本文首發于 Nebula Graph Community 公眾號

1.圖計算介紹
1.1 圖資料庫 vs 圖計算
圖資料庫是面向 OLTP 場景,強調增刪改查,并且一個查詢往往只涉及到全圖中的少量資料,而圖計算是面向 OLAP 場景,往往是針對全圖資料進行分析計算,
1.2 圖計算系統分布架構
按照分布架構,圖計算系統分為單機和分布式,
單機圖計算系統優勢在于模型簡單,無需考慮分布式通訊,也無需進行圖切分,但受制于單機系統資源,無法進行更大規模的圖資料分析,
分布式圖計算平臺將圖資料劃分到多個機器上,從而處理更大規模的圖資料,但不可避免的引入了分布式通訊的開銷問題,
1.3 圖的劃分
圖劃分主要有兩種方式邊切割(Edge- Cut)和點切割(Vertex-Cut),
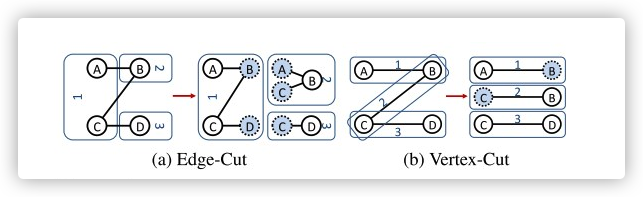
邊分割:每個點的資料只會存盤在一臺機器上,但有的邊會被打斷分到多臺機器上,
如圖(a)所示,點 A 的資料只存放在機器 1 上,點B 的資料只存放在機器 2 上,對于邊 AB 而言,會存盤在機器 1 和機器 2 上,由于點 A 和點 B 分布在不同的機器上,在迭代計算程序中,會帶來通訊上的開銷,
點分割:每條邊只會存盤在一臺機器上,但有的點有可能分割,分配在多臺機器上,
如圖(b)所示, 邊 AB 存盤在機器 1 上,邊 BC 存盤在機器 2 上,邊 CD 存盤在機器 3 上,而點 B 被分配到了 1, 2 兩臺機器上,點 C 被分配到了 2,3 兩臺機器上,由于點被存盤在多臺機器上,維護頂點資料的一致性同樣也會帶來通訊上的開銷,
1.4 計算模型
編程模型是針對圖計算應用開發者,可分為以節點為中心的編程模型、以邊或路徑為中心的編程模型、以子圖為中心的編程模型,
計算模型是圖計算系統開發者面臨的問題,主要有同步執行模型和異步執行模型,比較常見的有 BSP 模型(Bulk Synchronous Parallel Computing Model)和 GAS 模型,
BSP 模型:BSP 模型的計算程序是由一系列的迭代步組成,每個迭代步被稱為超步,采用 BSP 模型的系統主要有 Pregel、Hama、Giraph 等,
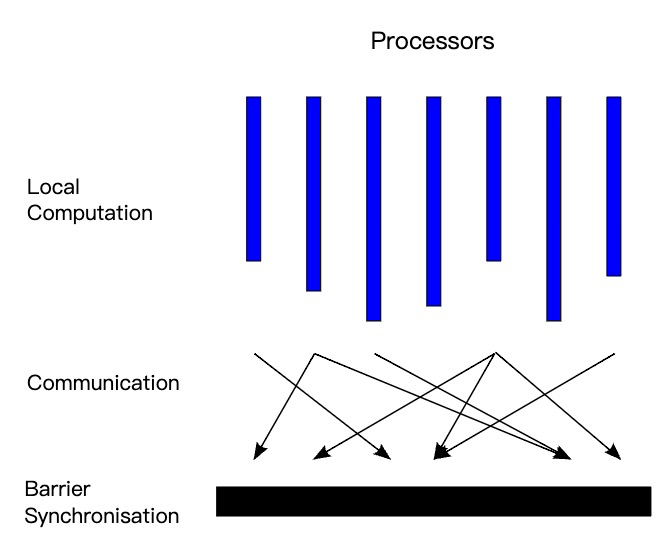
BSP 模型具有水平和垂直兩個方面的結構,垂直上看,BSP 模型有一系列串行的超步組成,水平上看(如圖所示),一個超步又分三個階段:
- 本地計算階段,每個處理器只對存盤本地記憶體中的資料進行計算,
- 全域通信階段,機器節點之間相互交換資料,
- 柵欄同步階段,等待所有通信行為的結束,
GAS 模型:GAS 模型是在 PowerGraph 系統提出,分為資訊收集階段(Gather)、應用階段(Apply)和分發階段(Scatter),
- Gather 階段,負責從鄰居頂點收集資訊,
- Apply 階段,負責將收集的資訊在本地處理,更新到頂點上,
- Scatter 階段,負責發送新的資訊給鄰居頂點,
2. Gemini 圖計算系統介紹
Gemini 在工業界較有影響力,它的主要技術點包括:CSR/CSC、push/pull、master 和 mirror、稀疏和稠密圖、通信與計算協同作業、chunk-based 式磁區、NUMA 感知的子磁區等,
Gemini 采用邊切割方式將圖資料按照 chunk-based 的方式磁區,并支持 Numa 結構,磁區后的資料,用 CSR 存盤出邊資訊,用 CSC 存盤入邊資訊,在迭代計算程序中,對稀疏圖采用 push 的方式更新其出邊鄰居,對稠密圖采用 pull 的方式拉取入邊鄰居的資訊,
如果一條邊被切割,邊的一端頂點為 master,另一端頂點則為 mirror,mirror 被稱為占位符(placeholder) ,在 pull 的計算程序中,各個機器上的 mirror 頂點會拉取其入邊鄰居 master 頂點的資訊進行一次計算,在 BSP 的計算模型下通過網路同步給其 master 頂點,在 push 的計算程序中,各個機器的 master 頂點會將其資訊先同步給它的 mirror 頂點,再由 mirror 更新其出邊鄰居,
在 BSP 的通信階段,每臺機器 Node_i 發送給它的下一個機器 Node_i+1,最后一個機器會發送給第一個機器,在每臺機器發送的同時也會收到 Node_i-1 的資訊,收到資訊后會立即執行本地計算,通訊和計算的重疊可以隱藏通信時間,提升整體的效率,
更多細節可以參考論文《Gemini: A Computation-Centric Distributed Graph Processing System》,
3. Plato 圖計算系統與 Nebula Graph 的集成
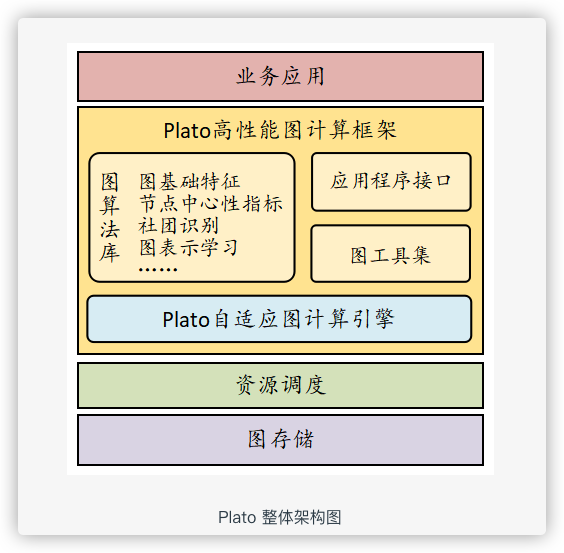
3.1 Plato 圖計算系統介紹
Plato 是騰訊開源的基于 Gemni 論文實作的工業級圖計算系統,Plato 可運行在通用的 x86 集群,如 Kubernetes 集群、Yarn 集群等,在檔案系統層面,Plato 提供了多種介面支持主流的檔案系統,如 HDFS、Ceph 等等,
3.2 與 Nebula Graph 的集成
我們基于 Plato 做了二次開發,以接入 Nebula Graph 資料源,
3.2.1 Nebula Graph 作為輸入和輸出資料源
增加 Plato 的資料源,支持將 Nebula Graph 作為輸入和輸出資料源,直接從 Nebula Graph 中讀取資料進行圖計算,并將計算結果直接寫回到 Nebula Graph 中,
Nebula Graph 的存盤層提供了針對 partition 的 scan 介面,很容易通過該介面批量掃出頂點和邊資料:
ScanEdgeIter scanEdgeWithPart(std::string spaceName,
int32_t partID,
std::string edgeName,
std::vector<std::string> propNames,
int64_t limit = DEFAULT_LIMIT,
int64_t startTime = DEFAULT_START_TIME,
int64_t endTime = DEFAULT_END_TIME,
std::string filter = "",
bool onlyLatestVersion = false,
bool enableReadFromFollower = true);
ScanVertexIter scanVertexWithPart(std::string spaceName,
int32_t partId,
std::string tagName,
std::vector<std::string> propNames,
int64_t limit = DEFAULT_LIMIT,
int64_t startTime = DEFAULT_START_TIME,
int64_t endTime = DEFAULT_END_TIME,
std::string filter = "",
bool onlyLatestVersion = false,
bool enableReadFromFollower = true);
實踐中,我們首先獲取指定 space 下的 partition 分布情況,并將每個 partition 的 scan 任務分別分配給 Plato 集群的各個節點上,每個節點再進一步將 partition 的 scan 任務分配給運行在該節點的各個執行緒上,以達到并行快速的讀取資料,圖計算完成之后,將計算結果通過 Nebula client 并行寫入 Nebula Graph,
3.2.2 分布式 ID 編碼器
Gemini 和 Plato 的要求頂點 ID 從 0 開始連續遞增,但絕大多數的真實資料頂點 ID 并不滿足這個需求,尤其是 Nebula Graph 從 2.0 版本開始支持 string 型別 ID,
因此,在計算之前,我們需要將原始的 ID 從 int 或 string 型別轉換為從 0 開始連續遞增的 int,Plato 內部實作了一個單機版的 ID 編碼器,即 Plato 集群的每臺機器均冗余存盤所有 ID 的映射關系,當點的數量比較多時,每臺機器僅 ID 映射表的存盤就需上百 GB 的記憶體,因為我們需要實作分布式的 ID 映射器,將 ID 映射關系切成多份,分開存盤,
我們通過哈希將原始 ID 打散在不同的機器,并行地分配全域從 0 開始連續遞增的 ID,生成 ID 映射關系后,每臺機器都會存有 ID 映射表的一部分,隨后再將邊資料分別按起點和終點哈希,發送到對應的機器進行編碼,最終得到的資料即為可用于計算的資料,當計算運行結束后,需要資料需要映射回業務 ID,其程序和上述也是類似的,
3.2.3 補充演算法
我們在 Plato 的基礎上增加了 sssp、apsp、jaccard similarity、三角計數等演算法,并為每個演算法增加了輸入和輸出到 Nebula Graph 資料源的支持,目前支持的演算法有:
| 檔案名 | 演算法名稱 | 分類 |
|---|---|---|
| apsp.cc | 全對最短路徑 | 路徑 |
| sssp.cc | 單源最短路徑 | 路徑 |
| tree_stat.cc | 樹深度/寬度 | 圖特征 |
| nstepdegrees.cc | n階度 | 圖特征 |
| hyperanf.cc | 圖平均距離估算 | 圖特征 |
| triangle_count.cc | 三角計數 | 圖特征 |
| kcore.cc | 節點中心性 | |
| pagerank.cc | Pagerank | 節點中心性 |
| bnc.cc | Betweenness | 節點中心性 |
| cnc.cc | 接近中心性(Closeness Centrality) | 節點中心性 |
| cgm.cc | 連通分量計算 | 社區發現 |
| lpa.cc | 標簽傳播 | 社區發現 |
| hanp.cc | HANP | 社區發現 |
| metapath_randomwalk.cc | 圖表示學習 | |
| node2vec_randomwalk.cc | 圖表示學習 | |
| fast_unfolding.cc | louvain | 聚類 |
| infomap_simple.cc | 聚類 | |
| jaccard_similarity.cc | 相似度 | |
| mutual.cc | 其他 | |
| torch.cc | 其他 | |
| bfs.cc | 廣度優先遍歷 | 其他 |
4. Plato 部署安裝與運行
4.1 集群部署
Plato 采用 MPI 進行行程間通信,在集群上部署 Plato 時,需要將 Plato 安裝在相同的目錄下,或者使用 NFS,操作方法見:https://mpitutorial.com/tutorials/running-an-mpi-cluster-within-a-lan/
4.2 運行演算法的腳本及組態檔
scripts/run_pagerank_local.sh
#!/bin/bash
PROJECT="$(cd "$(dirname "$0")" && pwd)/.."
MAIN="./bazel-bin/example/pagerank" # process name
WNUM=3
WCORES=8
#INPUT=${INPUT:="$PROJECT/data/graph/v100_e2150_ua_c3.csv"}
INPUT=${INPUT:="nebula:${PROJECT}/scripts/nebula.conf"}
#OUTPUT=${OUTPUT:='hdfs://192.168.8.149:9000/_test/output'}
OUTPUT=${OUTPUT:="nebula:$PROJECT/scripts/nebula.conf"}
IS_DIRECTED=${IS_DIRECTED:=true} # let plato auto add reversed edge or not
NEED_ENCODE=${NEED_ENCODE:=true}
VTYPE=${VTYPE:=uint32}
ALPHA=-1
PART_BY_IN=false
EPS=${EPS:=0.0001}
DAMPING=${DAMPING:=0.8}
ITERATIONS=${ITERATIONS:=5}
export MPIRUN_CMD=${MPIRUN_CMD:="${PROJECT}/3rd/mpich-3.2.1/bin/mpiexec.hydra"}
PARAMS+=" --threads ${WCORES}"
PARAMS+=" --input ${INPUT} --output ${OUTPUT} --is_directed=${IS_DIRECTED} --need_encode=${NEED_ENCODE} --vtype=${VTYPE}"
PARAMS+=" --iterations ${ITERATIONS} --eps ${EPS} --damping ${DAMPING}"
# env for JAVA && HADOOP
export LD_LIBRARY_PATH=${JAVA_HOME}/jre/lib/amd64/server:${LD_LIBRARY_PATH}
# env for hadoop
export CLASSPATH=${HADOOP_HOME}/etc/hadoop:`find ${HADOOP_HOME}/share/hadoop/ | awk '{path=path":"$0}END{print path}'`
export LD_LIBRARY_PATH="${HADOOP_HOME}/lib/native":${LD_LIBRARY_PATH}
chmod 777 ./${MAIN}
${MPIRUN_CMD} -n ${WNUM} -f ${PROJECT}/scripts/cluster ./${MAIN} ${PARAMS}
exit $?
引數說明
INPUT引數和OUPUT引數分別指定演算法的輸入資料源和輸出資料源,目前支持本地 csv 檔案、HDFS檔案、 Nebula Graph,當輸入輸出資料源為 Nebula Graph 時,INPUT和OUPUT形式為nebula:/path/to/nebula.conf- WNUM 為集群所有機器所運行的行程數之和,推薦每臺機器運行為 1 或者 NUMA node 數個行程,WCORE 為每個行程的執行緒數,推薦最大設定為機器的硬體執行緒數,
scripts/nebula.conf
## read/write
--retry=3 # 連接 Nebula Graph 時的重試次數
--space=sf30 # 要讀取或寫入的 space 名稱
## read from nebula
--meta_server_addrs=192.168.8.94:9559 # Nebula Graph 的 metad 服務地址
--edge=LIKES # 要讀取的邊的名稱
#--edge_data_field # 要讀取的作為邊的權重屬性的名稱
--read_batch_size=10000 # 每次 scan 時的 batch 的大小
## write to nebula
--graph_server_addrs=192.168.8.94:9669 # Nebula Graph 的 graphd 服務地址
--user=root # graphd 服務的登陸用戶名
--password=nebula # graphd 服務的登陸密碼
# insert or update
--mode=insert # 寫回 Nebula Graph 時采用的模式: insert/update
--tag=pagerank # 寫回到 Nebula Graph 的 tag 名稱
--prop=pr # 寫回到 Nebula Graph 的 tag 對應的屬性名稱
--type=double # 寫回到 Nebula Graph 的 tag 對應的屬性的型別
--write_batch_size=1000 # 寫回時的 batch 大小
--err_file=/home/plato/err.txt # 寫回失敗的資料所存盤的檔案
scripts/cluster
cluster 檔案指定要運行該演算法所在的集群機器的 IP
192.168.15.3
192.168.15.5
192.168.15.6
以上為 Plato 在 Nebula Graph 中的應用,目前該功能集成在 Nebula Graph 企業版中,如果你使用的是開源版本的 Nebula Graph,需按照自己的需求自己對接 Plato,
交流圖資料庫技術?加入 Nebula 交流群請先填寫下你的 Nebula 名片,Nebula 小助手會拉你進群~~
關注公眾號
Nebula Graph:一個開源的分布式圖資料庫轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/436374.html
標籤:其他