一、CK 分布式表和本地表
(1)CK是一個純列式存盤的資料庫,一個列就是硬碟上的一個或多個檔案(多個磁區有多個檔案),關于列式存盤這里就不展開了,總之列存對于分析來講好處更大,因為每個列單獨存盤,所以每一列資料可以壓縮,不僅節省了硬碟,還可以降低磁盤IO,
(2)CK是多核并行處理的,為了充分利用CPU資源,多執行緒和多核必不可少,同時向量化執行也會大幅提高速度,
(3)提供SQL查詢介面,CK的客戶端連接方式分為HTTP和TCP,TCP更加底層和高效,HTTP更容易使用和擴展,一般來說HTTP足矣,社區已經有很多各種語言的連接客戶端,
(4)CK不支持事務,大資料場景下對事務的要求沒這么高,
(5)不建議按行更新和洗掉,CK的洗掉操作也會轉化為增加操作,粒度太低嚴重影響效率,
生產環境中通常是使用集群部署,CK的集群與Hadoop等集群稍微有些不一樣,如圖所示,CK集群共包含以下幾個關鍵概念:
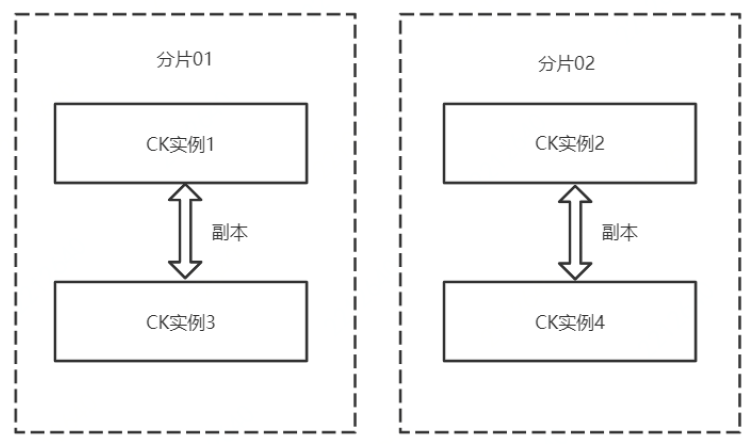
(1)CK實體,可以一臺主機上起多個CK實體,埠不同即可,也可以一臺主機一個CK實體,
(2)分片,資料的水平劃分,例如隨機劃分時,圖5中每個分片各有大約一半資料,
(3)副本,資料的冗余備份,同時也可作為查詢節點,多個副本同時提供資料查詢服務,能夠加快資料的查詢效率,提高并發度,圖5中CK實體1和示例3存盤了相同資料,
(4)多主集群模式,CK的每個實體都可以叫做副本,每個物體都可以提供查詢,不區分主從,只是在寫入資料時會在每個分片里臨時選一個主副本,來提供資料同步服務,具體見下文中的寫入程序,
ck的表分為兩種:
-
分布式表
一個邏輯上的表, 可以理解為資料庫中的視圖, 一般查詢都查詢分布式表. 分布式表引擎會將我們的查詢請求路由本地表進行查詢, 然后進行匯總最侄訓傳給用戶.
-
本地表:
實際存盤資料的表
1、Replication & Sharding
ClickHouse像ElasticSearch一樣具有資料分片(shard)的概念,這也是分布式存盤的特點之一,即通過并行讀寫提高效率,ClickHouse依靠Distributed引擎實作了分布式表機制,在所有分片(本地表)上建立視圖進行分布式查詢,使用很方便,ClickHouse依靠ReplicatedMergeTree引擎族與ZooKeeper實作了復制表機制,成為其高可用的基礎,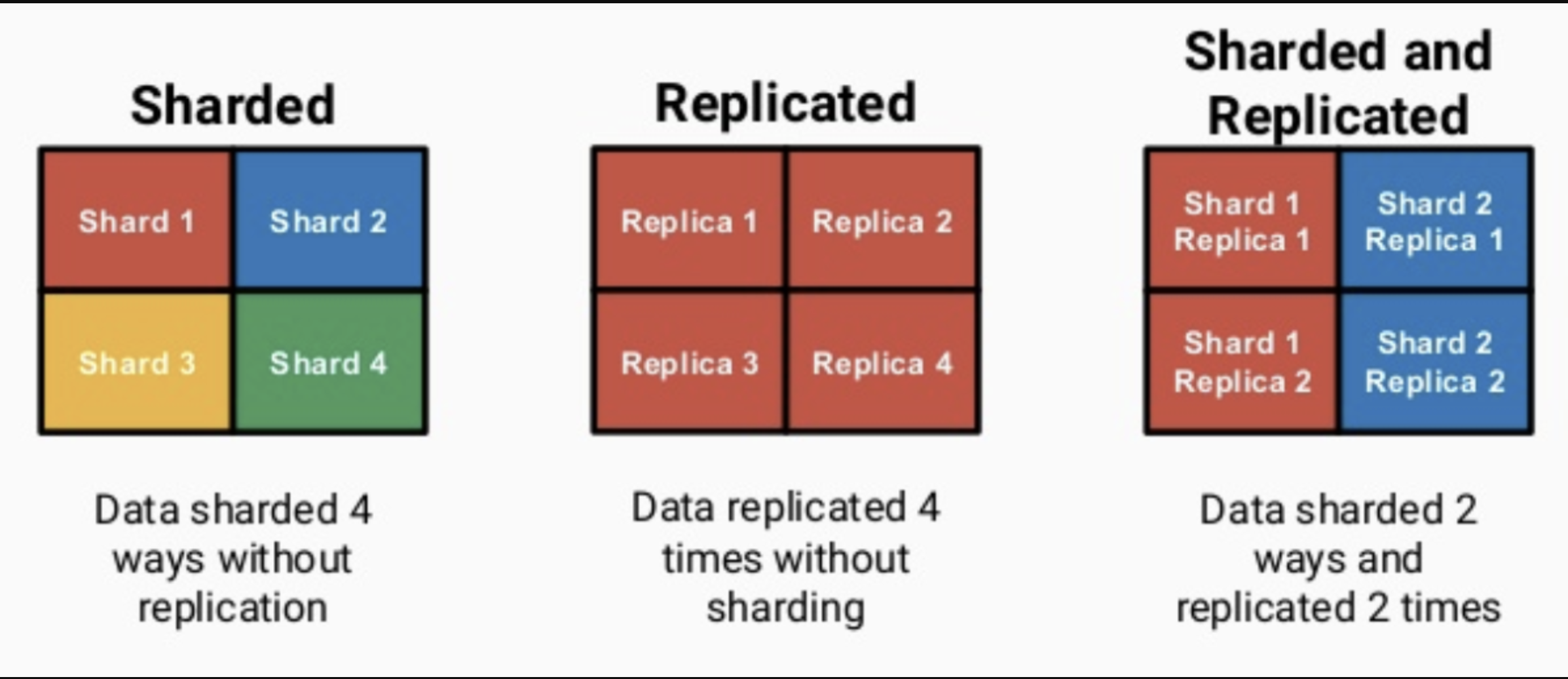
2、一般 不寫分布式表的原因
- 分布式表接收到資料后會將資料拆分成多個parts, 并轉發資料到其它服務器, 會引起服務器間網路流量增加、服務器merge的作業量增加, 導致寫入速度變慢, 并且增加了Too many parts的可能性.
- 資料的一致性問題, 先在分布式表所在的機器進行落盤, 然后異步的發送到本地表所在機器進行存盤,中間沒有一致性的校驗, 而且在分布式表所在機器時如果機器出現down機, 會存在資料丟失風險.
- 資料寫入默認是異步的,短時間內可能造成不一致.
- 對zookeeper的壓力比較大(待驗證). 沒經過正式測驗, 只是看到了有人提出.
3、Replicated Table & ReplicatedMergeTree Engines
ClickHouse的副本機制之所以叫“復制表”,是因為它作業在表級別,而不是集群級別(如HDFS),也就是說,用戶在創建表時可以通過指定引擎選擇該表是否高可用,每張表的分片與副本都是互相獨立的,
目前支持復制表的引擎是ReplicatedMergeTree引擎族,它與平時最常用的MergeTree引擎族是正交的,如下圖所示,
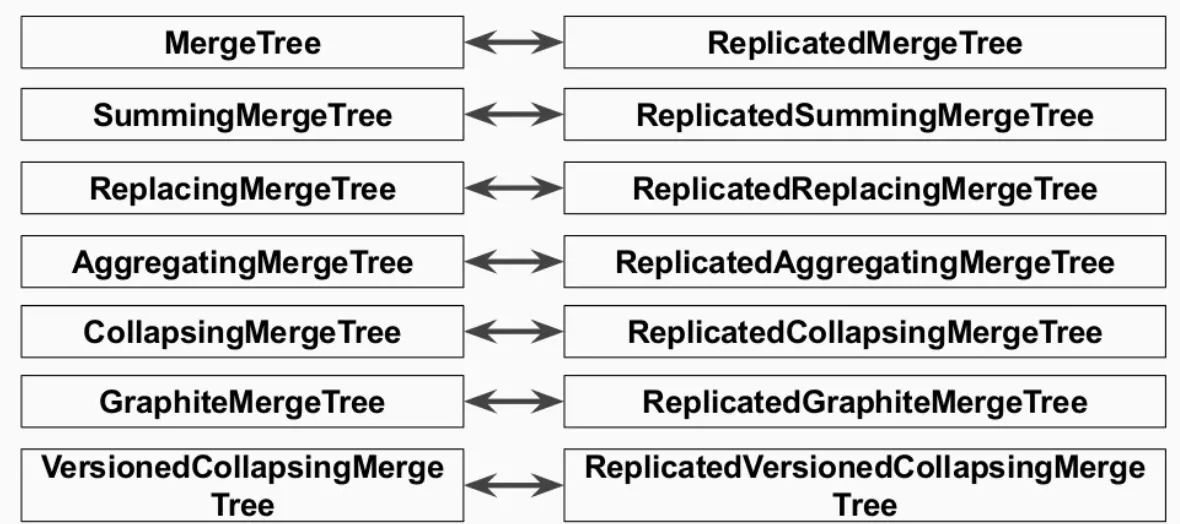
不同于HDFS的副本機制(基于集群實作), Clickhouse的副本機制是基于表實作的. 用戶在創建每張表的時候, 可以決定該表是否高可用.
Local_table
CREATE TABLE IF NOT EXISTS {local_table} ({columns}) ENGINE = ReplicatedMergeTree('/clickhouse/tables/#_tenant_id_#/#__appname__#/#_at_date_#/{shard}/hits', '{replica}') partition by toString(_at_date_) sample by intHash64(toInt64(toDateTime(_at_timestamp_))) order by (_at_date_, _at_timestamp_, intHash64(toInt64(toDateTime(_at_timestamp_))))
ReplicatedMergeTree
CREATE TABLE IF NOT EXISTS test.events_local ON CLUSTER '{cluster}' ( ts_date Date, ts_date_time DateTime, user_id Int64, event_type String, site_id Int64, groupon_id Int64, category_id Int64, merchandise_id Int64, search_text String -- A lot more columns... ) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/test/events_local','{replica}') PARTITION BY ts_date ORDER BY (ts_date_time,site_id,event_type) SETTINGS index_granularity = 8192;
其中,ON CLUSTER語法表示分布式DDL,即執行一次就可在集群所有實體上創建同樣的本地表,集群識別符號{cluster}、分片識別符號{shard}和副本識別符號{replica}來自之前提到過的復制表宏配置,即config.xml中<macros>一節的內容,配合ON CLUSTER語法一同使用,可以避免建表時在每個實體上反復修改這些值,
ReplicatedMergeTree引擎族接收兩個引數:
- ZK中該表相關資料的存盤路徑,ClickHouse官方建議規范化,如上面的格式
/clickhouse/tables/{shard}/[database_name]/[table_name], - 副本名稱,一般用
{replica}即可,
支持復制表的引擎都是ReplicatedMergeTree引擎族, 具體可以查看官網:
Data Replication
作者:張永清 來源于博客園https://www.cnblogs.com/laoqing/p/15954171.html
ReplicatedMergeTree引擎族接收兩個引數:
- ZK中該表相關資料的存盤路徑, ClickHouse官方建議規范化, 例如:
/clickhouse/tables/{shard}/[database_name]/[table_name]. - 副本名稱, 一般用
{replica}即可.
ReplicatedMergeTree引擎族非常依賴于zookeeper, 它在zookeeper中存盤了大量的資料:
表結構資訊、元資料、操作日志、副本狀態、資料塊校驗值、資料part merge程序中的選主資訊...
同時, zookeeper又在復制表急之下扮演了三種角色:
元資料存盤、日志框架、分布式協調服務
可以說當使用了ReplicatedMergeTree時, zookeeper壓力特別重, 一定要保證zookeeper集群的高可用和資源.
3.1. 資料同步的流程
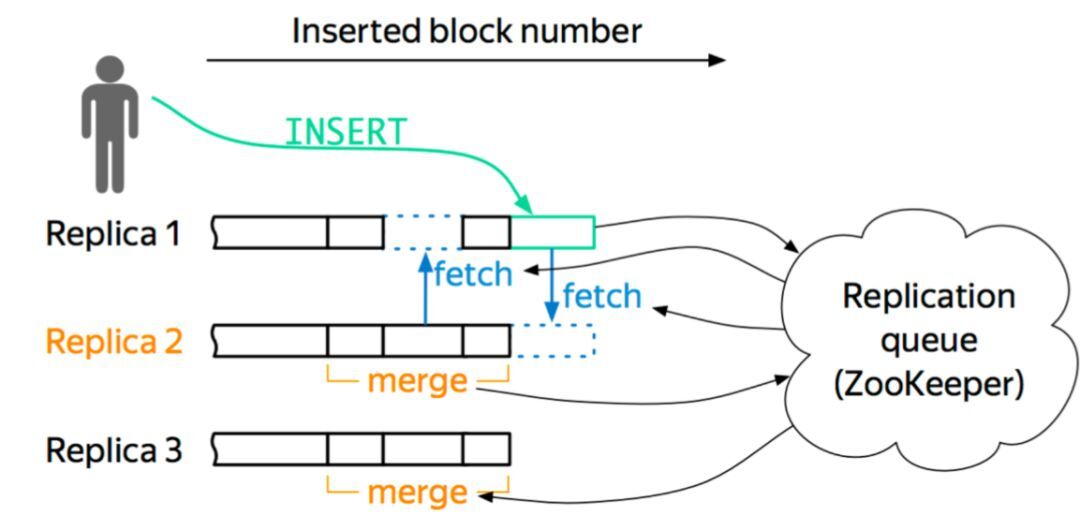
ReplicatedMergeTree引擎族在ZK中存盤大量資料,包括且不限于表結構資訊、元資料、操作日志、副本狀態、資料塊校驗值、資料part merge程序中的選主資訊等等,可見,ZK在復制表機制下扮演了元資料存盤、日志框架、分布式協調服務三重角色,任務很重,所以需要額外保證ZK集群的可用性以及資源(尤其是硬碟資源), 下圖大致示出復制表執行插入操作時的流程(internal_replication配置項為true),即先寫入一個副本,再通過config.xml中配置的interserver HTTP port埠(默認是9009)將資料復制到其他實體上去,同時更新ZK集群上記錄的資訊,
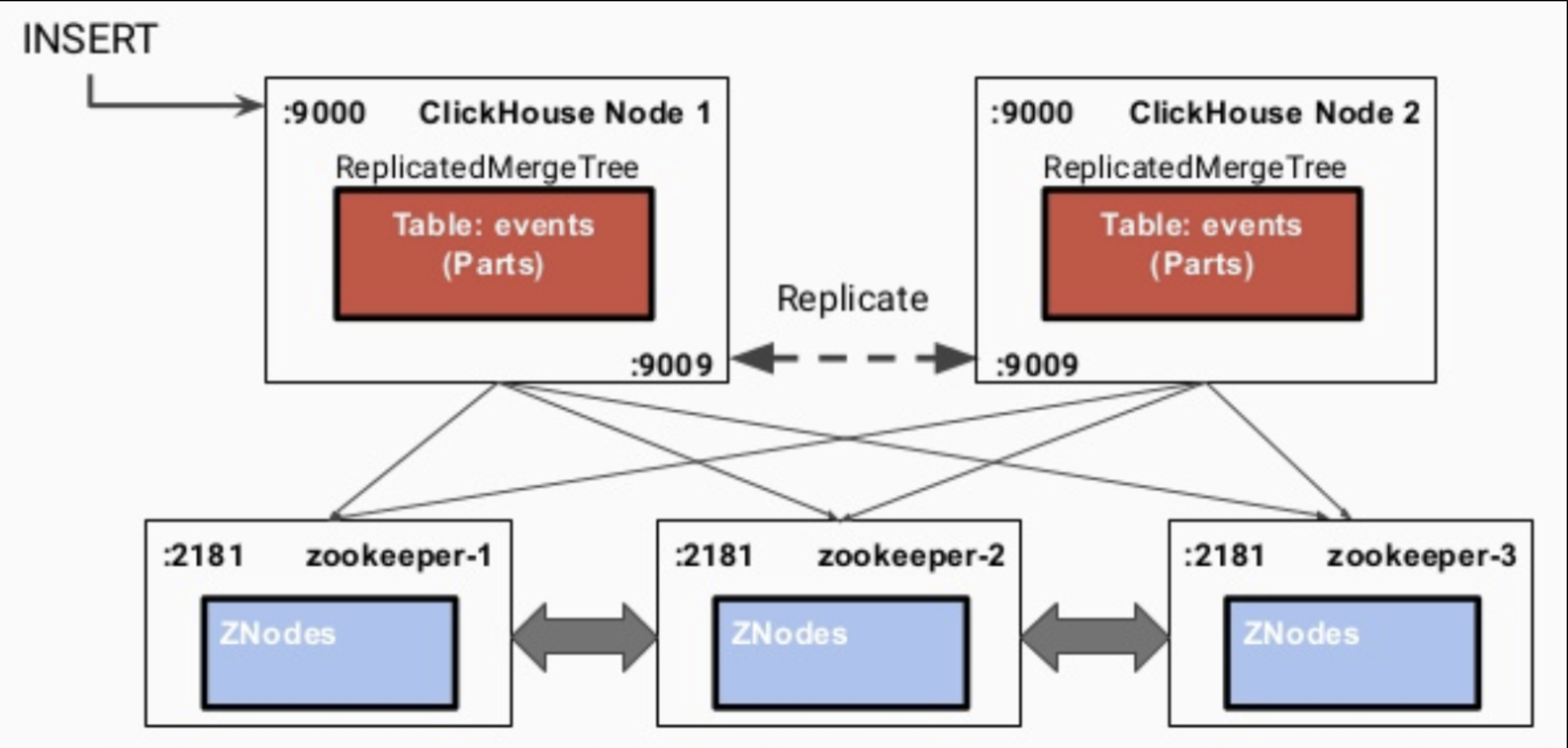
- 寫入到一個節點
- 通過
interserver HTTP port埠同步到其他實體上 - 更新zookeeper集群記錄的資訊
3.2. 重度依賴Zookeeper導致的問題
ck的replicatedMergeTree引擎方案有太多的資訊存盤在zk上, 當資料量增大, ck節點數增多, 會導致服務非常不穩定, 目前我們的ck集群規模還小, 這個問題還不嚴重, 但依舊會出現很多和zk有關的問題(詳見遇到的問題).
實際上 ClickHouse 把 ZK 當成了三種服務的結合, 而不僅把它當作一個 Coordinate service(協調服務), 可能這也是大家使用 ZK 的常用用法,ClickHouse 還會把它當作 Log Service(日志服務),很多行為日志等數字的資訊也會存在 ZK 上;還會作為表的 catalog service(元資料存盤),像表的一些 schema 資訊也會在 ZK 上做校驗,這就會導致 ZK 上接入的數量與資料總量會成線性關系,
作者:張永清 來源于博客園https://www.cnblogs.com/laoqing/p/15954171.html
目前針對這個問題, clickhouse社區提出了一個mini checksum方案, 但是這并沒有徹底解決 znode 與資料量成線性關系的問題. 目前看到比較好的方案是位元組的:
我們就基于 MergeTree 存盤引擎開發了一套自己的高可用方案,我們的想法很簡單,就是把更多 ZK 上的資訊卸載下來,ZK 只作為 coordinate Service,只讓它做三件簡單的事情:行為日志的 Sequence Number 分配、Block ID 的分配和資料的元資訊,這樣就能保證資料和行為在全域內是唯一的,
關于節點,它維護自身的資料資訊和行為日志資訊,Log 和資料的資訊在一個 shard 內部的副本之間,通過 Gossip 協議進行互動,我們保留了原生的 multi-master 寫入特性,這樣多個副本都是可以寫的,好處就是能夠簡化資料匯入,圖 6 是一個簡單的框架圖,
以這個圖為例,如果往 Replica 1 上寫,它會從 ZK 上獲得一個 ID,就是 Log ID,然后把這些行為和 Log Push 到集群內部 shard 內部活著的副本上去,然后當其他副本收到這些資訊之后,它會主動去 Pull 資料,實作資料的最終一致性,我們現在所有集群加起來 znode 數不超過三百萬,服務的高可用基本上得到了保障,壓力也不會隨著資料增加而增加,
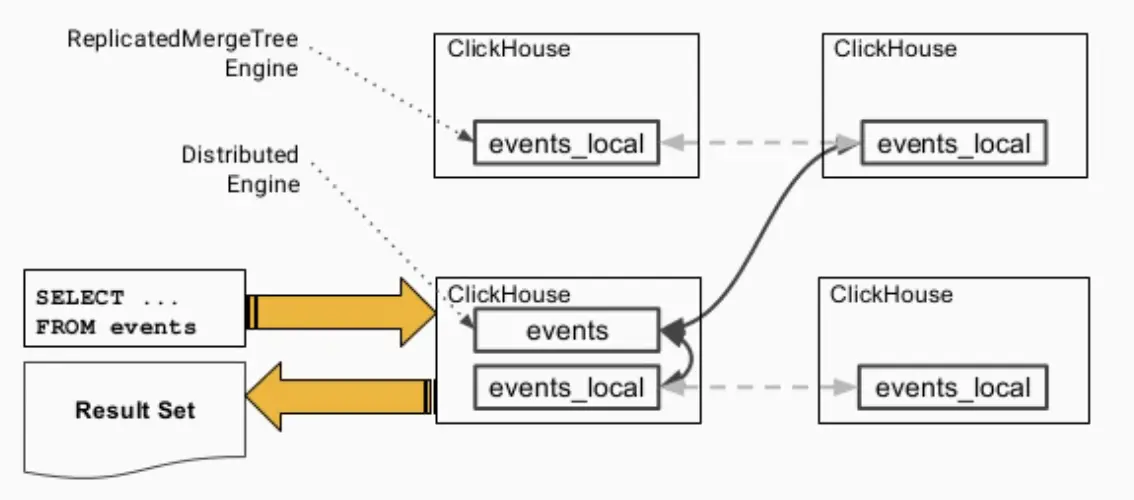
ClickHouse分布式表的本質并不是一張表,而是一些本地物理表(分片)的分布式視圖,本身并不存盤資料,
支持分布式表的引擎是Distributed,建表DDL陳述句示例如下,_all只是分布式表名比較通用的后綴而已,
CREATE TABLE IF NOT EXISTS test.events_all ON CLUSTER sht_ck_cluster_1 AS test.events_local ENGINE = Distributed(sht_ck_cluster_1,test,events_local,rand());
Distributed引擎需要以下幾個引數:
- 集群識別符號
注意不是復制表宏中的識別符號,而是<remote_servers>中指定的那個, - 本地表所在的資料庫名稱
- 本地表名稱
- (可選的)分片鍵(sharding key)
該鍵與config.xml中配置的分片權重(weight)一同決定寫入分布式表時的路由,即資料最終落到哪個物理表上,它可以是表中一列的原始資料(如site_id),也可以是函式呼叫的結果,如上面的SQL陳述句采用了隨機值rand(),注意該鍵要盡量保證資料均勻分布,另外一個常用的操作是采用區分度較高的列的哈希值,如intHash64(user_id),
在分布式表上執行查詢的流程簡圖如下所示,發出查詢后,各個實體之間會交換自己持有的分片的表資料,最侄訓總到同一個實體上回傳給用戶,
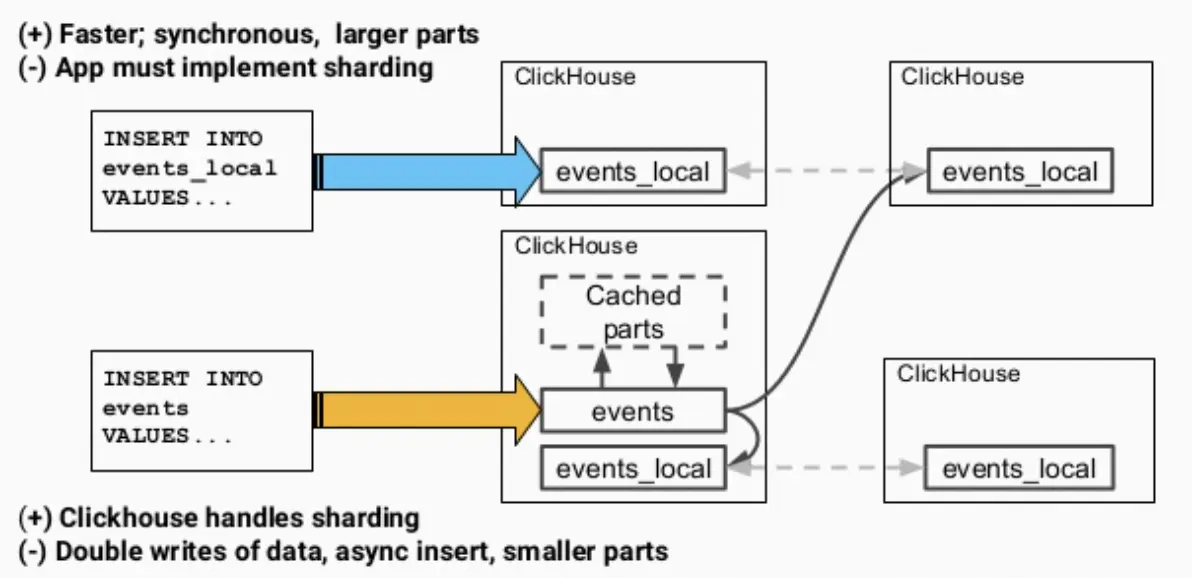
而在寫入時,我們有兩種選擇:一是寫分布式表,二是寫underlying的本地表,孰優孰劣呢?
直接寫分布式表的優點自然是可以讓ClickHouse控制資料到分片的路由,缺點就多一些:
- 資料是先寫到一個分布式表的實體中并快取起來,再逐漸分發到各個分片上去,實際是雙寫了資料(寫入放大),浪費資源;
- 資料寫入默認是異步的,短時間內可能造成不一致;
- 目標表中會產生較多的小parts,使merge(即compaction)程序壓力增大,
相對而言,直接寫本地表是同步操作,更快,parts的大小也比較合適,但是就要求應用層額外實作sharding和路由邏輯,如輪詢或者隨機等,
在生產環境中總是推薦寫本地表、讀分布式表,采用了隨機路由,部分代碼如下
private Request buildRequest(ClickhouseRequestBlank requestBlank) { String resultCSV = String.join(" , ", requestBlank.getValues()); String query = String.format("INSERT INTO %s VALUES %s", requestBlank.getTargetTable(), resultCSV); String host = sinkSettings.getClickhouseClusterSettings().getRandomHostUrl(); BoundRequestBuilder builder = asyncHttpClient .preparePost(host) .setHeader(HttpHeaders.Names.CONTENT_TYPE, "text/plain; charset=utf-8") .setBody(query); if (sinkSettings.getClickhouseClusterSettings().isAuthorizationRequired()) { builder.setHeader(HttpHeaders.Names.AUTHORIZATION, "Basic " + sinkSettings.getClickhouseClusterSettings().getCredentials()); } return builder.build(); } public String getRandomHostUrl() { currentHostId = ThreadLocalRandom.current().nextInt(hostsWithPorts.size()); return hostsWithPorts.get(currentHostId); }
完整代碼參考:https://github.com/ivi-ru/flink-clickhouse-sink
作者:張永清 來源于博客園https://www.cnblogs.com/laoqing/p/15954171.html
二、ClickHouse實作時序資料管理和挖掘
ClickHouse在時序資料庫上的能力體現:
(1)時間:時間是必不可少的,按照時間磁區能夠大幅降低資料掃描范圍;
(2)過濾:對條件的過濾一般基于某些列,對于列式存盤來說優勢明顯;
(3)降采樣:對于時序來說非常重要的功能,可以通過聚合實作,CK自帶時間各個粒度的時間轉換函式以及強大的聚合能力,可以滿足要求;
(4)分析挖掘:可以開發擴展的函式來支持,
另外CK作為一個大資料系統,也滿足以下基礎要求:
(1)高吞吐寫入;
(2)海量資料存盤:冷熱備份,TTL;
(3)高效實時的查詢;
(4)高可用;
(5)可擴展性:可以實作自定義開發;
(6)易于使用:提供了JDBC和HTTP介面;
(7)易于維護:資料遷移方便,恢復容易,后續可能會將依賴的ZK去掉,內置分布式功能,
時序查詢場景會有很多聚合查詢,對于特定場景,如果使用的非常頻繁且資料量非常大,我們可以采用物化視圖進行預聚合,然后查詢物化視圖
未完待續,敬請期待.....
參考#
Clickhouse Overview
ClickHouse復制表、分布式表機制與使用方法
最快開源 OLAP 引擎! ClickHouse 在頭條的技術演進
作者的原創文章,轉載須注明出處,原創文章歸作者所有,歡迎轉載,但是保留著作權,對于轉載了博主的原創文章,不標注出處的,作者將依法追究著作權,請尊重作者的成果,轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/436376.html
標籤:其他