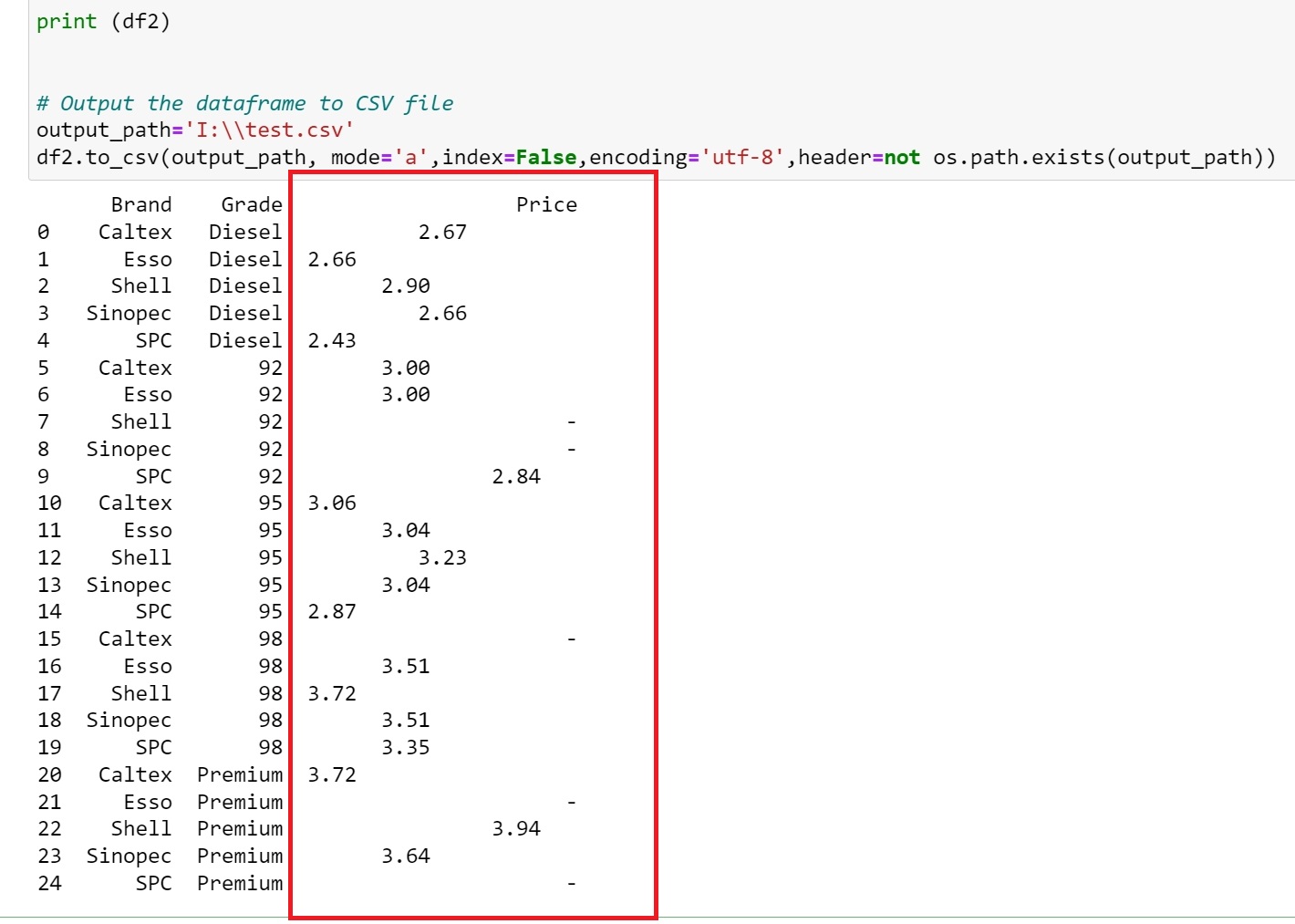
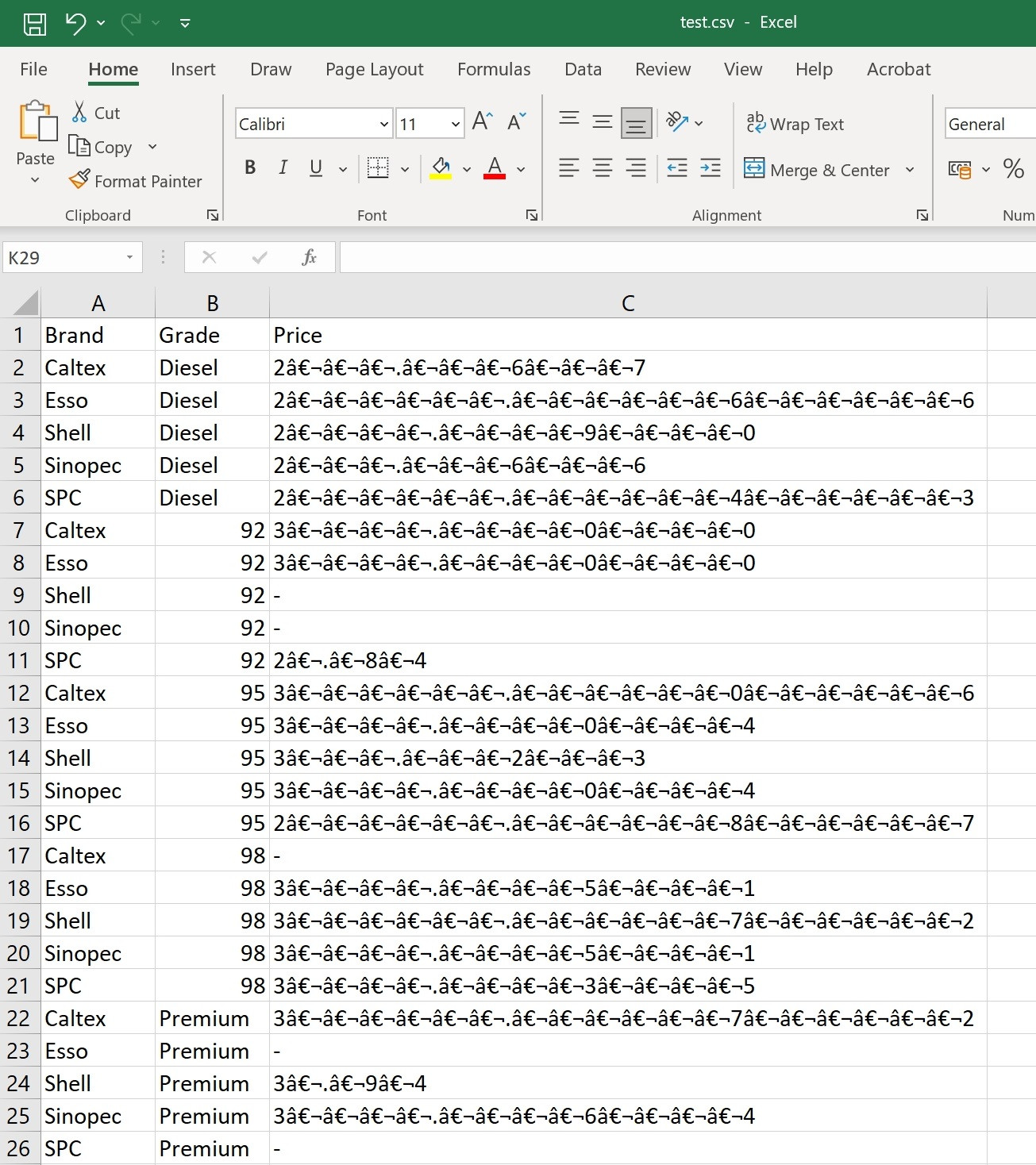
我從 HTML 表中提取了一些資訊,重新組織了資料并嘗試將資料輸出到 CSV 檔案。但是,我在輸出 CSV 的“價格”列中看到了很多亂碼(見下文)。當我檢查 Python 中的資料框內容時,我看到價格列似乎有空格/制表符和奇怪的對齊方式。
當我列印出資料框時的結果:
輸出 CSV 中的亂碼:
在下面附上我的代碼,以便您能夠復制問題:
import time
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import pandas as pd
import os
# Using Selenium to Load Page and Parse with BeautifulSoup
url = 'https://fuelkaki.sg/home'
options = Options()
options.binary_location = "C:\Program Files (x86)\Google\Chrome\Application\chrome.exe"
options.add_argument('--disable-gpu')
driver = webdriver.Chrome(options=options)
driver.get(url)
time.sleep(3)
page = driver.page_source
driver.quit()
soup = BeautifulSoup(page, 'html.parser')
# Using Pandas to read the table on the page and reorganize the data
df = pd.read_html(page)
df[0].columns=['Brand','Diesel','92','95','98','Premium']
df1 = df[0]
del df1['Brand']
df1.insert(0,"Brand",["Caltex", "Esso","Shell", "Sinopec","SPC"],True)
df2=pd.melt(df[0],id_vars=['Brand'],value_vars=['Diesel','92','95','98','Premium'],var_name='Grade',value_name='Price')
# Using Pandas to clean the data in the 'Price" column
df2['Price']=df2['Price'].apply(lambda x: x.replace("Diesel", ""))
df2['Price']=df2['Price'].apply(lambda x: x.replace("Regular", ""))
df2['Price']=df2['Price'].apply(lambda x: x.replace("Extra", ""))
df2['Price']=df2['Price'].apply(lambda x: x.replace("(Synergy Supreme )", ""))
df2['Price']=df2['Price'].apply(lambda x: x.replace("(Platinum 98)", ""))
df2['Price']=df2['Price'].apply(lambda x: x.replace("(Shell V-Power)", ""))
df2['Price']=df2['Price'].apply(lambda x: x.replace("(SINO X Power)", ""))
df2['Price']=df2['Price'].apply(lambda x: x.replace("S$ ", ""))
df2['Price']=df2['Price'].apply(lambda x: x.replace("N.A.", "-"))
print (df2)
# Output the dataframe to CSV file
output_path='I:\\test.csv'
df2.to_csv(output_path, mode='a',index=False,encoding='utf-8',header=not os.path.exists(output_path))
感謝有關如何更正間距、洗掉空格和修復亂碼的任何建議。
uj5u.com熱心網友回復:
在您現有的所有應用/替換行之后添加此行。在此之后,它列印得很好。看起來你有 unicode 字符,可以編碼為 ascii 并忽略錯誤:
df2['Price']=df2['Price'].apply(lambda x: x.encode("ascii", "ignore").decode())
資料幀輸出
Brand Grade Price
0 Caltex Diesel 2.67
1 Esso Diesel 2.66
2 Shell Diesel 2.90
3 Sinopec Diesel 2.66
4 SPC Diesel 2.43
5 Caltex 92 3.00
6 Esso 92 3.00
CSV 輸出

轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/440320.html
上一篇:span元素的完整邊框長度與span元素中的文本無關
下一篇:如何在顯示塊div中移動文本