','27/03/2016','13/05/2010','14/07/2008']})
我想做以下
a) 對于每個stud_name,查看他們過去的資料(完整的過去資料)并計算列的min,max和meanqty
請注意,每個唯一的第一條記錄/行將stud_name是NA因為沒有過去的資料(歷史)來查看和計算匯總統計資訊
我嘗試了類似下面的方法,但輸出不正確
df['trans_date'] = pd.to_datetime(df['trans_date'])
df.sort_values(by=['stud_name','trans_date'],inplace=True)
df['past_transactions'] = df.groupby('stud_name').cumcount()
df['past_max_qty'] = df.groupby('stud_name')['qty'].expanding().max().values
df['past_min_qty'] = df.groupby('stud_name')['qty'].expanding().min().values
df['past_avg_qty'] = df.groupby('stud_name')['qty'].expanding().mean().values
我希望我的輸出如下所示
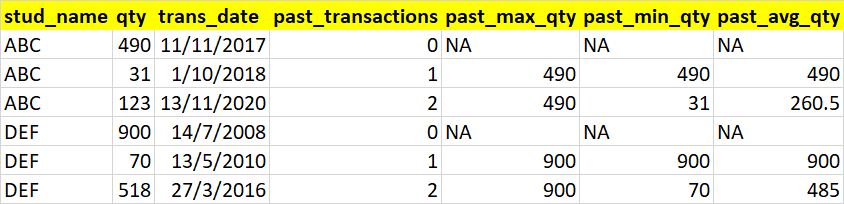
uj5u.com熱心網友回復:
我們可以使用自定義函式來計算每個學生過去的統計資料
def past_stats(q):
return (
q.expanding()
.agg(['max', 'min', 'mean'])
.shift().add_prefix('past_')
)
df.join(df.groupby('stud_name')['qty'].apply(past_stats))
stud_name qty trans_date past_max past_min past_mean
2 ABC 490 2017-11-11 NaN NaN NaN
1 ABC 31 2018-10-01 490.0 490.0 490.0
0 ABC 123 2020-11-13 490.0 31.0 260.5
5 DEF 900 2008-07-14 NaN NaN NaN
4 DEF 70 2010-05-13 900.0 900.0 900.0
3 DEF 518 2016-03-27 900.0 70.0 485.0
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/434037.html
標籤:Python 熊猫 数据框 熊猫-groupby 移动平均线