一、插入優化
批量插入
insert into tb_name values (1,"張三"),(2,"張三"),(3,"張三");
手動提交事務
由于mysql默認事務提交方式是自動提交的,意味著當我們執行完一條insert陳述句之后,事務就自動提交了,可能會頻繁的涉及到事務的開始與提交,所以建議手動控制事務,
start transaction ; insert into tb_name values (1,"張三"),(2,"張三"),(3,"張三"); insert into tb_name values (4,"張三"),(5,"張三"),(6,"張三"); insert into tb_name values (7,"張三"),(8,"張三"),(9,"張三"); commit ;
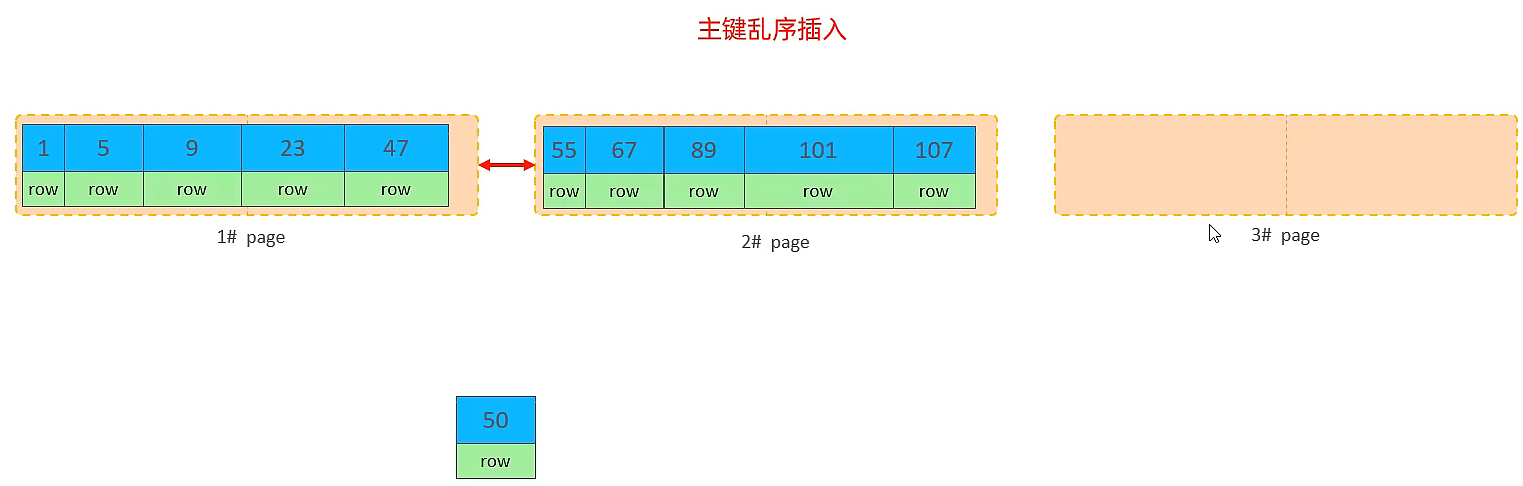
主鍵順序插入
主鍵順序插入的性能要高于亂序插入的性能,取決于MySQL的資料組織結構的,
大批量插入資料
如果一次性需要插入大批量資料,使用insert陳述句插入性能較低,此時可以使用MySQL資料庫提供的load指令進行插入,操作如下:
#客戶端連接服務端時,加上引數--local-infile mysql --local-infile -U root -p
#設定全域引數local infile為1,開啟從本地加載檔案匯入資料的開關 set global local infile= 1;
#執行load指令將準備好的資料,加載到表結構中 在使用load指令時,主鍵順序插入性能高于亂序插入 load data local infile '/xxx/sql.log' into table 'tb_name' fields terminated by ',' lines terminated by '\n' ;
/xxx/sql.log : 將要加載的本地檔案 tb_name : 表名 , : 欄位分割符 \n : 行分割符
二、主鍵SQL優化
資料組織方式
在InnoDB存盤引擎中,表資料都是根據主鍵順序組織存放的,這種存盤方式的表稱為索引組織表(index organized table IOT),
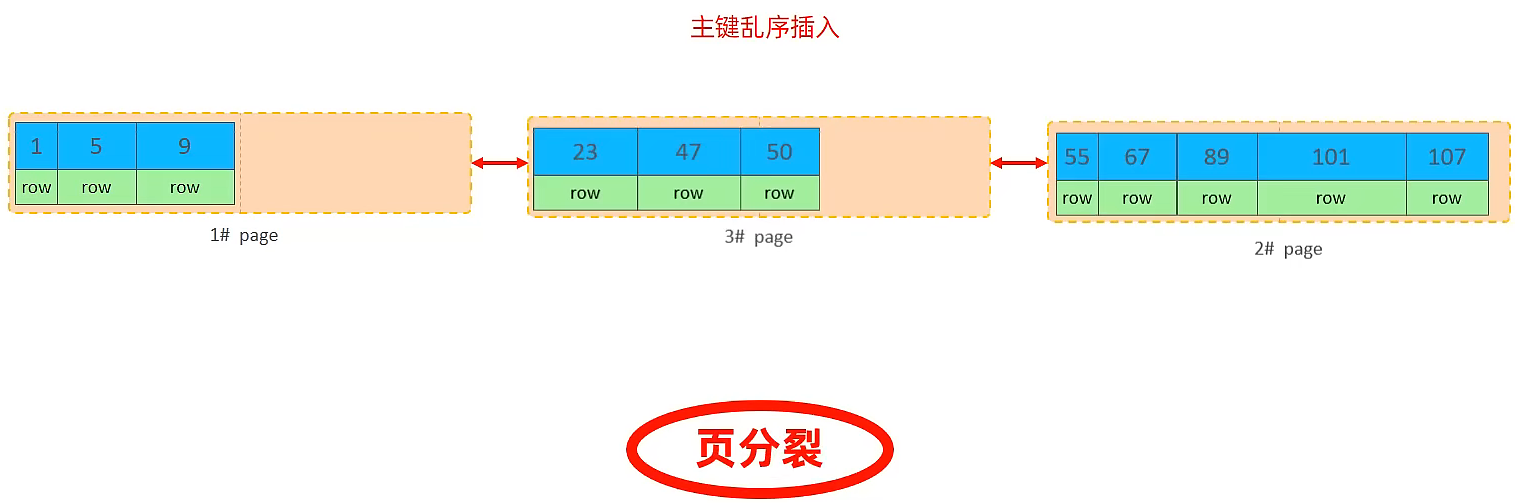
頁分裂
頁可以為空,也可以填充一半,也可以填充100%,每個頁包含了2-N行資料(如果一行資料過大, 會行溢位),根據主鍵排列,


頁合并
當洗掉一行記錄時,實際上記錄并沒有被物理洗掉,只是記錄被標記(flaged) 為洗掉并且它的空間變得允許被其他記錄宣告使用,
當頁中洗掉的記錄達到MERGE_THRESHOLD (默認為頁的50%) , InnoDB會開始尋找最靠近的頁(前或后)看看是否可以將兩個頁合并以優化空間使用,


主鍵的設計原則
滿足業務需求的情況下,盡量降低主鍵的長度,
插入資料時,盡量選擇順序插入,選擇使用AUTO_ INCREMENT自增主鍵 ,
盡量不要使用UUID做主鍵或者是其他自然主鍵,如身份證號,
業務操作時,避免對主鍵的修改,
三、order by 優化
① Using filesort :通過表的索引或全表掃描,讀取滿足條件的資料行,然后在排序緩沖區sort buffer中完成排序操作,所有不是通過索引直接回傳排序結果的排序都叫FileSort排序,
② Using index :通過有序索引順序掃描直接回傳有序資料,這種情況即為using index,不需要額外排序,操作效率高,
#沒有創建索引時,根據age, phone進行排序 explain select id,age,phone from tb_user order by age , phone;
#創建索引 create index idx_user_age_ phone_aa on tb_user(age,phone);
#創建索引后,根據age, phone進行升序排序 explain select id,age,phone from tb_user order by age , phone;
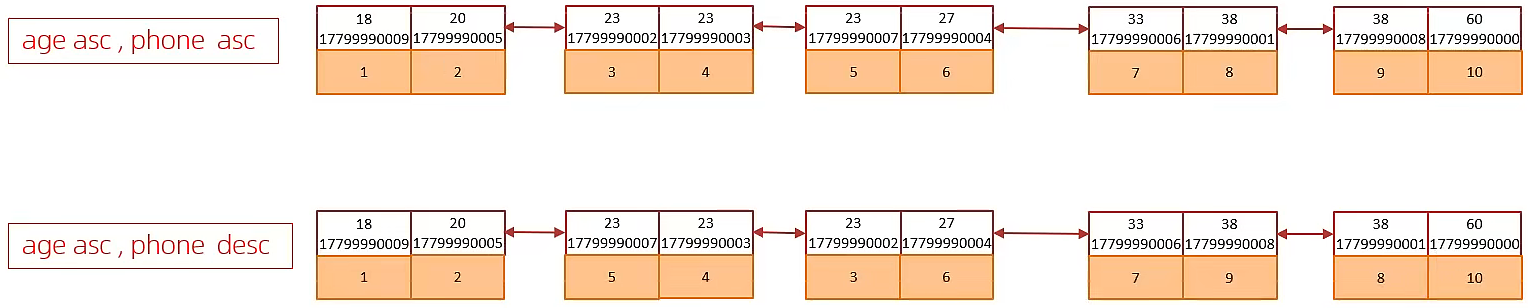
#創建索引后,根據age, phone進行降序排序 explain select id,age,phone from tb_user order by age desc , phone desc ;
#根據age, phone進行降序一個升序,一個降序
explain select id,age,phone from tb_user order by age asc , phone desc;
#創建索引
create index idx_user_age_hone_ad on tb_user(age asc ,phone desc);
#根據age, phone進行降序一個升序,一個降序
explain select id,age,phone from tb_user order by age asc , phone desc;
根據排序欄位建立合適的索引,多欄位排序時,也遵循最左前綴法則,
盡量使用覆寫索引,
多欄位排序,一個升序一個降序,此時需要注意聯合索引在創建時的規則(ASC/DESC) ,
如果不可避免的出現filesort,大資料量排序時,可以適當增大排序緩沖區大小sort_ buffer_ size(默認256k),
四、group by 優化
#執行分組操作,根據profession欄位分組 explain select profession , count(*) from tb_user group by profession ;
#創建索引 Create index idx_user_pro_age_sta on tb_user(profession , age , status);
#執行分組操作,根據profession欄位分組 explain select profession , count(*) from tb_user group by profession;
#執行分組操作,根據profession字 段分組 explain select profession, count(*) from tb_user group by profession,age;
在分組操作時,可以通過索引來提高效率,
分組操作時,索引的使用也是滿足最左前綴法則的,
五、limit 優化
一個常見又非常頭疼的問題就是limit 2000000,10,此時需要MySQL排序前2000010記錄,僅僅回傳2000000 - 2000010的記錄,其他記錄丟棄,查詢排序的代價非常大,
優化思路:一般分頁查詢時,通過創建覆寫索引能夠比較好地提高性能,可以通過覆寫索引加子查詢形式進行優化,
如:
explain select from tb_ sku t,(select id from tb_ _sku order by id limit 2000000,10) a wheret.id = a.id;
六、count 優化
explain select count(*) from tb user ;
MyISAM 引擎把一個表的總行數存在了磁盤上,因此執行count(*)的時候會直接回傳這個數,效率很高;
InnoDB 引擎就麻煩了,它執行count(*)的時候,需要把資料一-行一行地從引擎里面讀出來,然后累積計數,
優化思路:自己計數,可以配合redis
count的幾種用法
count()是一個聚合函式,對于回傳的結果集,一行行地判斷, 如果count函式的引數不是NULL,累計值就加1,否則不加,最后回傳累計值,
用法: count (*)、count (主鍵)、count (欄位)、count (1),
count(主鍵)
InnoDB引擎會遍歷整張表,把每一行的主鍵id值都取出來,回傳給服務層,服務層拿到主鍵后,直接按行進行累加(主鍵不可能為null),
count(欄位)
沒有not null約束: InnoDB引擎會遍歷整張表把每一行的欄位值都取出來, 回傳給服務層,服務層判斷是否為null,不為null,計數累加,
有not null約束: InnoDB引擎會遍歷整張表把每一行的欄位值都取出來, 回傳給服務層,直接按行進行累加,
count(1)
InnoDB引擎遍歷整張表,但不取值,服務層對于回傳的每一行,放一個數字"1" 進去,直接按行進行累加,
count(*)
InnoDB引擎并不會把全部欄位取出來,而是專門做了優化,不取值,服務層直接按行進行累加,
按照效率排序的話,count(欄位) < count(主鍵id) < count(1)≈count(*),所以盡量使用count(*),
七、update優化
InnoDB的行鎖是針對索引加的鎖,不是針對記錄加的鎖,并且該索引不能失效,否則會從行鎖升級為表鎖,所以在使用update操作時,更新的條件最好要有索引,否則導致行鎖升級為表鎖,并發性能降低,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/440470.html
標籤:其他